【原创】MapReduce实战(一)
应用场景:
用户每天会在网站上产生各种各样的行为,比如浏览网页,下单等,这种行为会被网站记录下来,形成用户行为日志,并存储在hdfs上。格式如下:
17:03:35.012ᄑpageviewᄑ{"device_id":"4405c39e85274857bbef58e013a08859","user_id":"0921528165741295","ip":"61.53.69.195","session_id":"9d6dc377216249e4a8f33a44eef7576d","req_url":"http://www.bigdataclass.com/product/1527235438747427"}
这是一个类Json 的非结构化数据,主要内容是用户访问网站留下的数据,该文本有device_id,user_id,ip,session_id,req_url等属性,前面还有17:03:20.586ᄑpageviewᄑ,这些非结构化的数据,我们想把该文本通过mr程序处理成被数仓所能读取的格式,比如Json串形式输出,具体形式如下:
{"time_log":1527584600586,"device_id":"4405c39e85274857bbef58e013a08859","user_id":"0921528165741295","active_name":"pageview","ip":"61.53.69.195","session_id":"9d6dc377216249e4a8f33a44eef7576d","req_url":"http://www.bigdataclass.com/my/0921528165741295"}
代码工具:intellij idea, maven,jdk1.8
操作步骤:
- 配置 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>netease.bigdata.course</groupId>
<artifactId>etl</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.4</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>
jar-with-dependencies
</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin> </plugins>
</build> </project>
2.编写主类这里为了简化代码量,我将方法类和执行类都写在ParseLogJob.java类中
package com.bigdata.etl.job; import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat; public class ParseLogJob extends Configured implements Tool {
//日志解析函数 (输入每一行的值)
public static Text parseLog(String row) throws ParseException {
String[] logPart = StringUtils.split(row, "\u1111");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long timeLog = dateFormat.parse(logPart[0]).getTime();
String activeName = logPart[1];
JSONObject bizData=JSONObject.parseObject(logPart[2]);
JSONObject logData = new JSONObject(); logData.put("active_name",activeName);
logData.put("time_log",timeLog);
logData.putAll(bizData);
return new Text(logData.toJSONString());
} //输入key类型,输入value类型,输出。。(序列化类型)
public static class LogMapper extends Mapper<LongWritable,Text,NullWritable,Text>{
