elasticsearch kibana的安装部署与简单使用(二)
介绍一下elasticsearch和kibana的简单使用
es其实我理解为一个数据库,一个数据库无非就是增删改查,
Delete PUT GET POST 这些接口关键字完美对应
比如,我想查一张表showstart_index
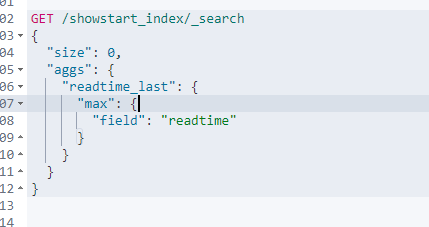
GET /showstart_index/_search
这张表中有几个文档
GET /showstart_index/_count
查看这表的mapping
GET showstart_index/_mapping
删除一张表
DELETE showstart_index
向表中添加一行
POST /showstart_index/_doc
{
"message":"i am test"
}
以上都是类比mysql的话语
如果一个空的表,可以直接向其中添加数据,es会自动生成改表的mapping,但是自动生成的mapping一般都不是我们想要的
所以在插入之前,应先给表设置mapping,mapping可以理解为mysql中的字段
PUT showstart_index
{
"mappings": {
"properties": {
"actor": { //actor为一个字段
"type": "text", //text为文本且需要分词,keyword是不需要分词
"analyzer": "ik_max_word", //ik_max_word是一个分词方式
"search_analyzer": "ik_smart" //查找的分词方式
},
"front_image_path": {
"type": "text",
"index": false //不成为查找的条件
},
"place": {
"type": "keyword"
},
"price": {
"type": "long" //长整型
},
"readtime": {
"type": "date",
"format": "yyyy/MM/dd HH:mm:ss||yyyy-MM-dd||yyyy/M/d HH:mm:ss" //将字符串按格式转为date类型
},
"showname": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"startime": {
"type": "date",
"format": "yyyy/MM/dd HH:mm:ss||yyyy-MM-dd||yyyy/M/d HH:mm:ss"
},
"type": {
"type": "keyword"
},
"url": {
"type": "text",
"index": false
}
}
}
}
es最大的优点在于他的查询分词,比如
POST _analyze
{
"analyzer": "standard", //使用standard分词器
"text": ["hello word!!"]
}
将hello word!!这个document做个分词看看结果

得到了hello和word两个词
我们来试试中文分词器ik
GET _analyze?pretty
{
"analyzer": "ik_smart",
"text": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}


还有一些聚合函数
最新文章
- spring-实现配置文件读取
- ORACLE 数据块dump
- 在项目中引用GreenDroid库
- JQuery_给元素添加或删除类等以及CSS()方法
- JavaScript之图片轮换
- c++sort函数的用法浅析
- ASPxGridview在对话框中无法编辑!!
- attachEvent和addEventListener详解
- laravel中token的使用方式
- EOS开发语言和石墨烯技术介绍
- SpringBoot2.0整合mybatis、shiro、redis实现基于数据库权限管理系统
- System.getProperty()获取系统的配置信息
- 知识点:java 注解 @SuppressWarnings
- gitlab docker安装配置ldap
- 一次MySQL异常排查:Query execution was interrupted
- Python 入门必学的8个知识点
- shell教程-002:常见的Shell种类
- JS 中的数据类型转换
- POJ 1122 FDNY to the Rescue!(最短路+路径输出)
- 成都Uber优步司机奖励政策(4月13日)