小白也能看懂的Redis教学基础篇——redis神秘的数据结构
各位看官大大们,周末好!

作为一个Java后端开发,要想获得比较可观的工资,Redis基本上是必会的(不要问我为什么知道,问就是被问过无数次)。
那么Redis是什么,它到底拥有什么神秘的力量,能获得众多公司的青睐?接下来就由小编我带大家来揭秘Redis的五种基本数据结构。
Redis是C语音编写的基于内存的数据结构存储系统。它可以当作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings),
列表(lists), 字典(dictht),集合(sets), 有序集合(sorted sets)。通常我们在项目中可以用它来做缓存、记录签到数据、分布式锁等等。
要使用Redis首先我们来了解一下它的五种基础数据结构。
1.字符串(strings)
Redis拥有两种字符串表述方式,其一是C语言传统的字符串表述方式,常用Redis代码中字符串常量等一些无需对字符串进行修改的地方。
第二种是自己封装了一种名为简单动态字符串(simple dynamic string)简称SDS的抽象类型,这个才是我们存储字符串时所使用的对象,等同于java中的StringBuilder。
SDS的结构如下:
struct sdshdr{
//记录字符数组中已经使用的字节数量 即是字符串的长度
int len;
//记录字符数组中未使用的字节数
int free;
//字符数组 用于保存字符串
char buf[];
}
结构如下图所示:
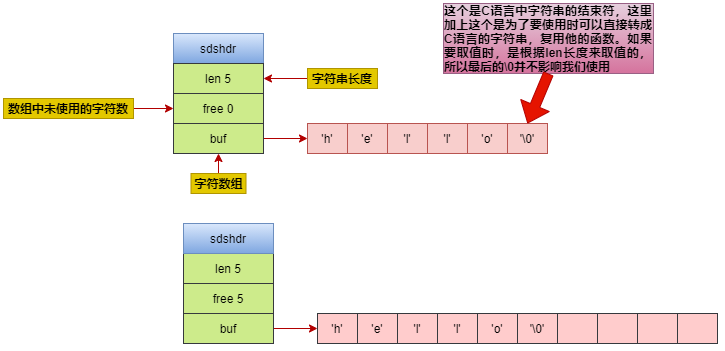
至于Redis为什么要使用这样的结构,其实和java使用StringBuilder的思维是大相径庭。为了方便修改和提升性能。比如C的字符串获取字符串长度时要遍历整个字符数组。
其时间复杂度是O(n),而SDS则可以直接获取len,时间复杂度为O(1)。修改字符串N次字符串并且字符串和以前的长度不一致时,C普通字符串长度必然需要执行N次内存重分配。
而SDS存在预扩容,所以最多需要执行N次内存分配。
