Web Scraping using Python Scrapy_BS4 - using Scrapy and Python(2)
2024-10-09 08:35:46
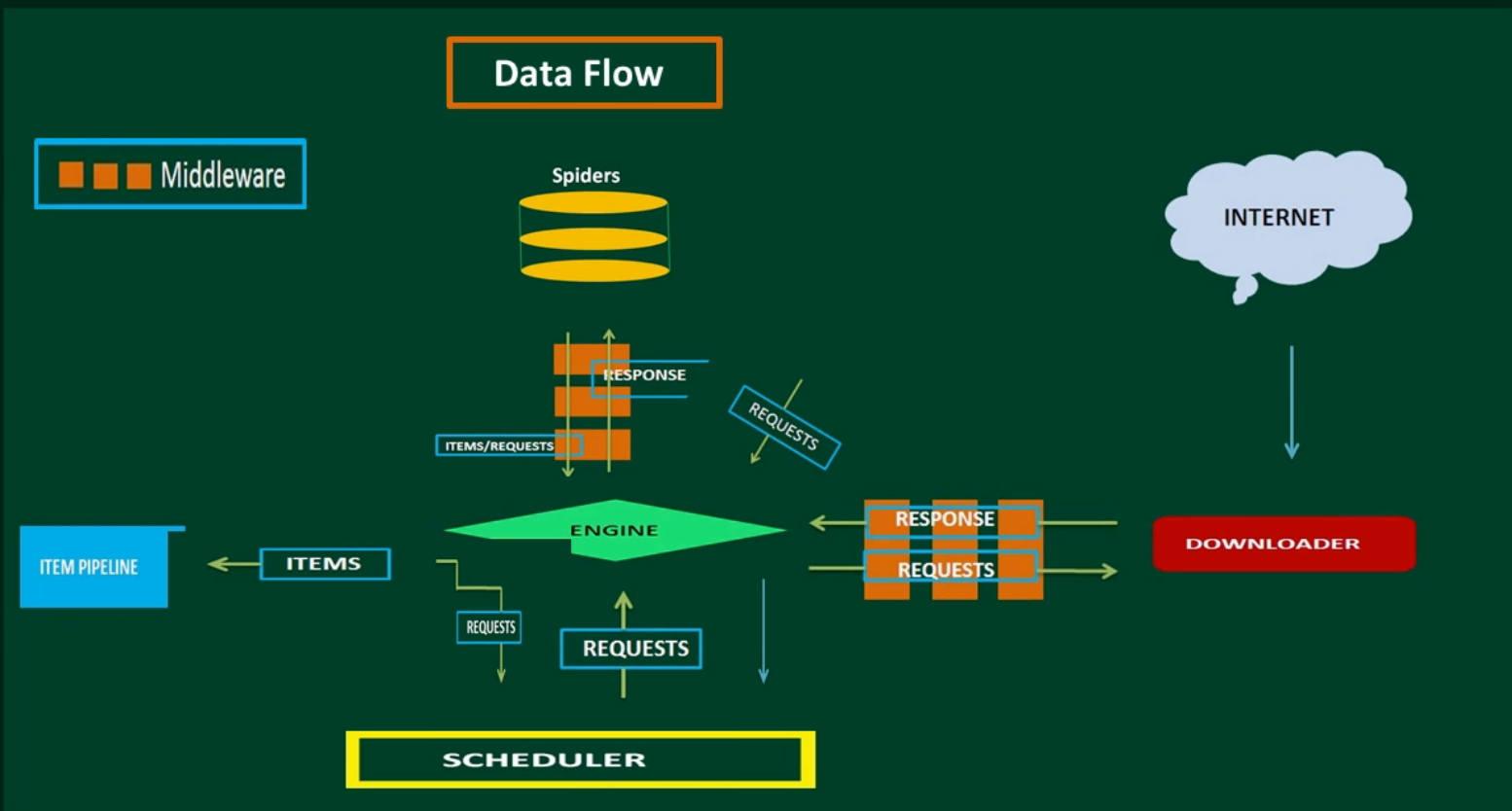
Scrapy Architecture
Creating a Spider.
Spiders are classes that you define that Scrapy uses to scrape(extract) information from a website(s).
import scrapy class QuoteSpider(scrapy.Spider):
name = "quote"
start_urls = [
'https://bluelimelearning.github.io/my-fav-quotes/'
] def parse(self, response):
for quote in response.css('div.quotes'):
yield{
'quote':quote.css('p.aquote::text').extract(),
'author':quote.css('p.author::text').extract_first(),
}

