Scrapy框架——安装以及新建scrapy文件
2024-10-07 15:33:32
一.安装
conda install Scrapy :之后在按y 表示允许安装相关的依赖库(下载速度慢的话也可以借助镜像源),安装的前提是安装了anaconda作为python , 测试scrapy是否安装成功,在窗口输入scrapy回车
注意:我这是之前安装了anaconda 所以能直接这样下载 如果没有则需要自己一个一个下载依赖库 和scrapy 但是可以借助豆瓣的镜像源来快速安装
格式: pip install -i https://pypi.douban.com/simaple/ scrapy

二.创建scrapy项目的过程:
1.首先进入到你所要创建项目文件的路径下。cd ……
2.scrapy startproject 项目(文件)名 ------这就是创建一个scrapy项目文件了

3.cd (我们刚刚刚创建的)项目(文件)名。
4.scrapy genspider spider的一个名称(一个.py的爬虫文件) spider的域名(爬取的网页的网址)

5上面我们创建了一个scrapy文件 并且在spider(scrapy项目文件下)下创建一个.py文件 ,名字是jobbole 地址blog.jobbole.com (伯乐在线的)
我通过pycharme打开scrapy文件,如图:

三.但是我们运行jobbole文件 发现出现错误。说我的scrapy框架没安装
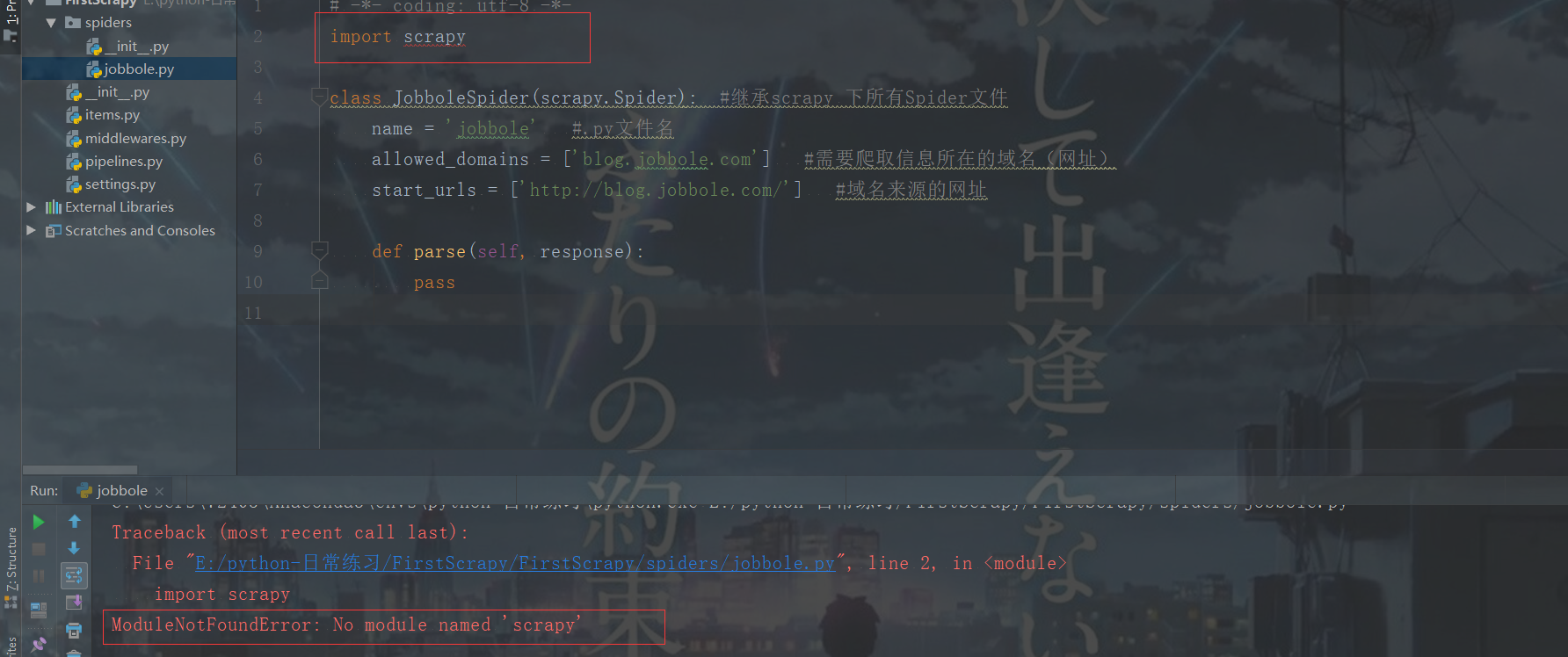
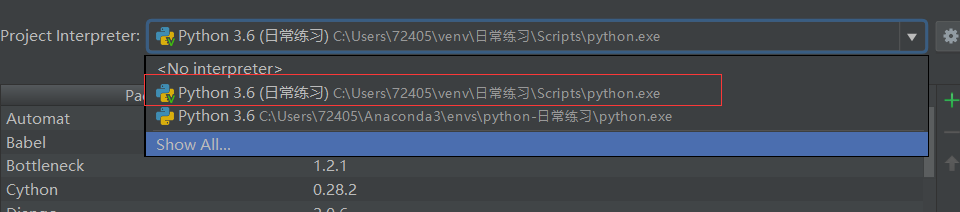
