http客户端与浏览器的区别
两者区别:浏览器对http响应头会进行特定处理(如自动读取本地缓存、设置cookie等),而http客户端(如crul)可能没有像浏览器那样的处理,某些封装程度高的http客户端,可能会有。
同一个文件夹中有三个文件:
使用了http标准库的js客户端:
const http = require('http');
const options = {
hostname: '127.0.0.1',
port: 8080,
path: '/api',
method: 'GET'
};
const req = http.request(options, function (res) {
console.log('STATUS:' + res.statusCode);
console.log('HEADERS:' + JSON.stringify(res.headers));
res.setEncoding('utf-8');
let data = "";
res.on('data', function (chunk) {
console.log(`接收到数据:${chunk}\r\n`);
data += chunk;
});
res.on('end', function () {
console.log('响应结束');
console.log('接收到的数据为:' + data);
});
});
req.end();
用于浏览器发起请求的h5页面:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="msg"></div>
<script>
var xhr = new XMLHttpRequest();
xhr.open("GET","http://127.0.0.1:8080/api",true);
xhr.send(null); xhr.onload = function(){
document.querySelector("#msg").innerHTML = xhr.responseText;
}
</script>
</body>
</html>
js服务端:
const http = require("http");
const fs = require("fs");
const server = http.createServer(function(req,res){
res.setHeader('Content-Type','text/html;charset=utf-8');
switch(true){
case req.url.startsWith('/index'):
fs.readFile('./index.html',"utf-8",function (_,data) {
res.end(data);
});
break;
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
res.end("每次请求都返回一个随机数:" + Math.random());
break;
}
});
server.listen(8080,'127.0.0.1',function(){
console.log(`服务器运行在8080`);
});
后续测试环境为:
访问地址:http://127.0.0.1:8080/index
以上地址每次访问,都会显示不同的随机数。
测试强缓存
服务器返回数据前,加上个强缓存设置(10s):
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
let curTime = +new Date();
let cacheOutDateTime = curTime + 10*1000;
let GMTTime = new Date(cacheOutDateTime).toGMTString();
res.setHeader('Expires', GMTTime);
res.end("每次请求都返回一个随机数:" + Math.random());
break;
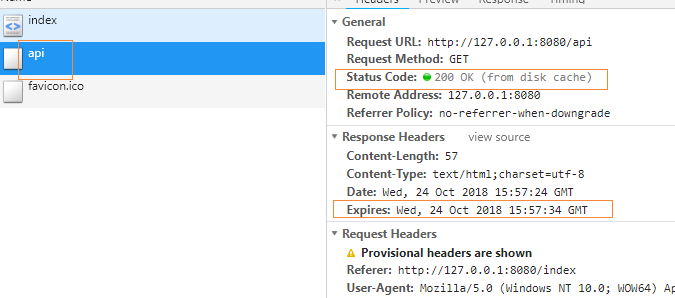
浏览器访问地址:http://localhost:8080/index
10s内不停刷新浏览器,显示的随机数都是一样的,说明强缓存生效了。
通过js客户端来访问,强缓存无效:
C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","expires":"Wed, 24 Oct 2018 15:58:26 GMT","date":"Wed, 24 Oct 2018 15:58:16 GMT","connection":"close","content-length":"59"}
接收到数据:每次请求都返回一个随机数:0.005061696884948619 响应结束
接收到的数据为:每次请求都返回一个随机数:0.005061696884948619 C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","expires":"Wed, 24 Oct 2018 15:58:27 GMT","date":"Wed, 24 Oct 2018 15:58:17 GMT","connection":"close","content-length":"57"}
接收到数据:每次请求都返回一个随机数:0.9111832960061363 响应结束
接收到的数据为:每次请求都返回一个随机数:0.9111832960061363
通过postman客户端来访问也是一样,强缓存无效。
