ResNet的个人总结
ResNet可以说是我认真读过的第一篇paper,据师兄说读起来比较简单,没有复杂的数学公式,不过作为经典的网络结构还是有很多细节值得深究的。因为平时不太读英文文献,所以其实读的时候也有很多地方不是很懂,还是搜了很多博客,所以我准备结合paper将读到的内容做一下总结。
一、为什么要引入ResNet?
首先作者提出了一个问题:深度越深的网络是否能够学习得越好?
答案必然是否定的,由于更新参数需要计算梯度,而网络层次越深也意味着一旦有某个节点的梯度接近0或接近无穷,根据链式法则,多次梯度连乘后会变得更小/更大,从而出现梯度消失/爆炸问题,这样无疑会影响算法的收敛。不过这个问题可以通过对中间数据进行归一化操作来解决(BN),但是,这个方法仅对几十层的网络有用,当网络更深时效果就没那么好了。 因此ResNet就诞生了。
二、Residual Block
在学习ResNet之前,我们先来看看Residual Block,ResNet实际上就是由多个1个卷积层+1个Max Pooling层+Residual Block+1个Avg Pooling层+1个全连接层组成的。
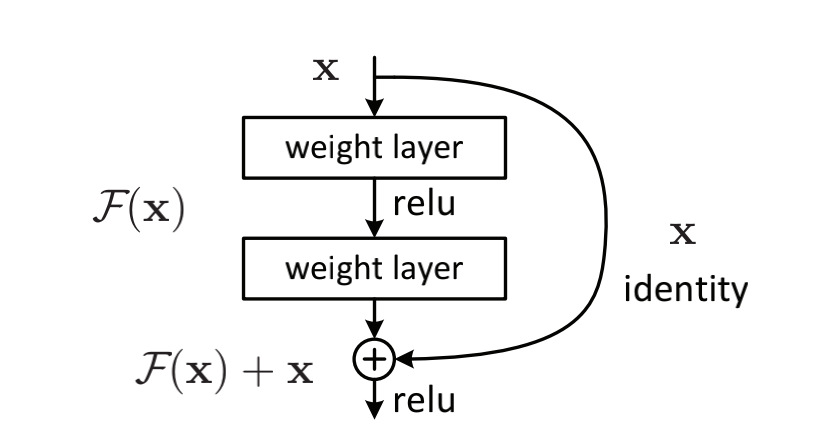
我们先来理解残差的概念,残差即观测值与估计值之间的差
$x$:即为上一层网络传下来的特征映射,也就是估计值(identity mapping)
$H(x)$:最后需要求解的特征映射,也就是观测值
现在咱们将这个问题转换为求解网络的残差映射函数,也就是$F(x)$,其中$F(x) = H(x)-x$。至于为什么要引入残差映射函数呢?
作者在提出ResNet时做出了这样的假设:若某一较深的网络多出另一较浅网络的若干层有能力学习到恒等映射,那么这一较深网络训练得到的模型性能一定不会弱于该浅层网络.通俗的说就是如果对某一网络中增添一些可以学到恒等映射的层组成新的网络,那么最差的结果也是新网络中的这些层在训练后成为恒等映射,而不会影响原网络的性能。
总结来说主要是以下两个原因:
(1)当网络学习到很深层次的时候,此时输出的特征$x$已经很接近$H(x)$了,也就是错误率已经很低了,那么如果继续训练下去,很有可能最终反而会偏离$H(x)$更远,这也是作者最开始就提到的网络层次越深错误率反而升高的问题,所以接下来的网络结构需要做的就是保持上一层网络结果输出的结果,也就是使$F(x)$为0,让x直接通过这一层。
(2)引入残差函数后更容易优化,特征映射对输出的变化更为敏感, 因此会更快达到收敛。下面是一个简单的例子:
假设有一个网络结构,其中非残差网络为$x=1$,$G$,残差网络为$H$,残差函数$F(x) = H(x)-x$
那么假设在$t$时刻:
$$G_{t}(1) = 1.1$$
$$H_{t}(1) = 1.1 即 F_{t}(1) = H_{t}(1) - x = 1.1 - 1 = 0.1$$
在$t+1$时刻:
$$G_{t}(2) = 1.2$$
$$H_{t}(2) = 1.2 即 F_{t}(2) = H_{t}(2) - x = 1.2 - 1 = 0.2$$
计算梯度:
$$Grad_{G} = \frac{(G_{t}(2) - G_{t}(1))}{G_{t}(1)} = \frac{(1.2 - 1.1)}{1.1}$$
$$Grad_{F} = \frac{(F_{t}(2) - F_{t}(1))}{G_{t}(1)} = \frac{(0.2 - 0.1)}{0.1}$$
显然,变化对$F$的影响远远大于$G$,说明引入残差后的映射对输出的变化更敏感,这样是有利于网络进行传播的。
三、ResNet网络结构
在pape中,作者主要提到了两种网络结构,第一种是BasicBlock,主要用在ResNet18和ResNet34,第二种是Bottleneck,主要用在ResNet50、ResNet101和ResNet152。
BasicBlock:
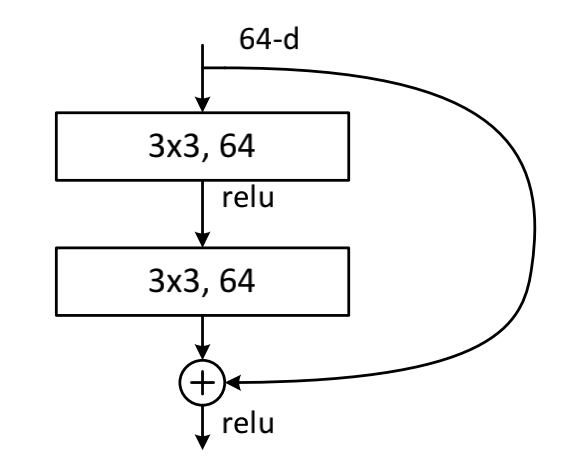
在这种结构中,由(3x3+3x3)的卷积核组成,是文中最开始提到的结构。
Bottleneck:
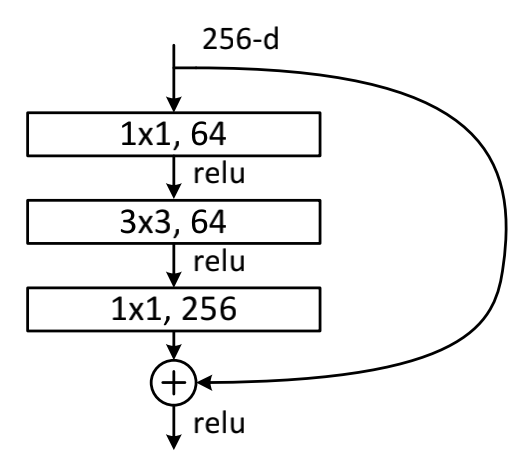
随着层次的增加,为提高性能,文中采用(1x1+3x3+1x1)的结构代替了上面的结构,该结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在通过另一个1x1的卷积核下做了升维还原,大大减少了参数量,还保持了精度。
维度变化:
说完两种网络结构,我们来说一下里面具体的维度变化(主要研究跳跃连接$x$,也就是shortcut),文中一共说到了shortcut的两种变换,分别用以下两个公式表示。
(1)
$$y = F(x, \lbrace w_{i} \rbrace)+x$$
可以看前面的两张block图,输入映射特征和输出映射特征维度是相同的,所以shortcut不需要做任何变化,也就是说shortcut可以直接用x来表示。
(2)
$$y = F(x, \lbrace w_{i} \rbrace)+w_{s}x$$
但是从论文中经典的ResNet34中可以看到,在两个大层之间(这里我们把通道数相同的层称为一个大层,通俗理解就是图中颜色相同的层为一个大层)有一个stride为2的down sampling操作,同时通道数也从64变为128,因为$H(x) = F(x)+x$,那此时残差映射$F(x)$的结果的维度与跳跃连接$x$的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对$x$进行升维操作,让他俩的维度相同时才能计算。