四..发现问题在哪:是pycharm的路径问题,应该放在scripts的一个路径下 如图:
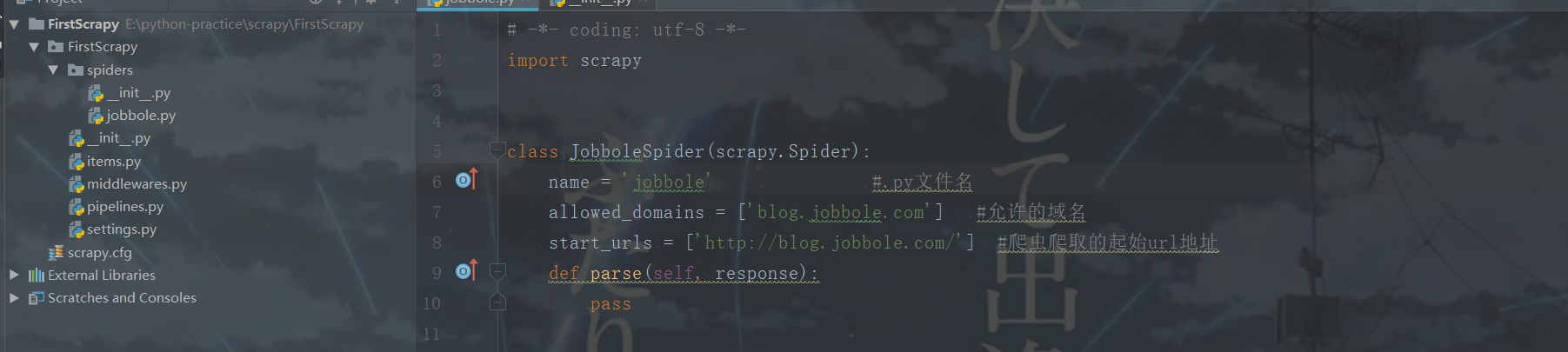
五.运行成功:
最新文章
- 配置IP地址
- jQuery EasyUI API 中文文档 - ValidateBox验证框
- js去掉html标签和去掉字符串文本的所有的空格
- [原]Java面试题-将字符串中数字提取出来排序后输出
- python3 urllib.request.urlopen() 地址打开错误
- 最全面的Java字节byte操作,处理Java基本数据的转换及进制转换操作工具,流媒体及java底层开发项目常用工具类
- centos 7 安装MySQL 5.6
- CCNP-3.vlan间路由及三层交换机的配置
- tamcat的使用
- Unity 利用UGUI打包图集,动态加载sprite资源
- PHP之ThinkPHP框架(界面)
- ①泡茶看数据结构-表ADT
- 网络编程—端口分类调研和netstat命令
- Android JNI c/c++调用java 无需新建虚拟机
- nginx-exporter安装使用
- zeebe docker-compose 运行(包含monitor)
- nodejs使用案例-mysql操作
- ROS 进阶学习笔记(13) - Combine Subscriber and Publisher in Python, ROS
- C++以多态方式处理数组可能会遇到的问题
- bzoj 2038 小Z的袜子(hose)(莫队算法)