Running your spider and saving scrapped data.
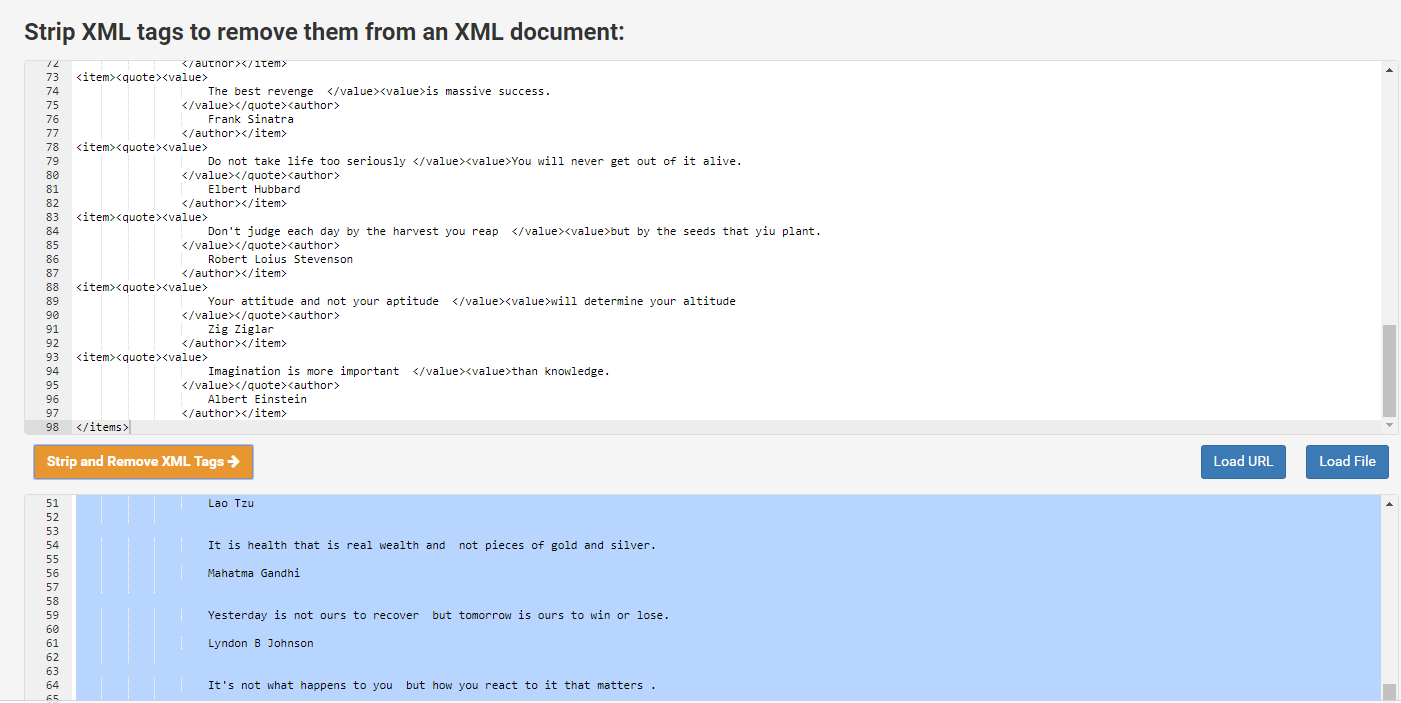
scrapy runspider quotes_spiders.py -o quotes.xml


https://www.cleancss.com/strip-xml/
Scraping data with Scrapy Shell
scrapy shell "https://bluelimelearning.github.io/my-fav-quotes/"

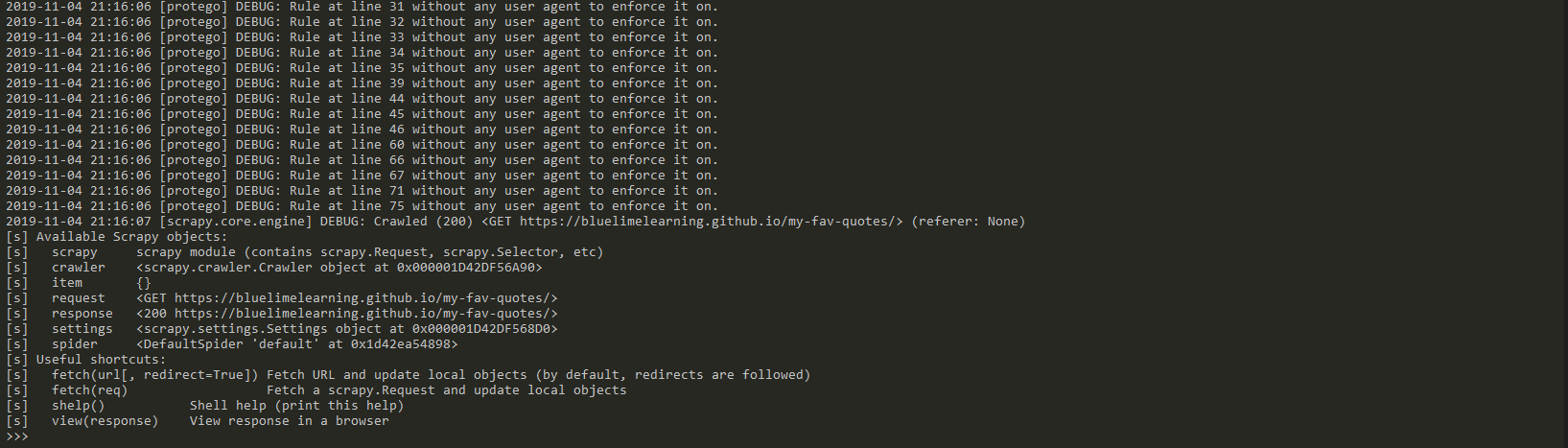
response.css('title')

response.css('title::text').extract()

response.css('h1::text').extract()

quote = response.css("div.quotes")[]
aquote = quote.css("p.aquote::text").extract()
aquote

最新文章
- Ibator的配置和使用
- QT QString 很全的使用 (转)
- selenium--环境搭建步骤
- HTML5中表单的创建
- SqlSever基础 union 将得到的横表变为纵表
- Linux高级使用功能
- CSS3 transition规范的实际使用经验
- 最新game
- 黑马程序员_static\访问权限\单例模式 大汇总
- 二级横向菜单实现——ListView
- 笔记整理--玩转robots协议
- window.close()方法对谷歌和火狐浏览器无效
- scrapy meta信息丢失
- 项目设计day1
- 一个简单的Code First建立
- iOS - 国内注册境外 Apple id 账号
- 在Kubernetes集群中安装Helm及证书认证
- Win10系列:UWP界面布局基础7
- Evolution(矩阵快速幂)zoj2853
- Python配置tab自动补全功能