注:与扩容其本质和list类似,在需要的长度大于现在数组的长度时,会触发字符串扩容,当数据小于1M时,字符数组每次扩容都是其原来容量的2倍。1M后每次扩容新增1M容量。
2.列表
Redis中的列表相当于java中的LinkedList,它是一个双向链表,插入和删除都拥有极好的性能,时间复杂度为O(1),但是随机查找比较慢,时间复杂度为O(n)。虽然可以将列表
当成一个LinkedList,但是在Redis内部列表并不是一个简单的双向链表的实现。在列表保存元素个数小于512个且每个元素长度小于64字节的时候为了节省内存其底层实现是一块
连续内存来存储,称之为ziplist压缩列表。当不满足之前的两个条件时则改用quicklist快速列表来存储原元素。
ziplist压缩列表:
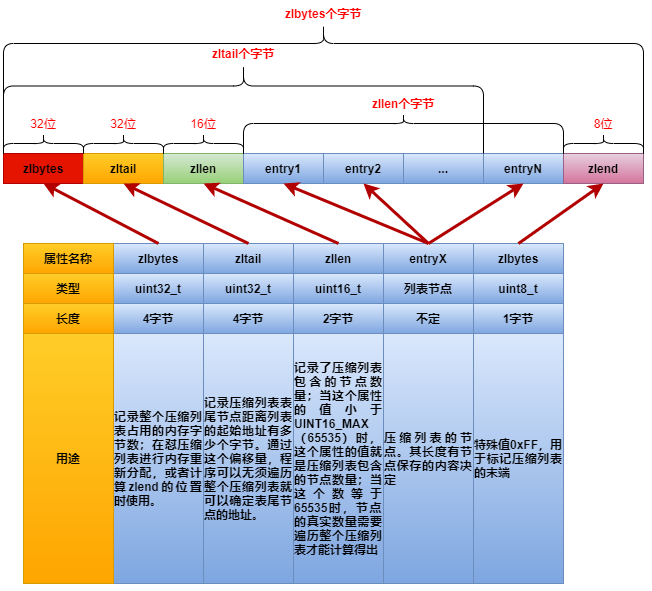
压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点,每个节点保存一个字节数组或者一个整数值。
struct ziplist<T>{
int32 zlbytes;
int32 zltail_offset;
int16 zllemhth;
T[] entries;
int8 zlend;
}
其结构如下图所示:
节点结构如下:
struct entry{
int<var> previous_entry_length;//前一个原数的字节长度
int<var> encoding;//元数类型编码
optional byte[] content;//元素内容
}

这里有一个点要注意,如果entryX+1和起身后的节点的长度都都在250~253个字节之间的话,如果entryX长度变成了254个字节。那么entryX+1中的previous_entry_length将扩容成5个字节,
这将导致entryX+1的整体长度也会大于254个字节,引起entryX+2个字节中的previous_entry_length也发生扩容,使得entryX+2的整体长度也超过254。并对后面的节点造成连锁影响这个就叫连锁更新。
将会对性能造成一定的影响。
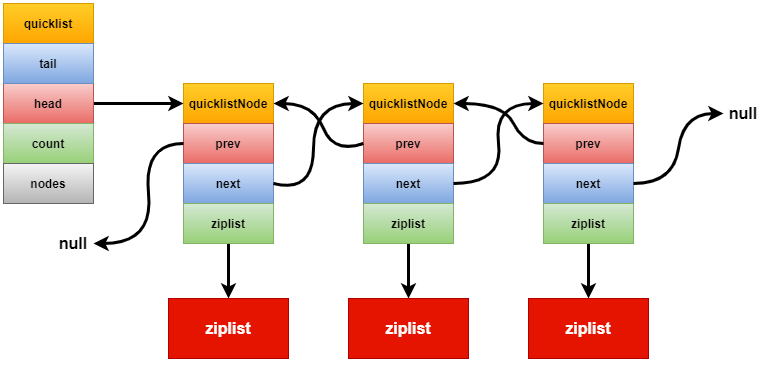
