C++对象模型6--对象模型对数据访问的影响
如何访问成员?
前面介绍了C++对象模型,下面介绍C++对象模型的对访问成员的影响。其实清楚了C++对象模型,就清楚了成员访问机制。下面分别针对数据成员和函数成员是如何访问到的,给出一个大致介绍。
对象大小问题
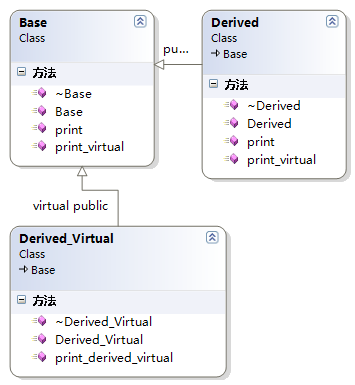
其中:3个类中的函数都是虚函数
l Derived继承Base
l Derived_Virtual虚继承Base
void test_size()
{
Base b;
Derived d;
Derived_Virtual dv;
cout << "sizeof(b):\t" << sizeof(b) << endl;
cout << "sizeof(d):\t" << sizeof(d) << endl;
cout << "sizeof(dv):\t" << sizeof(dv) << endl;
}
输出如下:
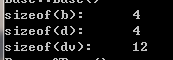
因为Base中包含虚函数表指针,所有size为4;Derived继承Base,只是扩充基类的虚函数表,不会新增虚函数表指针,所以size也是4;Derived_Virtual虚继承Base,根据前面的模型知道,派生类有自己的虚函数表及指针,并且有分隔符(0x00000000),然后才是虚基类的虚函数表等信息,故大小为4+4+4=12。
#pragma once
class Empty
{
public:
Empty(void);
~Empty(void);
};
Empty p,sizeof(p)的大小是多少?事实上并不是空的,它有一个隐晦的1byte,那是被编译器安插进去的一个char。这将使得这个class的两个对象得以在内中有独一无二的地址。
数据成员如何访问(直接取址)
跟实际对象模型相关联,根据对象起始地址+偏移量取得。
静态绑定与动态绑定
程序调用函数时,将使用那个可执行代码块呢?编译器负责回答这个问题。将源代码中的函数调用解析为执行特定的函数代码块被称为函数名绑定(binding,又称联编)。在C语言中,这非常简单,因为每个函数名都对应一个不同的额函数。在C++中,由于函数重载的缘故,这项任务更复杂。编译器必须查看函数参数以及函数名才能确定使用哪个函数。然而编译器可以再编译过程中完成这种绑定,这称为静态绑定(static binding),又称为早期绑定(early binding)。
然而虚函数是这项工作变得更加困难。使用哪一个函数不是能在编译阶段时确定的,因为编译器不知道用户将选择哪种类型。所以,编译器必须能够在程序运行时选择正确的虚函数的代码,这被称为动态绑定(dynamic binding),又称为晚期绑定(late binding)。
使用虚函数是有代价的,在内存和执行速度方面是有一定成本的,包括:
l 每个对象都将增大,增大量为存储虚函数表指针的大小;
l 对于每个类,编译器都创建一个虚函数地址表;
l 对于每个函数调用,都需要执行一项额外的操作,即到虚函数表中查找地址。
虽然非虚函数比虚函数效率稍高,单不具备动态联编能力。
函数成员如何访问(间接取址)
跟实际对象模型相关联,普通函数(nonstatic、static)根据编译、链接的结果直接获取函数地址;如果是虚函数根据对象模型,取出对于虚函数地址,然后在虚函数表中查找函数地址。
多态如何实现?
多态的实现
多态(Polymorphisn)在C++中是通过虚函数实现的。通过前面的模型【参见“有重写的单继承”】知道,如果类中有虚函数,编译器就会自动生成一个虚函数表,对象中包含一个指向虚函数表的指针。能够实现多态的关键在于:虚函数是允许被派生类重写的,在虚函数表中,派生类函数对覆盖(override)基类函数。除此之外,还必须通过指针或引用调用方法才行,将派生类对象赋给基类对象。
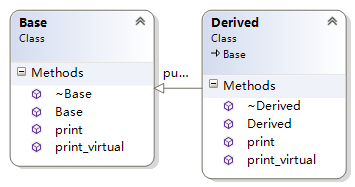
上面2个类,基类Base、派生类Derived中都包含下面2个方法:
void print() const;
virtual void print_virtual() const;
这个2个方法的区别就在于一个是普通成员函数,一个是虚函数。编写测试代码如下:
void test_polmorphisn()
{
Base b;
Derived d; b = d;
b.print();
b.print_virtual(); Base *p;
p = &d;
p->print();
p->print_virtual();
}
根据模型推测只有p->print_virtual()才实现了动态,其他3调用都是调用基类的方法。原因如下:
l b.print();b.print_virtual();不能实现多态是因为通过基类对象调用,而非指针或引用所以不能实现多态。
l p->print();不能实现多态是因为,print函数没有声明为虚函数(virtual),派生类中也定义了print函数只是隐藏了基类的print函数。
为什么析构函数设为虚函数是必要的
析构函数应当都是虚函数,除非明确该类不做基类(不被其他类继承)。基类的析构函数声明为虚函数,这样做是为了确保释放派生对象时,按照正确的顺序调用析构函数。
从前面介绍的C++对象模型可以知道,如果析构函数不定义为虚函数,那么派生类就不会重写基类的析构函数,在有多态行为的时候,派生类的析构函数不会被调用到(有内存泄漏的风险!)。
例如,通过new一个派生类对象,赋给基类指针,然后delete基类指针。
void test_vitual_destructor()
{
Base *p = new Derived();
delete p;
}
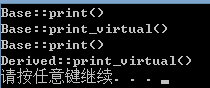
如果基类的析构函数不是虚函数:
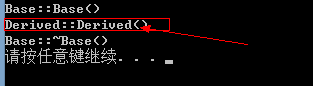
注意,缺少了派生类的析构函数调用。把析构函数声明为虚函数,调用就正常了:

最新文章
- IDEA 中生成 Hibernate 逆向工程实践
- python的正则表达式
- HTML5表单
- cordova开发问题汇总
- Object转bigdecimal
- LC串联谐振回路
- VMware系统运维(十六)部署虚拟化桌面 Horizon View Manager 5.2 配置池
- python正则表达式——re模块
- javamail发送邮件的简单实例(转)
- Windows Shell(外壳)编程相关
- WebRequest调用
- 《深入理解Java虚拟机》读书笔记-垃圾收集器与内存分配策略
- 初学python之路-day07-字符编码
- 剑指offer字符串列表
- String,StringBuffer与StringBuilder的区别|线程安全与线程不安全
- Centos7 安装并配置redis
- 零基础学习python_easygui(35课)
- windows下忘记mysql超级管理员root密码的解决办法(也适用于wamp)
- Modbus TCP和Modbus Rtu协议的区别 转
- 【CF687D】Dividing Kingdom II 线段树+并查集