python urllib2 实现大文件下载
2024-09-02 10:38:33
使用urllib2下载并分块copy:
# from urllib2 import urlopen # Python 2
from urllib.request import urlopen # Python 3
response = urlopen(url)
CHUNK = 16 * 1024
with open(file, 'wb') as f:
while True:
chunk = response.read(CHUNK)
if not chunk:
break
f.write(chunk)
另一种大文件copy方式, shutil:
import shutil
try:
from urllib.request import urlopen # Python 3
except ImportError:
from urllib2 import urlopen # Python 2
def get_large_file(url, file, length=16*1024):
req = urlopen(url)
with open(file, 'wb') as fp:
shutil.copyfileobj(req, fp, length)
关于shutil的一些介绍:https://www.cnblogs.com/zhangboblogs/p/7821702.html
使用urlib2并显示下载进度,以视频为例:
#coding:utf-8
import urllib
import urllib2
import requests
import random
import uuid
import time
import sys
from threading import Thread #img_url = "https://p.ssl.qhimg.com/dm/48_48_100/t017aee03b28107657b.jpg" img="http://vip.zuiku8.com/1810/妖精的尾巴最终季-01.mp4" my_headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
'Referer':'https://www.bilibili.com/bangumi/play/ep250436',
} def chunk_report(bytes_so_far, chunk_size, total_size):
percent = float(bytes_so_far) / total_size
percent = round(percent*100, 2)
if percent %1==0:
sys.stdout.write("Downloaded %d of %d bytes (%0.2f%%)\n" %
(bytes_so_far, total_size, percent)) if bytes_so_far >= total_size:
sys.stdout.write('\n') def chunk_read(response, url,chunk_size=8192, report_hook=None):
total_size = response.info().getheader('Content-Length').strip()
total_size = int(total_size)
bytes_so_far = 0
path_name=url.split("/")[-1]
path_name=path_name.replace("\n","")
path_name=path_name.decode("utf-8")
print path_name
with open("%s" % path_name, "wb") as f:
while 1:
chunk = response.read(chunk_size)
f.write(chunk)
f.flush()
bytes_so_far += len(chunk)
if not chunk:
break
if report_hook:
report_hook(bytes_so_far, chunk_size, total_size)
return bytes_so_far def down_load(img):
print img
request = urllib2.Request(url=img, headers=my_headers)
response = urllib2.urlopen(request);
chunk_read(response,img, report_hook=chunk_report)
print "downloading with urllib --->" if __name__ == '__main__':
down_load(img)
结果:
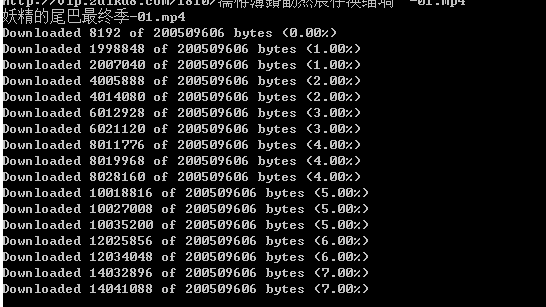
如果想在一行显示,打印时加\r,end为空 :
print ('\r downloading...{:.1f}'.format(percent), end="")
\r 是移至本行行首
\b 是退一个字符
此外,提一下urllib,之后没有用它,是因为不支持https:
#!/usr/bin/python
#encoding:utf-8
import urllib
import os img="http://vip.zuiku8.com/1810/妖精的尾巴最终季-01.mp4" def Schedule(a,b,c):
'''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0*a*b/c
if per > 100:
per = 100
print '%.2f%%' % per def main():
path=img.split(".")[-1]
urllib.urlretrieve(img,path,Schedule) if __name__ == '__main__':
main()
使用urllib2时,发现https下载不成功,添加了如下代码:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
最新文章
- 【Junit 报错】No appenders could be found for logger (org.springframework.core.env.StandardEnvironment).
- CI框架区分前后台
- SUSE Linux 13服务器版
- Linux zabbix 配置注意事项
- ajax返回值中有回车换行、空格解决方法
- Codeforces 475D CGCDSSQ(分治)
- 15分钟弄懂 const 和 #define
- JSON 入门
- mongodb----修改器
- 安装centos7注意事项
- c# 委托详解
- 基于HTML5的WebGL实现的2D3D迷宫小游戏
- python基础(1)
- okhttp post form表单
- 使用 IntraWeb (29) - 基本控件之 TIWAutherList、TIWAutherINI、TIWAutherEvent
- php中的正则函数:正则匹配,正则替换,正则分割 所有的操作都不会影响原来的字符串.
- 如何在maven项目里面编写mapreduce程序以及一个maven项目里面管理多个mapreduce程序
- spark shuffle 机制
- destructuring assignment
- 嵌入式开发之hi3519---i2c EEPROM