quicklist快速列表:
快速列表是ziplist和linkedlist的混合体。它将linkedlist按段切分,每一段使用ziplist让内存紧凑,多个ziplist之间使用双向指针串接起来。为了进一步节省空间。Redis还会对ziplist进行压缩,
使用LZF算法压缩。可以选择压缩的深度,默认的压缩深度是0既不压缩。有时候为了节省空间,但是又不想因为压缩而影响取出和放入的性能,可以选着压缩深度为1或者2。
既首尾的第一个或者首尾的第一个和第二个不压缩。
struct quicklist{
quicklistNode* head;//头节点
quicklistNode* tail;//尾节点
long count;//元素总数
int nodes;//ziplist 节点数量
int compressDepth;//LZF 算法压缩深度
};
struct quicklistNode{
quicklistNode* prev;//前一个节点
quicklistNode* next;//下一个节点
ziplist* zl;//指向压缩列表的指针
int32 size;//压缩列表的字节总数
int16 count;//压缩列表中的元素个数
int2 encoding;//存储形式 2bit 是原生字节数组还是被压缩过的
};
注:LZF算法是苹果开源的一种无损压缩算法,有兴趣的看官们可以自行去了解下,这里不做过多的赘述。
3.字典(dictht)
字典又称之为hash,或者映射(map),也可以理解为redis自己实现的JDK1.7版本的HashMap。是一种用于保存键值对的抽象数据结构。在字典中,一个键(Key)可以和一个值(value)进行关联,成为一个键值对。
字典中每个键都是唯一的。程序可以在字典中根据键查找与之关联的值,或者通过键来跟新或者删除值。接下来的内容将详细介绍Redis中字典的两种底层实现。
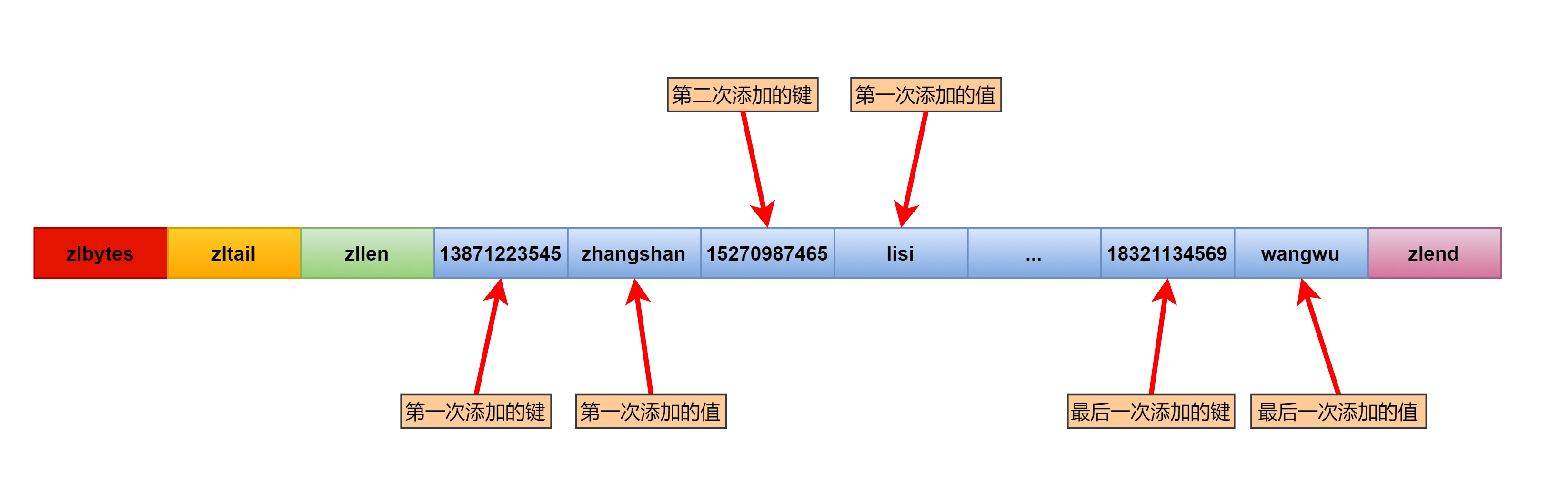
第一种:ziplist
当字典中的元素满足以下两个条件时,字典的底层将会使用ziplist来报错键值对。
1.字典对象保存的所有键值对的键和值的字符串长度都小于64个字节。
