爬虫简介与requests模块
爬虫简介与requests模块
一 爬虫简介
概述
网络爬虫是一种按照一定规则,通过网页的链接地址来寻找网页的,从网站某一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止
爬虫的价值
互联网中最有价值的便是数据
robots.txt
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。
爬虫流程
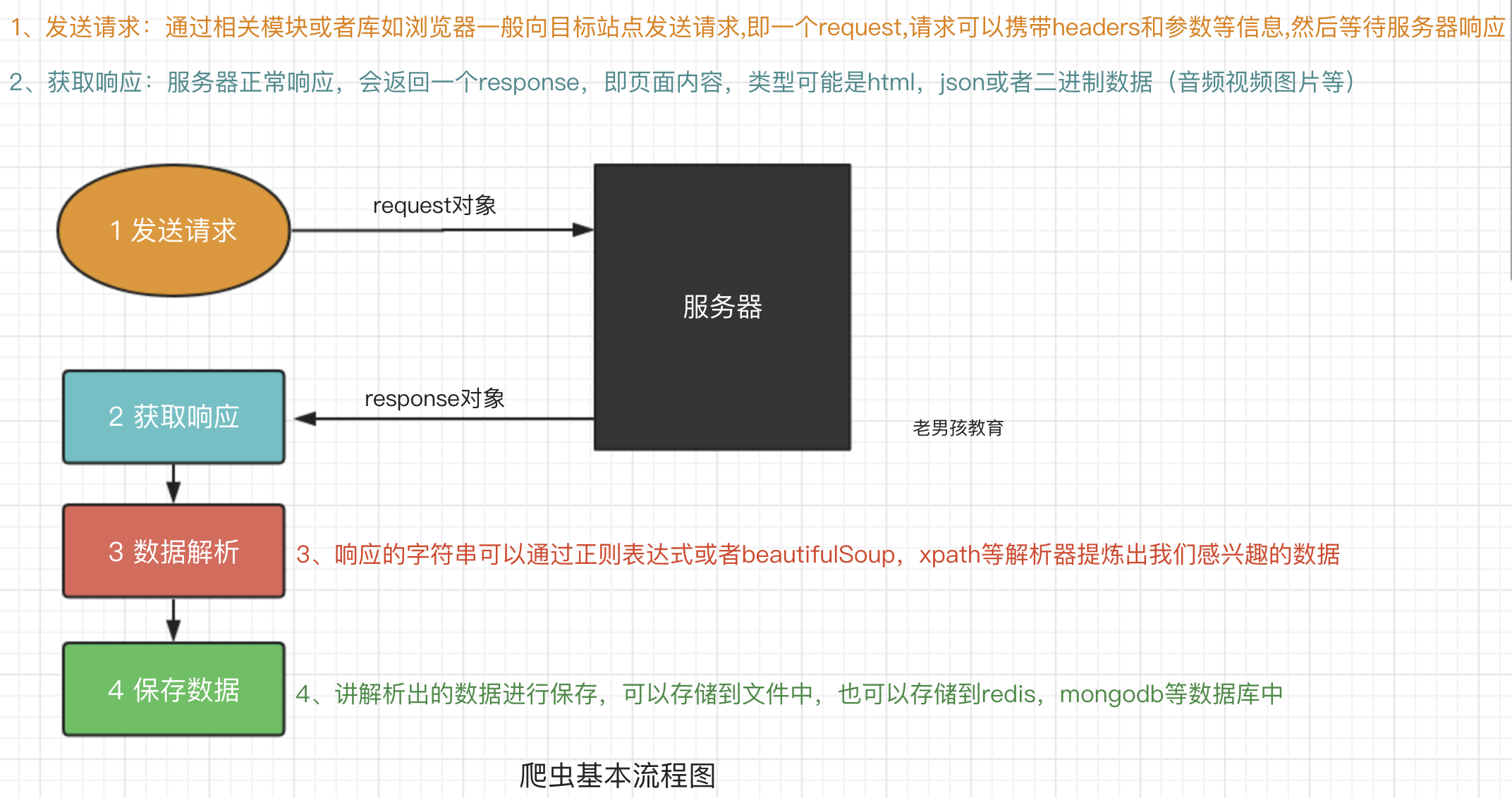
预备知识
requests模块
Requests是用Python语言基于urllib编写的,采用Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,可以节约我们大量的工作,一句话,requests是python实现的最简单易用的HTTP库,建议爬虫使用requests库,默认安装python后,使用pip install requests 安装
requests模块支持的请求
import requests
requests.get("http://httpbin.org/get")
requests.post("http://httpbin.org/post")
requests.put("http://httpbin.org/put")
requests.delete("http://httpbin.org/delete")
requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
get请求
基本请求
import requests
response = requests.get('https://www.baidu.com/')
with open('baidu.html','wb') as f:
f.write(response.conten)
含有参数请求
import requests
response = requests(url='https://s.taoba.com/search?q='手机')
response=requests.get('https://s.taobao.com/search',params={"q":"美女"})
# params 后面的参数是淘宝搜索的参数,
如果页面不跳转,说明淘宝添加了反爬机制,需要在请求头添加下列参数
含有请求头请求
import requests
response = requests.get(url='https://www.baidu.com/s', params={'wd':'夏雨豪'},
headers={
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
})
with open('sousuo.html', 'wb') as f2:
f2.write(response.content)
print('写入完毕')
# User-Agent 在页面中

含有cookis请求
import uuid
import requests
url = 'http://httpbin.org/cookies' # 这是一个开发测试的网址,专门为了测试发送请求的
cookies = dict(sid=str(uuid.uuid4()))
res = requests.get(url=url, cookies=cookies)
print(res.text)
post请求
post请求中与get用法一致,特殊的是requests.post()多了一个参数data,用来存储数据的.