所以在代码实现中,我们经常看到以下操作,其实指的就是这种情况啦。关于ResNet网络结构中的维度变化也可以看看这篇博客,有更详细的讲解。
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
至于增加维度的方法,文中也提到了2种:
(1)用0填充不足的维度
(2)通过$w_{s}*x$来增加x的维度,实际上也是通过1x1的卷积核完成这个操作的
引入ResNet后可以看到随着网络加深,性能越来越好。但随着网络不断加深性能真的会越来越好吗?其实不然,作者在Cifar-10上做实验进行了证明,一味加深深度超过1000层,误差同样也会再次变大,至于原因作者认为是网络过深,数据集太小,发生了过拟合,不过作者在本实验中没有采用dropout,或许我们在自己实验的时候可以加上去,效果应该会更好。
四、ResNet的Pytorch实现
该结构用于ImageNet数据集(仅结构部分代码):
# 3x3 3x3
class BasicBlock(nn.Module):
expansion = 1 def __init__(self, in_plans, plans, stride):
super(BasicBlock, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_plans, plans, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(plans),
nn.Conv2d(plans, plans, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(plans)
)
self.relu = nn.ReLU(inplace=True)
self.shortcut = nn.Sequential() if stride != 1 or self.expansion*plans != in_plans:
self.shortcut = nn.Sequential(
nn.Conv2d(in_plans, self.expansion*plans, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*plans)
) def forward(self, x):
out = self.conv(x) + self.shortcut(x)
out = self.relu(out)
return out # 1x1 3x3 1x3
class Bottleneck(nn.Module):
expansion = 4 def __init__(self, in_plans, plans, stride):
super(Bottleneck, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_plans, plans, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(plans),
nn.Conv2d(in_plans, plans, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(plans),
nn.Conv2d(plans, plans*self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(plans*self.expansion),
)
self.rule = nn.ReLU(inplace=true)
self.shortcut = nn.Sequential() if stride != 1 or self.expansion*plans != in_plans:
self.shortcut = nn.Sequential(
nn.Conv2d(in_plans, self.expansion*plans, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*plans),
) def forward(self, x):
out = self.conv(x) + self.shortcut(x)
out = self.rele(out)
return out class ResNet(nn.Module): def __init__(self, block, layer, num_classes):
super(ResNet, self).__init__() self.in_plans = 64
self.conv = nn.Conv2d(3, self.in_plans, kernel_size=7, padding=3, stride=2)
self.bn = nn.BatchNorm2d(self.in_plans)
self.rule = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layer[0], 1)
self.layer2 = self._make_layer(block, 128, layer[1], 2)
self.layer3 = self._make_layer(block, 256, layer[2], 2)
self.layer4 = self._make_layer(block, 512, layer[3], 2)
self.avgpool = nn.AvgPool2d(7) # 看此时图像的h和w
