Spark分区数、task数目、core数目、worker节点数目、executor数目梳理
Spark分区数、task数目、core数目、worker节点数目、executor数目梳理
spark隐式创建由操作组成的逻辑上的有向无环图。驱动器执行时,它会把这个逻辑图转换为物理执行计划,然后将逻辑计划转换为一系列的步骤(stage),每个步骤由多个任务组成。
步骤组成任务、数据组成任务。所以数据和对数据的操作都封装在任务里面了?数据是分布的,那么步骤的执行是什么过程?因为是流水线操作,所以对于每一个工作节点,都有一份步骤,然后根据步骤一步步计算???
Spark文档中使用驱动器节点和执行器节点的概念来描述执行Spark的进程
主节点(master)和工作节点(worker)的概念被用来分别表述集群管理器中的中心化部分和分布式部分。
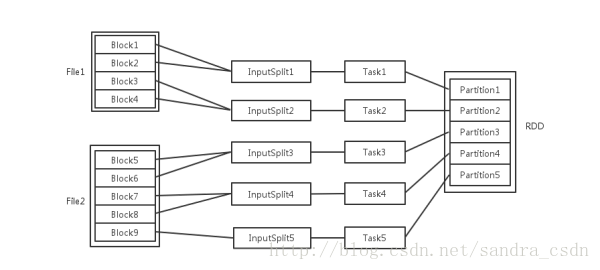
输入以多个文件的形式存储在HDFS上,每个File都包含了很多块,成为Block
如果输入只有一个文件存储在Hbase里,也是按块大小分布存储的吗?
以块形式存储的文件可以跨节点嘛?
Spark读取文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并为一个输入分片,成为InputSplit。InputSplit不能跨文件。
随后为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Ececutor去执行
- 每个节点可以起一个或多个Executor
executor就是执行器节点嘛?所以每个工作节点(主机)可以有多个执行器?
- 每个Executor由若干个core组成,每个Executor的每个core(虚拟core,可以理解为一个Executor的工作线程)一次只能执行一个Task
- 每个Task执行的结果就是生产了目标RDD的一个partition
Task执行的并发度 = Executor的个数 * Executor的核数
partition的数目:
- 数据读入阶段。例如sc.textFile,输入文件划分为多少个InputSpliter就会需要多少的初始Task
- Map阶段partition不变
- Reduce阶段,RDD会触发shuffle操作,聚合后的RDD的partition数目根具体的操作有关
RDD在计算的时候,每一个分区都会起一个Task,所以RDD的分区数目决定了总的Task数目
比如RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。
如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。
如果资源不变,你的RDD只有2个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大任务并行度的做法。
Spark的Driver、Job和Stage
csdn jwLee
例子说明
在这个例子中,假设你需要做如下一些事情:
- 将一个包含人名和地址的文件加载到RDD1中
- 将一个包含人名和电话的文件加载到RDD2中
- 通过name来Join RDD1和RDD2,生成RDD3
- 在RDD3上做Map,给每个人生成一个HTML展示卡作为RDD4
- 将RDD4保存到文件
- 在RDD1上做Map,从每个地址中提取邮编,结果生成RDD5
- 在RDD5上做聚合,计算出每个邮编地区中生活的人数,结果生成RDD6
- Collect RDD6,并且将这些统计结果输出到stdout
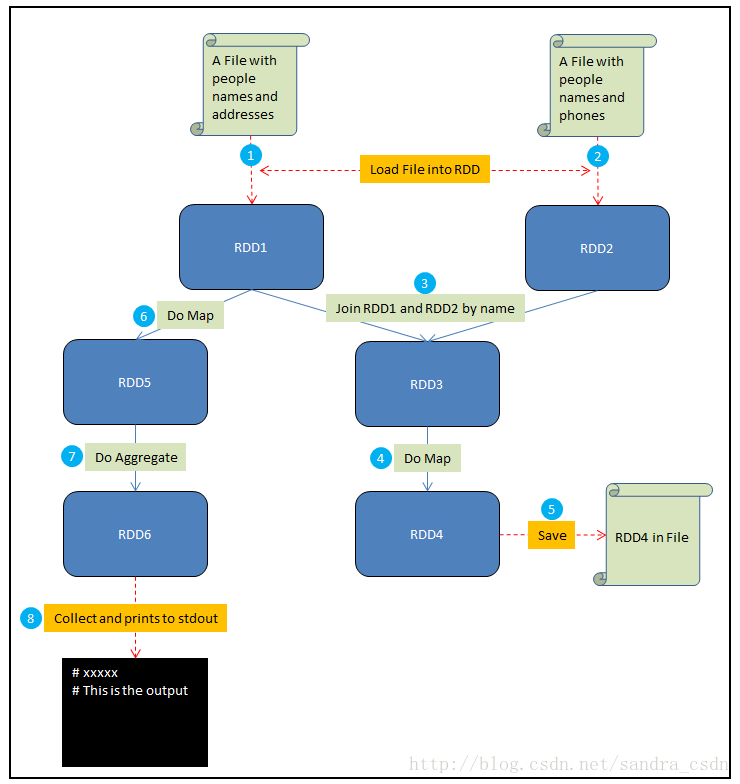
