推荐算法-聚类-DBSCAN
2024-08-29 03:47:57
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,类似于均值转移聚类算法,但它有几个显著的优点。
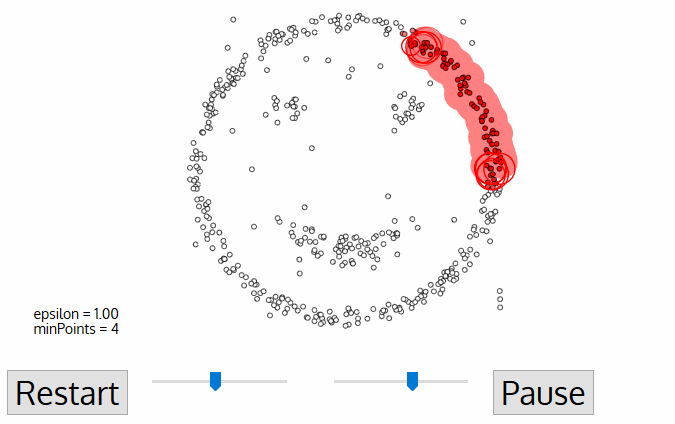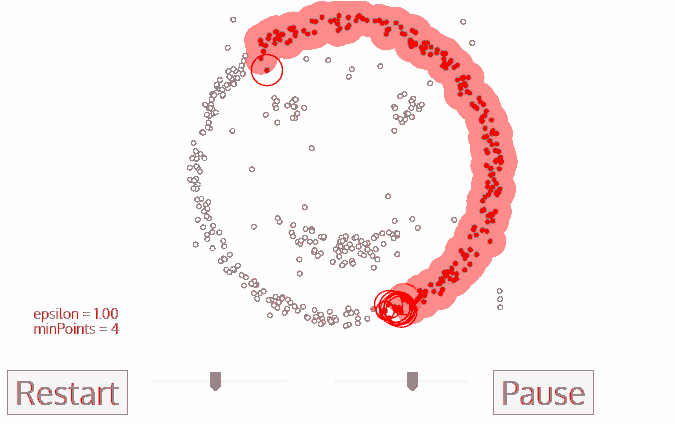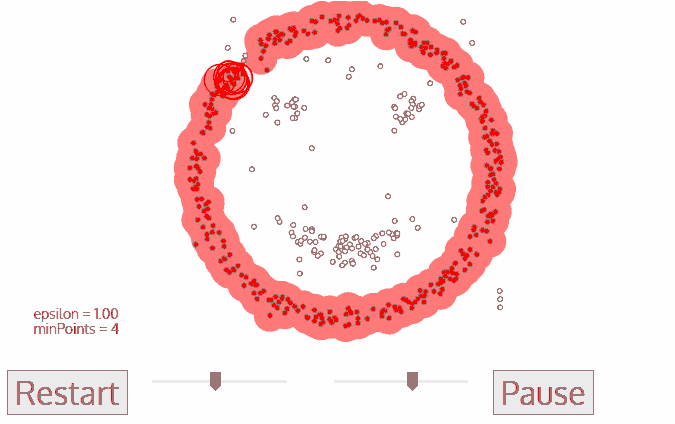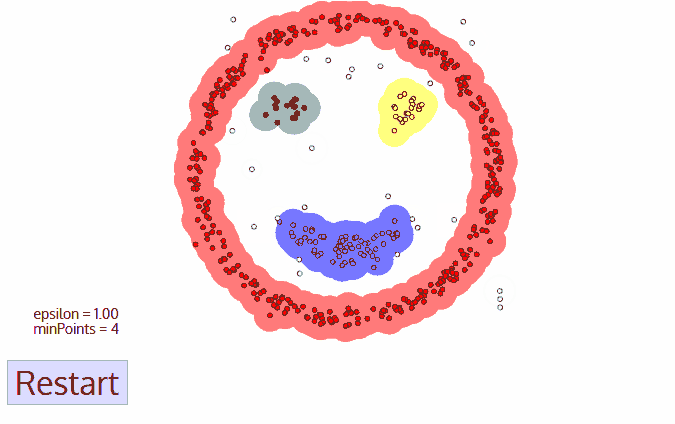
- DBSCAN以一个从未访问过的任意起始数据点开始。这个点的领域是用距离ε(所有在ε的点都是邻点)来提取的。
- 如果在这个邻域中有足够数量的点(根据minPoints),那么聚类过程就开始了,并且当前的数据点成为新聚类中的第一个点。否则,该点将被标记为噪声(稍后这个噪声点可能会成为聚类的一部分)。在这两种情况下,这一点都被标记为(visited)。
- 对于新聚类中的第一个点,其ε距离附近的店也会成为同意了聚类的一部分。这一过程在ε临近的所有点都属于同一个聚类,然后重复所有刚刚添加到聚类组的新点。
- 步骤2和步骤3的过程将重复,直到所有点都被确定,就是说在聚类附近的所有点都已被访问和标记。
- 一旦我们完成了当前的聚类,就会检索并处理一个新的未访问点,这将导致进一步的聚类或噪声的发现。这个过程不断地重读,直到所有的点被标记为访问。因为在所有的点都被访问过之后,每一个点都被标记为属于一个聚类或者是噪声。
DBSCAN的主要缺点是,当聚类具有不同的密度时,它的性能不像其他聚类算法那样好。这是因为当密度变化时,距离阈值ε和识别临近点的minPoints的设置会随着聚类的不同而变化。这种缺点也会出现在非常高纬的数据中心,因为距离阈值ε变得难以估计。
最新文章
- 【集合框架】JDK1.8源码分析之Collections && Arrays(十)
- PL/SQL重新编译包无反应
- 自己动手写插件底层篇—基于jquery移动插件实现
- PHP加载另一个文件类的方法
- Visual Studio 2013小技巧
- js 判断微信浏览器
- Java基础-字面值
- [NOIP2011] 普及组
- bzoj1021 [SHOI2008]Debt 循环的债务
- css3实现超过两行文字,超出用三个点显示(兼容性不行,仅供学习)
- 【转】beancopy的替代方案
- Sass之初识
- 使用WIF实现单点登录Part I——Windows Identity Foundation介绍及环境搭建 -摘自网络
- Why I donot give up cnblogs for Jianshu
- Typescript学习
- Qt之QComboBox定制(二)
- VS2015 IIS Express Web服务器无法启动解决办法
- 加NONCLUSTERED INDEX索引,在ON了之后还要INCLUDE
- lumisoft.net 邮件管理系列文章 - 如何判断附件为内嵌式还是附加式
- UVa 11491 Erasing and Winning (贪心,单调队列或暴力)