2.字段对象保存的键值对数量小于512个。
看到这里也许有的看官会不明白了。在上面我们刚刚学过ziplist压缩列表,大家都知道这其实就是一个数组。前面的列表可以用数组来保存,但是这里是键值对啊,一个map,怎么用数组来保存?
各位看官先莫慌,按照惯例先上图(毕竟无图无真相啊):
第二种:hash表
hash表顾名思义,其本质就是一个HashMap。下面我带各位看官们看看他的结构
typedef struct dict{
dictType *type;//类型特定函数
void *privdata;//私有函数
dictht ht[2];//hash表
int trehashidx;//扩容索引 当不在扩容的时候 为-1
};
typedef struct dictht{
dictEntry **table;//哈希表数组
unsigned long size;//哈希表大小
unsigned long sizemask;//哈希表槽位取模基准参数 总是等于size - 1
unsigned long used;//已有节点数量
}
typedef struct dictEntry{
void *key;//键
//值 这里三个属性是因为 值可能是一个对象引用也可能是 一个uint64_t或者int64_t整数值
union{
void *val;
uint64_t u64;
int64_t s64;
} v;
//下一个节点 多个槽位相同的值 串联成一个链表
struct dictEntry *next;
}
结构示意图:

渐进式rehash :
字典在扩容的过程中会在 ht[1] 创建一个新的哈希表,而且它并不会一次性将所有的数据都转移到新的哈希表之中。而是分而治之,像蚂蚁搬家一样,一部分一部分的迁移,我们称之为渐进式rehash。
因为篇幅原因,后面会写一篇专门的文章来详细说明渐进式rehash和在迁移过程中获取元素的方式,这里就简略的介绍一下。
4.集合(sets)
Redis集合中的Set集合,相当与java中的HashSet,它内部的键值对是无序的,唯一的。在Redis中Set集合底层也存在两种实现方式。
第一种,当一个集合只包含整数值元素,并且这个集合的元素数量不超过512时,Redis就会使用整数集合作为集合键的底层实现。