其中红色虚线表示输入和输出,蓝色实线是对RDD的操作,圆圈中的数字对应了以上的8个步骤。接下来解释driver program, job和stage这几个概念:
- Driver program是全部的代码,运行所有的8个步骤。
- 第五步中的save和第八步中的collect都是Spark Job。Spark中每个action对应着一个Job,transformation不是Job。
- 其他的步骤(1、2、3、4、6、7)被Spark组织成stages,每个job则是一些stage序列的结果。对于一些简单的场景,一个job可以只有一个stage。但是对于数据重分区的需求(比如第三步中的join),或者任何破坏数据局域性的事件,通常会导致更多的stage。可以将stage看作是能够产生中间结果的计算。这种计算可以被持久化,比如可以把RDD1持久化来避免重复计算。
- 以上全部三个概念解释了某个算法被拆分的逻辑。相比之下,task是一个特定的数据片段,在给定的executor上,它可以跨越某个特定的stage。
到了这里,很多概念就清楚了。驱动程序就是执行了一个Spark Application的main函数和创建Spark Context的进程,它包含了这个application的全部代码。Spark Application中的每个action会被Spark作为Job进行调度。每个Job是一个计算序列的最终结果,而这个序列中能够产生中间结果的计算就是一个stage。
通常Action对应了Job,而Transformation对应了Stage
官方解释如下(http://spark.apache.org/docs/latest/cluster-overview.html):
Driver Program: The process running the main() function of the application and creating the SparkContext.
Job: A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs.
Stage: Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs.
一个Job被拆分成若干个Stage,每个Stage执行一些计算,产生一些中间结果。它们的目的是最终生成这个Job的计算结果。而每个Stage是一个task set,包含若干个task。Task是Spark中最小的工作单元,在一个executor上完成一个特定的事情。
最新文章
- linux centos 6.5下安装nodejs
- iOS开发学习笔记
- Self Host模式下的ASP. NET Web API是如何进行请求的监听与处理的?
- 用浏览器模拟各种User Agent
- 【架构】Google的大规模集群管理工具Borg
- CSS3中媒体查询,更换样式表
- [题解]hdu 1009 FatMouse' Trade(贪心基础题)
- 解决pageControl页面设置无效问题
- POJ Code the Tree 树的pufer编号
- Qt学习之系列[9] – QCoreApplication:processEvents()可能会引起递归,导致栈溢出崩溃
- 老李分享:为何要使用 Web Services
- beetl模板引擎使用笔记
- Java中RuntimeException和Exception的区别
- IDEA导入Git项目后右键项目找不到Git选项的解决方法
- Unity接入Steamworks
- scss、less 对浏览器兼容的处理方法, css 的单行溢出、多行溢出
- 20172319 《Java程序设计教程》第7周学习总结
- OSGi 系列(六)之服务的使用
- 4.three.js中的坐标系
- 《Spring1之第九次站立会议》