import requests
response = requests.post('http://httpbin.org/post', params={"a":"10"}, data={'name':'ling'})
print(response.text)
发送json数据
import requests
rest1 = requests.post(url='http://httpbin.org/post',{'name':'ling'}) #没有指定请求头,#默认的请求头:application/x-www-form-urlencoed
print(rest1.json())
# 'Content-Type': 'application/x-www-form-urlencoded'
rest2 = requests.post(url='http://httpbin.org/post',json={'age':"22",}) #默认的请求头:application/json
print(rest2.json)
注意: 请求数据的类型conten-type的类型是urlencoded,只有指定类型content-type类型之后才会发生变化,类型的不同则说明了解码的方式不同,
response对象,获取返回信息
常见属性
import requests response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印响应状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
print(response.status_code) # HTTP请求的返回状态
print(response.cookies.get_dict()) # 以字典的形式返回cookies的信息
print(response.cookies.items()) # 与dict的items方法一样
print(response.encoding()) # 返回对象的编码方式
print(response.history()) # 与重定向有关
关于重定向
有时候我们在请求url时,服务器会自动把我们的请求重定向,比如github会把我们的http请求重定向为https请求。我们可以使用r.history来查看重定向:
print(response.history())
我们使用http协议访问,结果在r.url中,打印的却是https协议。那如果我非要服务器使用http协议,也就是禁止服务器自动重定向,使用allow_redirects 参数:
r = requests.get('http://baidu.com', allow_redirects=False)
关于cookies
如果一个响应包含cookies的话,我们可以使用下面方法来得到它们:
r = requests.get('http://www.baidu.com')
print(r.cookies)
也可以发送自己的cookie(使用cookies关键字参数)
cookies = {'cookies_are':'working'}
r = requests.get('http://www.baidu.com',cookies=cookies)
关于代理
我们也可以在程序中指定代理来进行http或https访问(使用proxies关键字参数),
proxies = {
'http': 'http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
} requests.get("http://baidu.com", proxies=proxies)
关于session
有时候会有这样的情况,我们需要登录某个网站,然后才能请求相关url,这时就可以用到session了,我们可以先使用网站的登录api进行登录,然后得到session,最后就可以用这个session来请求其他url了:
s=requests.Session()
login_data={``'form_email'``:``'youremail@example.com'``,``'form_password'``:``'yourpassword'``}
s.post(``"http://baidu.com/testLogin"``,login_data)
r = s.get(``'http://baidu.com/notification/'``)
print r.text
其中,form_email和form_password是豆瓣登录框的相应元素的name值
实例
使用requests+re+process来爬取豆瓣,
import requests
import re
import json
from multiprocessing import Process
import time def get_page(url):
"""
发送请求,获取数据
:param url:
:return:
"""
response = requests.get(url)
return response def parser(res):
"""
解析数据
:param res:
:return:
"""
reg = re.compile(
'<div class="item">.*?<a href="(?P<url>.*?)">.*?<span class="title">(?P<title>.*?)'
'</span>.*?<span class="rating_num".*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)人评价</span>',
re.S)
ret_iter = reg.finditer(res.text)
return ret_iter def store(ret_iter):
"""
存储数据
:param ret_iter:
:return:
"""
lis = []
for i in ret_iter:
dic = {}
dic['url'] = i.group('url')
dic['title'] = i.group('title')
dic['rating_num'] = i.group('rating_num')
dic['comment_num'] = i.group('comment_num')
lis.append(dic)
with open('douban_re.txt', 'a', encoding='utf8') as f:
for i in lis:
f.write(json.dumps(i, ensure_ascii=False) + '\n') def spider_movie(url):
res = get_page(url)
ret_iter = parser(res)
store(ret_iter) if __name__ == '__main__':
start = time.time()
p_list = []
for i in range(10):
url = "https://movie.douban.com/top250?start=%s&filter=" % i * 25
p = Process(target=spider_movie, args=(url,))
p.start()
p_list.append(p)
for i in p_list:
i.join()
print(time.time() - start)githup页面,模拟登录,爬取登录页面
import requests
import re # 第一步: 请求获取token,以便通过post请求校验
# session=requests.session()
res = requests.get("https://github.com/login") authenticity_token = re.findall('name="authenticity_token" value="(.*?)"', res.text)[0]
print(authenticity_token) # 第二步 构建post请求数据 data = {
"login": "yuanchenqi0316@163.com",
"password": "yuanchenqi0316",
"commit": "Sign in",
"utf8": "✓",
"authenticity_token": authenticity_token
} headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36" } res = requests.post("https://github.com/session", data=data, headers=headers, cookies=res.cookies.get_dict()) with open("github.html", "wb") as f:
f.write(res.content)
最新文章
- gedit 乱码问题
- linux驱动中printk的使用注意事项
- .NET通过RFC读取SAP数据
- [TypeScript] 建置输出单一JavaScript档案(.js)与Declaration档案(.d.ts)
- 取消StringGrid的自动滚动
- linux 常用alias
- hdu 1709 The Balance
- GimageX
- C++学习笔记7——模板
- POJ 3254 炮兵阵地(状态压缩DP)
- 产生冠军(set,map,拓扑结构三种方法)
- swt combo 自动补全
- Qt中所有类型之间的转换
- Web自动化之Headless Chrome概览
- 搭建zookeeper+kafka集群
- oracle 新增并返回新增的主键
- HTML5实现图片预览功能
- MySql 链接字符串
- 封装用于解析NSDate的便利的类
- Python脚本报错AttributeError: 'module' object has no attribute 'maketrans'