Spark 概念学习系列之Spark存储管理机制
Spark存储管理机制
概要
01 存储管理概述
02 RDD持久化
03 Shuffle数据存储
04 广播变量与累加器
01 存储管理概述
思考:
RDD,我们可以直接使用而无须关心它的实现细节,RDD是Spark的基础,但是有个问题大家也许会比较关心:RDD所操作的数据究竟在哪里?它是如何存储的。
回顾:

1.1 、存储管理模块架构—从架构上来看
1.1.1 通信层
通信层面采用主从方式实现通信(主从节点间互换消息)
1.1.2 存储层
存储层负责提供接口来存储数据(可把数据存储到内存,磁盘,或者远端)
1.2 存储管理模块架构—从功能上来看
1.2.1 RDD缓存
整个存储管理模块主要的工作是作为RDD的缓存,包括基于内存和磁盘的缓存
1.2.2 Shuffle数据的持久化
Shuffle中间结果的数据也是交由存储管理模块进行管理的。Shuffle性能的好坏直接影响了Spark应用程序整体的性能,因此存储管理模块中对于Shuffle数据的处理有别于传统的RDD。
1.2.3 缓存
注意:还有其他数据的存储,请移步。见
储模块由操作类BlockManager统一对外提供服务
1.3 存储管理模块架构—通信层

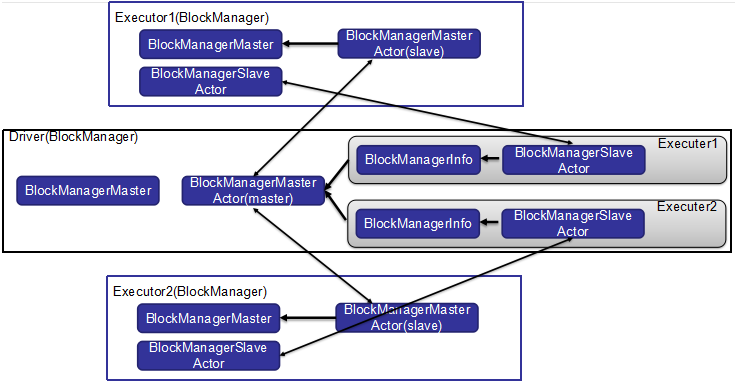
1.4 存储管理模块架构—通信层--BlockManager
(1)BlockManager类通过BlockManagerMaster进行通信;
(2)主节点的BlockManager会包含所有从节点的BlockManager信息;
(3)主从节点之间通过各自的BlockManagerMasterActor来进行相互通信;
1.5 存储管理模块架构—存储层

1.6 存储管理模块架构—数据块与分区的关系
我们知道,RDD是基于分区(partition)来计算的。
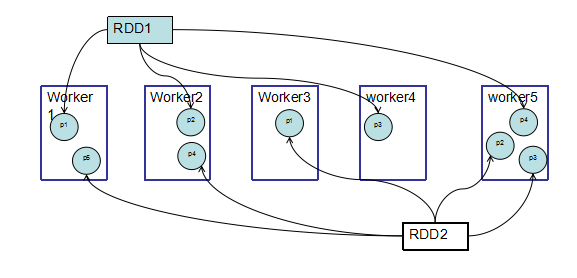
在存储管理中,存储是以block为单位的。实际上RDD的partition与block是一一对应的。他两是通过映射关系联系到一起的。
具体映射关系:block名=“rddID+分区索引号”。

02 RDD持久化
2.1 回顾—RDD控制操作
persist操作,可以将RDD持久化到不同层次的存储介质,以便后续操作重复使用。
1.cache:RDD[T]
2.persist:RDD[T]
3.persist(level:StorageLevel):RDD[T]
首次使用RDD的时候,我们可以选择对RDD进行持久化,当再次使用RDD是就可以直接从之前的缓存中获取而无需再次进行计算。对于需要反复使用的RDD会带来很大的性能改善。
2.2 持久化级别

2.3 如何选择持久化级别
首选MEMORY_ONLY;其次选MEMORY_ONLY_SER;
如果数据量大且重新计算的开销大,那就用MEMORY_AND_DISK;
如果要确保快速的恢复机制,那就选MEMORY_ONLY_2,
MEMORY_AND_DISK_2(因为有备份)
注意:具体选择时需要结合应用特点以及机器性能做出权衡
2.4 缓存淘汰机制
当数据超过缓存阈值时:Spark会丢弃一部分内存中的数据或者将一部分数据从内存移出到磁盘中(LRU),具体情况依据RDD的持久化选项。
如果是直接丢弃数据的话,程序会否报错呢?
答案是不一定的。如果被删除的数据的祖先是可被回溯到的,那么可以通过重新计算得到丢失的数据;相反,程序会报错哦。
RDD 还有一个方法叫作unpersist(),调用该方法可以手动把持久化的RDD 从缓存中移除
03 Shuffle数据持久化

shuffle数据必须是在磁盘上进行缓存,不能选择在内存中缓存;
RDD在磁盘持久化时一个block对应一个文件,而shuffle数据块只是逻辑上的概念,存储方式因实现方式不同而不同:0
默认将shuffle数据块,也就是一个bucket映射成文件(文件过多)
另外一种方式是将shuffle数据块映射成文件中的一段(将spark.shuffle.consolidateFiles设置为TRUE)
04、广播变量和累加器
4.1 广播变量--Broadcast Variables
实现数据在每个节点上都有一份拷贝
广播变量也是存储模块来管理的,以MEMORY_AND_DISK方式存储
val signPrefixes = sc.broadcast(loadCallSignTable())
val countryContactCounts = contactCounts.map{case (sign, count) =>
val country = lookupInArray(sign, signPrefixes.value)
(country, count)
}.reduceByKey((x, y) => x + y)
countryContactCounts.saveAsTextFile(outputDir + "/countries.txt")
4.2 累加器--Accumulators
提供了将工作节点中的值聚合到驱动器程序中的简单语法
val sc = new SparkContext(...)
val file = sc.textFile("file.txt")
val blankLines = sc.accumulator() // 创建Accumulator[Int]并初始化为0
val callSigns = file.flatMap(line => {
if (line == "") {
blankLines += // 累加器加1
}
line.split(" ")
})
callSigns.saveAsTextFile("output.txt")
println("Blank lines: " + blankLines.value)
最新文章
- Jass 技能模型定义(—):半人马酋长的反击光环
- css选择符
- TCP/IP 七层协议
- Java后台判断请求来自PC端还是移动端
- #VSTS日志# 2015/12/10 – 终于可以删除工作项了
- xmpp即时通讯的笔记(摘抄)
- 安装 openSUSE Leap 42.1 之后要做的 8 件事
- VMware Snapshot 工作原理
- 【皇甫】☀亲爱的~help me
- Matlab boxplot for Multiple Groups(多组数据的箱线图)
- 破解Xamarin
- UPC 2224 Boring Counting ★(山东省第四届ACM程序设计竞赛 tag:线段树)
- bzoj 1411 [ZJOI2009]硬币游戏
- SQLite 入门教程(一)基本控制台(终端)命令
- rsync数据同步配置
- HMM的概率计算问题和预测问题的java实现
- CTFCrackTools在Windows下显示A Java Exception has occurred的解决方案
- openFileDialog的Filter属性设置
- Nginx 学习笔记(十)介绍HTTP / 2服务器推送(译)
- 基于Java的REST架构风格及接口安全性设计的讨论