结论:强缓存的头(这里测试的是expires)只能作用在浏览器上,对于这里的http客户端无效,因为这里的http客户端根本就没有用到那个http头,更别说还会自己去设置本地缓存了,这些工作浏览器才会去做。
测试协商缓存
添加一个etag头:
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
res.setHeader('Etag', '123');
res.end("每次请求都返回一个随机数:" + Math.random());
break;
多次访问页面,浏览器自动带上了if-none-match头

但是协商缓存没有生效,以上两个数值明明一样的。原因在于if-none-match对应的数值,仅仅是给服务端用于校验而已,如果服务端没有读取这个值进行校验的话,则什么效果都没有。要有效果的话,则要求服务端校验完成后,返回个302状态码,才能使浏览器使用本地缓存。
if-none-match:代表本地已经有缓存了,而且这个缓存的标识符是123。服务器知道这些信息之后,再用于判断是否需要告诉浏览器去使用缓存(是否要返回304)。
假如直接返回304的话,则访问/api时,虽然能完成请求(打开chrome调试工具,显示响应状态码为304),但响应数据为空:
case '/api':
console.log(JSON.stringify(req.headers));
res.statusCode = 304;
res.end("每次请求都返回一个随机数:" + Math.random());
break;
正确的判断方式,以下设置了304之后,不管有没有返回正文内容,正文内容都会被忽略
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
res.setHeader('Etag', "123");
if("123" == req.headers['if-none-match']){
res.statusCode = 304;
res.end();
}
res.end("每次请求都返回一个随机数:" + Math.random());
break;
}
});
修改完成后,用浏览器多次请求,都使用的是本地缓存,即显示到界面上的随机数一直无变化。
然后再用js客户端进行请求,结果如下:
C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","etag":"123","date":"Wed, 24 Oct 2018 16:25:53 GMT","connection":"close","content-length":"57"}
接收到数据:每次请求都返回一个随机数:0.7875283103348185 响应结束
接收到的数据为:每次请求都返回一个随机数:0.7875283103348185 C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","etag":"123","date":"Wed, 24 Oct 2018 16:25:54 GMT","connection":"close","content-length":"57"}
接收到数据:每次请求都返回一个随机数:0.2601388266595912 响应结束
接收到的数据为:每次请求都返回一个随机数:0.2601388266595912
结论: 因为这个http客户端没有像浏览器那样遵守了http规范,接收到etag时,下次请求时没有带上if-none-match,导致服务器没办法用于判断,所以一直返回200,导致协商缓存失效。
最新文章
- Oracle数据库验证IMP导入元数据是否会覆盖历史表数据
- Jsoup开发网站客户端第二篇,图片轮播,ScrollView兼容ListView
- Dynamics AX 2012 R3 仓库和运输管理系列 - 仓库管理模块安装与配置
- 【转载】java版打字练习软件
- KMP--Cyclic Nacklace
- iOS自定义UICollectionViewLayout之瀑布流
- (转)DEDECMS 如何让栏目外部链接在新窗口中打开
- pm2用法详解+ecosystem.config
- python实现四则运算和效能分析
- Java 7 和 Java 8 中的 HashMap原理解析
- 前端学习-基础部分-css(一)
- Windows Linux的cmd命令查询指定端口占用的进程并关闭
- qt+opencv LNK4272:library machine type 'x64' conflicts with target mathine type 'x86'
- ubuntu server 18.04 lts 终端中文显示为乱码的解决方案
- Python爬虫【二】请求库requests
- django的mysql设置和mysql服务器闲置时间设置
- sencha touch 简单的倒计时插件
- CSS控制显示图片的一部分
- android ndk 编译的时候指令集的选取
- 二维vector容器读取txt坐标
热门文章
- BZOJ 1433 && Luogu P2055 [ZJOI2009]假期的宿舍 匈牙利算法
- BZOJ 1123 && Luogu P3469 [POI2008]BLO-Blockade 割点+乘法原理
- python中“生成器”、“迭代器”、“闭包”、“装饰器”的深入理解
- (转)网站DDOS攻击防护实战老男孩经验心得分享
- Redis set(集合)
- 常用的 HTML 头部标签
- 转:IOS程序之间的文件共享
- POJ3252Round Numbers(数位dp)
- 1068 乌龟棋 2010年NOIP全国联赛提高组
- html页面和jsp页面的区别