//输入key值 输入value值 map运行的上下文变量
public void map(LongWritable key ,Text value ,Context context) throws IOException,InterruptedException{
try {
Text parseLog = parseLog(value.toString());
context.write(null,parseLog);
} catch (ParseException e) {
e.printStackTrace();
} }
} public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration config = getConf();
Job job= Job.getInstance(config);
job.setJarByClass(ParseLogJob.class);
job.setJobName("parseLog");
job.setMapperClass(LogMapper.class);
//设置reduce 为0
job.setNumReduceTasks(0);
//命令行第一个参数作为输入路径
FileInputFormat.addInputPath(job,new Path(args[0]));
//第二个参数 输出路径
Path outPutPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job,outPutPath);
//防止报错 删除输出路径
FileSystem fs = FileSystem.get(config);
if (fs.exists(outPutPath)){
fs.delete(outPutPath,true);
}
if (!job.waitForCompletion(true)){
throw new RuntimeException(job.getJobName()+"fail");
}
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new ParseLogJob(), args);
System.exit(res);
}
}
3.打包上传到服务器
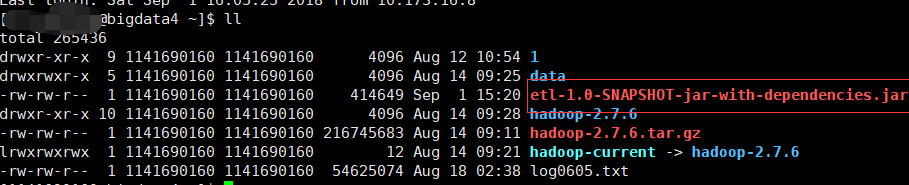
4.执行程序
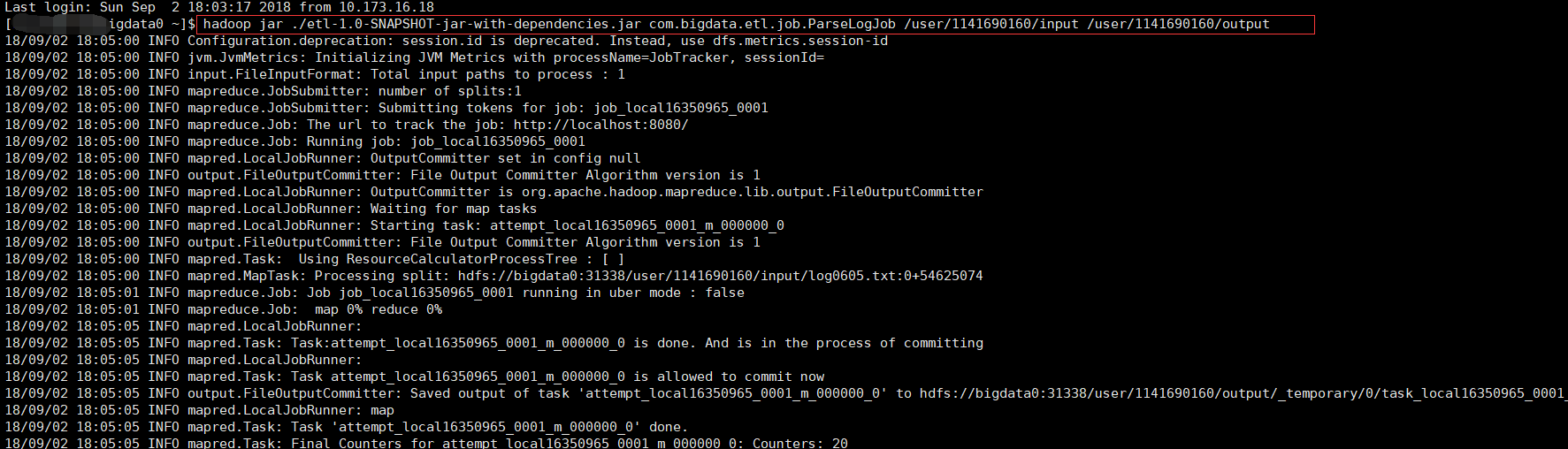
我们在hdfs 中创建了input和output做为输入输出路径
hadoop jar ./etl-1.0-SNAPSHOT-jar-with-dependencies.jar com.bigdata.etl.job.ParseLogJob /user/1141690160/input /user/1141690160/output
程序已经map完,因为我们没有对reduce进行操作,所以reduce为0
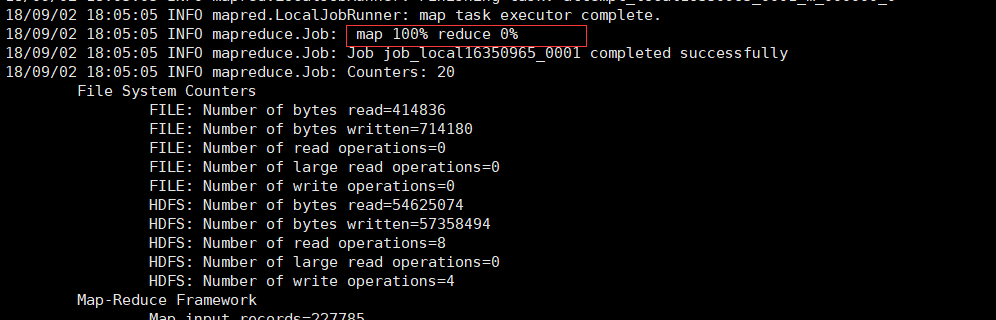
去hdfs 查看一下我们map完的文件

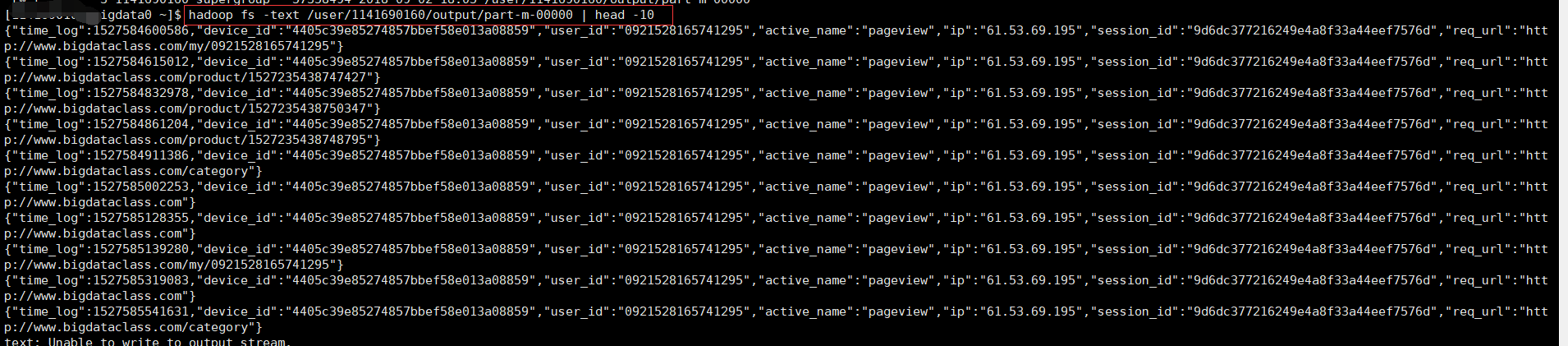
至此,一个简单的mr程序跑完了。
最新文章
- android SystemServer.java启动的服务。
- java学习笔记之泛型
- Zabbix监控mysql主从复制状态
- 配置BUG-Linux系统下ssh登陆很慢的解决办法
- JavaScript学习笔记-自定义滚动条
- C++变量对比java变量所占内存
- Mac系统安装jdk和maven
- Pylot压力测试(linux)
- Svn服务器的安装和配置
- 好玩的WPF第二弹:电子表字体显示时间+多彩呼吸灯特效button
- 编写高质量的JavaScript代码(一)
- 通过type类型 新建对象
- Mac下显示网页全屏快捷键
- 来自Composer中文网安装composer指南
- 富文本之BootStrap-wysiwyg 带图片上传功能
- opencv获取IP摄像头(IP-camera)实时视频流
- 数据库入门4 结构化查询语言SQL
- UVa 11584 - Partitioning by Palindromes(线性DP + 预处理)
- inux下安装ab
- Maven错误之 Check $M2_HOME environment variable