一图看懂Hadoop中的MapReduce与Spark的区别:从单机数据系统到分布式数据系统经历了哪些?
今日博主思考了一个问题:Hadoop中的MapReduce与Spark他们之间到底有什么关系?
直到我看到了下面这张图
废话不多说先上图
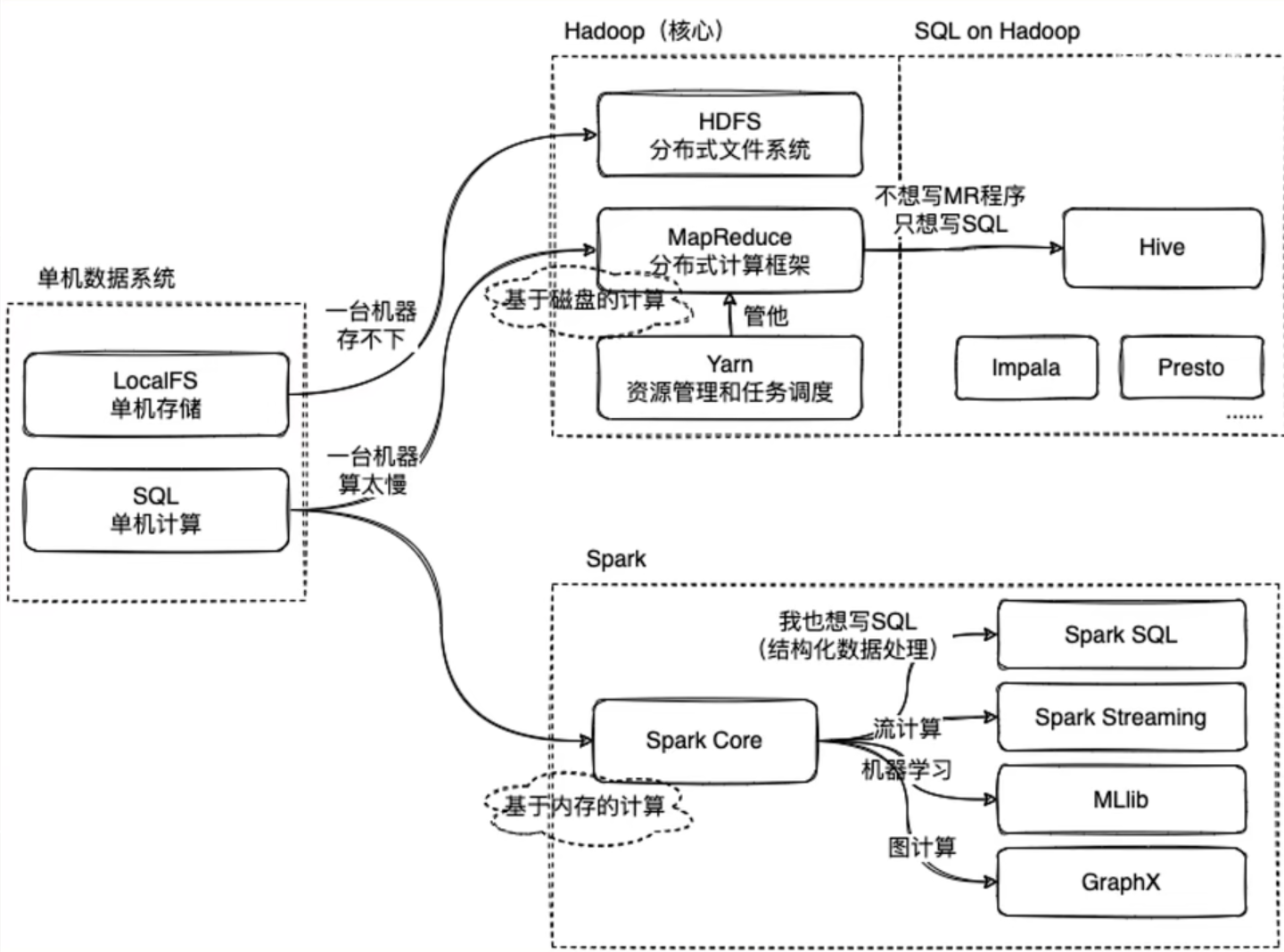
我们知道,单机数据系统,在本地主机上针对数据有单机本地存储操作(localFS)和单机计算操作(SQL)
这是在数据量比较小方便在一台主机就完成任务的情况。
那当我们的业务需要的数据足够大,一台机器完全应付不过来的时候应该怎么办?
我们很容易想到,既然一台机器办不到的事情,我们就交给10台机器、100台机器去办。
没错!
当我们的数据量足够庞大时,我们需要多台机器协同完成业务,此时我们就需要将数据一份份分成足够让一台机器能处理运行的小部分,布置给多台机器共同完成,这就是所谓的分布式数据系统
Hadoop就是为这样的业务场景服务的
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多计算机组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。————wikipedia
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高。
其中HDFS分布式文件系统做到了利用多台机器的分布式文件存储,而MapReduce则实现了对数据的计算,而我们还需要一个对他们实现调度管理的“帮手”——Yarn
Mapreduce的实现需要自己编写计算框架,这很麻烦。
所以为什么不能有像单机数据系统的SQL一样方便的操作呢?
于是Hive就诞生了。
那,Spark又是怎么回事?
Spark对标的是Hadoop中的计算模块MapReduce,而一般情况下Spark会比MapReduce快2~3倍,
这是因为,MapReduce是基于磁盘的计算,而Spark是基于内存的计算。
而Spark中也有像Hive一样为了方便而诞生的只用写SQL语句就能完成数据处理的方式——Spark SQL
在Spark中还有一些格外的功能,例如针对机器学习使用的Spark MLib、针对流计算的Spark streaming以及针对图计算的Spark GraphX等等
以上就是Hadoop中的MapReduce与Spark 的区别,以及他们实现为了实现结构化数据处理进行的SQL实现。
最新文章
- 解决Android Graphical Layout 界面效果不显示
- 多线程中共享变量——CCF总决赛试题
- 【.Net底层剖析】3.用IL来理解属性
- zookeeper安装配置
- 将doc文件批量转为pdf文件
- C#:WebBrowser中伪造referer,为何对流量统计器无效?
- BUY LOW, BUY LOWER_最长下降子序列
- C#生成DBF文件
- ASP.NET MVC ModelState
- Cocos2d-x数据持久化-查询数据
- Android开发中常用的Eclipse快捷键
- selenium webdriver python 开始
- struts2必需jar包
- 【原创】mdk5宏定义的使用小结
- Python+Selenium基础篇之1-环境搭建
- Java并发编程(一)-为什么要并发
- linux最小化安装后的初始化
- 工作随笔—static关键字
- Servlet 快速开始 表单中文字段
- Mysql服务配置优化