self.fc = nn.Linear(512*block.expansion, num_classes) def _make_layer(self, block, plans, num_layer, stride):
strides = [stride] + [1]*(num_layer - 1)
layer = []
for stride in strides:
layer.append(block(self.in_plans, plans, stride))
self.in_plans = plans*block.expansion
return nn.Sequential(*layer) def forward(self, x):
out = self.rule(self.bn(self.conv(x)))
out = self.maxpool(out) out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out) out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
该结构用于CIFAR10(完整代码):
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms device = torch.device('cuda:7' if torch.cuda.is_available else 'cpu') num_epochs = 80
batch_size = 100
lr = 0.001 transform = transforms.Compose([
transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()
]) def read_data():
train_dataset = torchvision.datasets.CIFAR10(root='../dataset/CIFAR-10', train=True, transform=transform, download=False)
val_dataset = torchvision.datasets.CIFAR10(root='../dataset/CIFAR-10', train=False, transform=transforms.ToTensor(), download=False) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=batch_size, shuffle=False)
return train_loader, val_loader # 3x3 3x3
class BasicBlock(nn.Module):
expansion = 1 def __init__(self, in_plans, plans, stride):
super(BasicBlock, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_plans, plans, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(plans),
nn.Conv2d(plans, plans, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(plans)
)
self.relu = nn.ReLU(inplace=True)
self.shortcut = nn.Sequential() if stride != 1 or self.expansion*plans != in_plans:
self.shortcut = nn.Sequential(
nn.Conv2d(in_plans, self.expansion*plans, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*plans)
) def forward(self, x):
out = self.conv(x) + self.shortcut(x)
out = self.relu(out)
return out # 1x1 3x3 1x3
class Bottleneck(nn.Module):
expansion = 4 def __init__(self, in_plans, plans, stride):
super(Bottleneck, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_plans, plans, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(plans),
nn.Conv2d(in_plans, plans, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(plans),
nn.Conv2d(plans, plans*self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(plans*self.expansion),
)
self.rule = nn.ReLU(inplace=true)
self.shortcut = nn.Sequential() if stride != 1 or self.expansion*plans != in_plans:
self.shortcut = nn.Sequential(
