Scrapy的流程
Scrapy框架的架构如下图
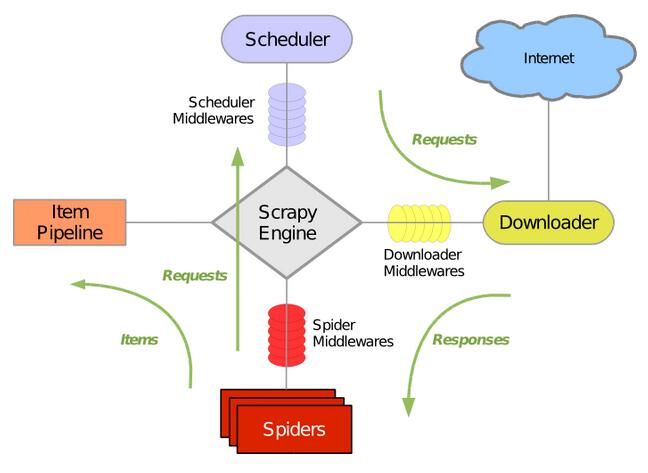
具体部分说明:
Engine:引擎,处理整个系统的数据流处理,出发事物,是整个框架的核心
Item:项目。定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象
Scheduler:调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎
Downloader:下载器,下载网页的内容,并将网页的内容返回给蜘蛛
Spiders:蜘蛛,其内定义了爬去的逻辑和网页解析的规则,它主要负责解析响应并生成提取的结果和新的请求
Item Pipeline:项目管道,负责处理由蜘蛛从页面中抽取的项目,它主要的任务是清洗,验证和存储数据
Downloader Middlewares :下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求以及响应
Spider Middlewardes: 蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛的输入的响应和输出的结果及洗呢请求
数据流:
Scrapy的数据流由引擎控制,数据流的过程如下:
1.Engine首先打开一个网站,找到处理该网站的Spider,并向该网站的Spider请求的一个要爬取的URL
2.Engine从Spider中获取到第一个要爬取的URL,并通过Scheduler以Request的形式调度
3.Engine向Spider请求下一个要爬取的URL
4.Scheduler返回下个要爬取的URL给Engine,Engine将URL通过Downloader Middlewares转发个Downloader下载
5.一旦下载完毕,Downloader生成该页面的Response,并将其通过Downloader Middlewares发送给Engine
6.Engine从下载器中接收到Response,并将其通过Spider Middlewares发送给Spider处理
7.Spider处理Response,并返回取到的Item及新得Request返回给Engine
8.Engine将Spider返回的Item给Item Pipeline,将新得Request给Schedule
9.重复第2步到底8步,直到Schedule找那个没有更多的Request。Engine关闭网站,爬取结束
下面着重说一下Downloader Middlewares与Spider Middlewares
Downloader Middlewares
作用:
1.在Scheduler调出队列的Request发送给Downloader下载之前,也就是我们可以再Request执行下载之前对其进行修改
2.在下载后生成Response发送给Spider之前,也就是我们可以再生成Response被Spider解析之前对其进行修改
Downloader Middlewares的功能十分的强大,修改User-Agent,处理重定向、设置代理、失败重试、设置Cookies等功能都需要借助他来实现
核心方法:
1.process_request(request,spider) :Request被Scrapy引擎调度给Downloader之前,process_request()会被执行,方法返回的是None、Response对象、Request对象之一。参数:request是Request对象,即被处理的Request;spider,Spider对象,即此Request对应的Spider
2.process_response(request,response,spider) :Downloader执行Request下载之后,会得到对应的Response。Scrapy引擎便会将Response发送给Spider进行解析,返回值必须是Request对象、Response对象之一。参数:request,是Request对象,即此Response对应的Request;response:是response对象,即被处理的Response;spider:是Spider对象,即此被处理的Spider对象
3.process_exception(request,exception,spider):当Downloader或者process_requset()方法抛出异常时,此方法就会被调用。返回值必须是None,Response对象,Request对象之一。参数:request,是Request对象;exception,是Exception对象,即抛出的异常;spider,Spider对象,即此Request对应的Spider
Spider Middlewares
当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过Spider Middlewares处理,当Spider生成处理后的Item和Request之后,Item和Request还会经过Spider MIddlewares处理
作用:
1.我们可以在Downloader生成Response发送给Spider之前,也就是Response发送给Spider之前对Response进行处理
2.我们可以在Spider生成Request发送给Scheduler之前,也就是在Request发送给Scheduler之前对Request进行处理
3.我们可以在Spider生成Item发送给Item Pipeline之前,也就是在Item发送给Scheduler之前对Item Pipeline进行处理
核心方法:
1.process_spider_input(reponse,spider):当Response被Spider Middlewares处理时,此方法会被调用;返回值是None或者是抛出一个异常
参数:response,是Response对象,即被处理的Response;spider,是Spider对象,即该Response对应的此Spider
2.process_spider_output(response,result,spider):当Spider处理Respon返回结果时,此方法会被调用;返回值必须是包含Request或Item的可迭代对象
参数:response,是Response对象,即被处理的Response;result,是包含Request或Item的可迭代对象;spider,是Spider对象,即该Response对应的此Spider
3.process_spider_exception(response,excsption,spider):当Spider或process_spider_input方法抛出异常时,此方法会执行;返回值为None或者包含Request或Item的可迭代对象; 参数:response,是Response对象,即被处理的Response;exception,是Exception对象,即抛出的异常;spider,Spider对象,即此Response对应的Spider
4.pricess_spider_requests(start_requests,spider):以Spider启动Request为参数时调用,执行过程类似于process_spider_output(),只不过没有相关联的Response,并且必须返回Request。 参数:start_requests,是包含Request的可迭代对象,即Start_Request;spider,Spider对象,即此Start_Request所属的Spider
未完待续。。。。。。。。
最新文章
- react 犯错
- python unicode字节串转成中文问题
- 【MSDN原版】Windows 7 with SP1各版本下载
- 局域网电脑Sql2008 R2无法连接到localhost 解决方案
- POJ2407 Relatives(欧拉函数)
- 鼠标选择文字事件js代码,增加层问题
- Linux下通过ODBC连接sqlserver
- 最常用的动态sql语句梳理——分享给使用Mybatis的小伙伴们!
- 清除mac上安装软件的用户信息
- java与数据库
- git 版本控制的简单应用
- 2018上C语言程序设计(高级)博客作业样例
- 关于:target与定位动画的奇怪现象
- ubuntu linux 安装分区
- vue 倒计时组件
- 浏览器保存数据给app读取
- 二、Python发展始
- PHPExcel-设置表格字体颜色背景样式、数据格式、对齐方式、添加图片、批注、文字块、合并拆分单元格、单元格密码保护
- O2O、C2C、B2B、B2C
- HOJ-2662Pieces Assignment(状态压缩,动态规划)