nn.Conv2d(in_plans, self.expansion*plans, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*plans),
) def forward(self, x):
out = self.conv(x) + self.shortcut(x)
out = self.relue(out)
return out class ResNet(nn.Module): def __init__(self, block, layer, num_classes):
super(ResNet, self).__init__() self.in_plans = 16
self.conv = nn.Conv2d(3, self.in_plans, kernel_size=3, padding=1)
self.bn = nn.BatchNorm2d(self.in_plans)
self.rule = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, 16, layer[0], 1)
self.layer2 = self._make_layer(block, 32, layer[1], 2)
self.layer3 = self._make_layer(block, 64, layer[2], 2)
self.avgpool = nn.AvgPool2d(8)
self.fc = nn.Linear(64*block.expansion, num_classes) def _make_layer(self, block, plans, num_layer, stride):
strides = [stride] + [1]*(num_layer - 1)
layer = []
for stride in strides:
layer.append(block(self.in_plans, plans, stride))
self.in_plans = plans*block.expansion
return nn.Sequential(*layer) def forward(self, x):
out = self.rule(self.bn(self.conv(x))) out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out) out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out def build_model(train_loader, val_loader, block, layer, num_classes):
# Loss
model = ResNet(block, layer, num_classes).to(device)
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device) optimizer.zero_grad() outputs = model(images)
batch_loss = loss(outputs, labels)
batch_loss.backward()
optimizer.step() if (i+1) % 100 == 0:
print ("Epoch [{}/{}], Step [{}/{}] Loss: {:.4f}"
.format(epoch+1, num_epochs, i+1, len(train_loader), batch_loss.item())) model.eval()
with torch.no_grad():
acc = 0
total = 0
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device) outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
acc += (predicted == labels).sum().item() print('The Accuracy of the model on the valset is: {}%'.format(acc/total*100)) if __name__ == '__main__':
train_loader, val_loader = read_data()
build_model(train_loader, val_loader, BasicBlock, [2, 2, 2], 10)
最新文章
- 不安装Oracle客户端使用PLSQL连接Oracle数据库的方法
- Nginx -- Gzip 压缩功能作用
- python百分比数比较大小
- IOS学习笔记之关键词@dynamic
- CentOS thrift python demo
- 如何生成log新信息背景图片和在图片上添加水印
- iOS 制作 framework 教程
- 关于Maven的安装及初步使用
- 利用java反射机制编写solr通用的java客户端
- TensorFlow实战之实现AlexNet经典卷积神经网络
- arcgis api 3.x for js 入门开发系列十五台风轨迹
- Linux之安装常用软件
- ASP.NET上传大文件报错,IIS7.0
- Sql中如何将数据表的两个字段的值如何互换?
- 漫谈golang之fmt格式化模块
- 【Excel】输出固定长文本
- Android忽略文件
- RxJS之AsyncSubject
- 章节1:SQL语言简易入门
- Android开发--ZZ:Android APK反编译详解(附图)