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元原数的数组
int8_t contents[];
};
contents数组是整数集合的底层实现:整数集合的每个元素都是contents数组的一个数组项(item),哥哥项在数组中按值的大小从小到大有序地排列,并且数组中不包含任何重复项。
length属性记录了整数集合包含的元素数量,也即是contents数组的长度。虽然intset结构将contents数组声明为int8_t类型的数组。但实际上contents数组的真正类型取决于encoding;
如果encoding类型为INTSET_ENC_INT16,那么contents就是一个int16_t类型的数组。
如果encoding类型为INTSET_ENC_INT32,那么contents就是一个int32_t类型的数组。
如果encoding类型为INTSET_ENC_INT64,那么contents就是一个int64_t类型的数组。

整数数组的升级:
当我们要将一个新的元素添加到集合中,并且新元素的类型比整数集合现有的所有元素类型都要长时。整数集合现有先进行升级,然后才能将新元素添加到整数集合里。
比如向一个包含1,2,3 的数组中插入一个65535;
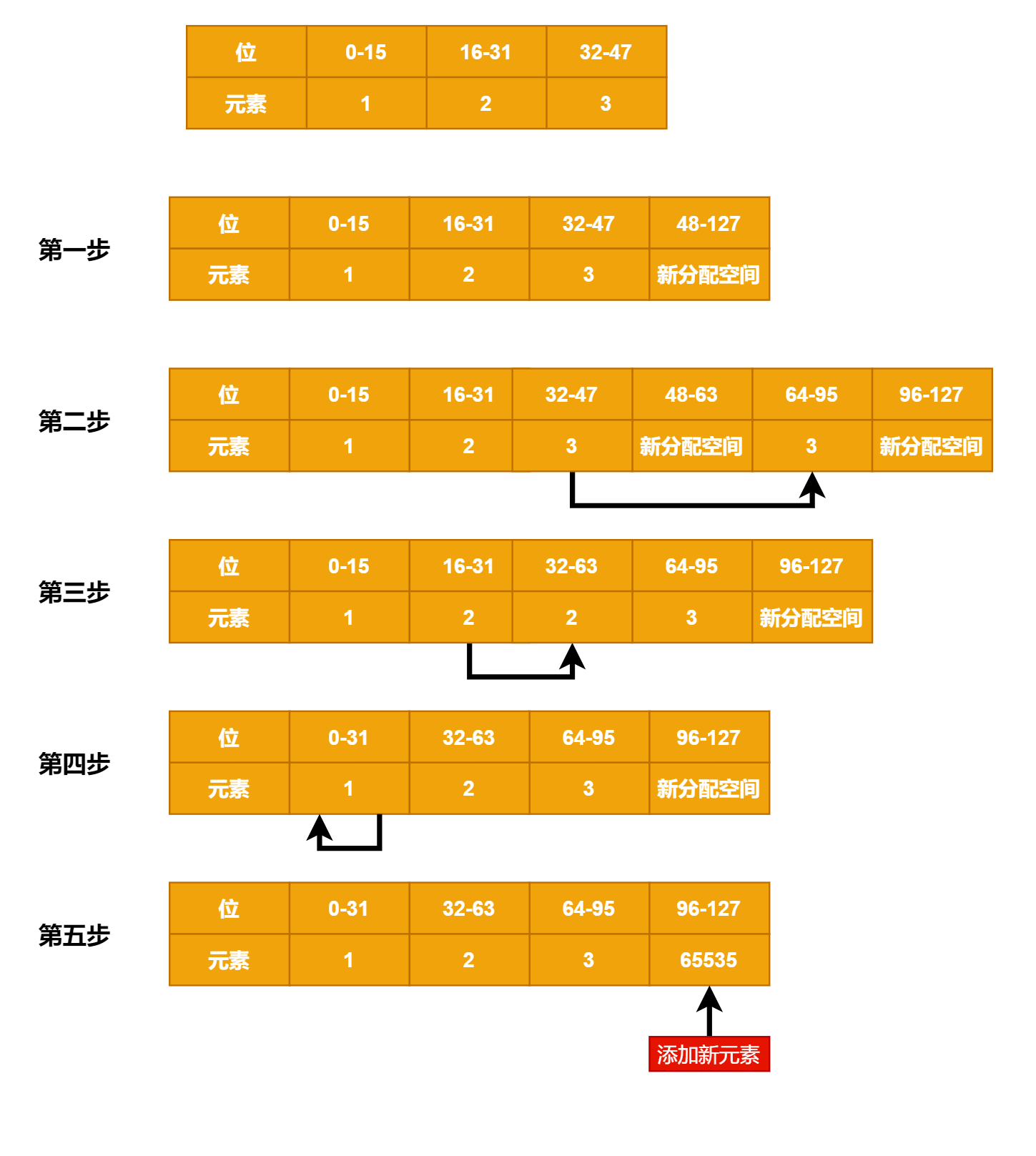
第二种使用字典实现,字典的每个键都是一个字符串对象,而值则全部被设置为Null;

5.有序集合(ZSet)
ZSet在Redis底层也存在两种实现,一种是简单实现通过Ziplist保存元素成员。
结构如下图所示:

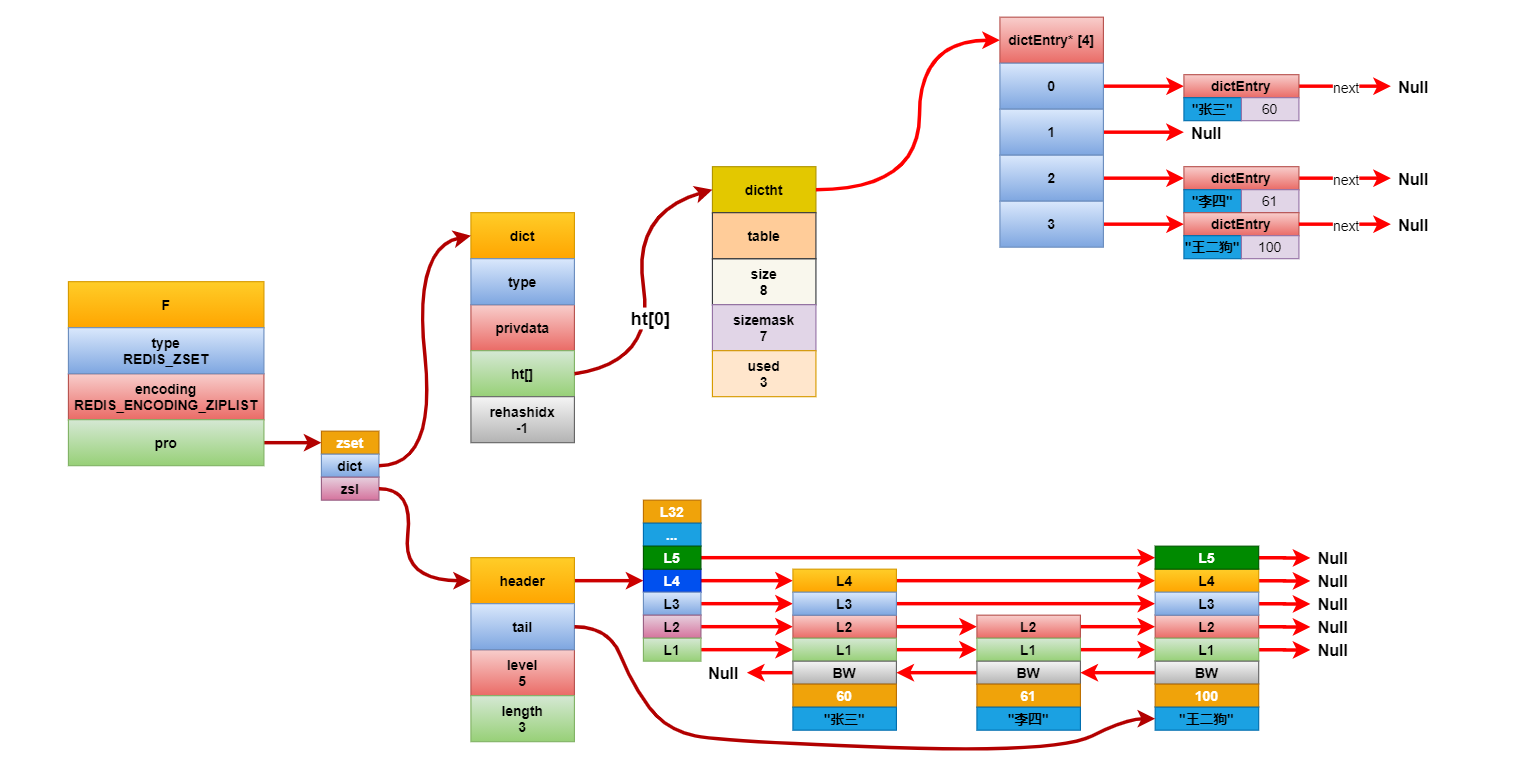
还一种是复杂模型,它内部保存有一个跳表和一个字典,通过字典来实现O(1)时间复杂度的元素查找,通过跳表来完成高性能的zrank、zrange等范围命令。如果单纯的字典,要完成zrange命令,
要先将所有数据排序,时间复杂度为O(nlogn),而且还需要长度为N的数组来保存排序完成的数据。如果单纯使用跳表,查询的时间复杂度为O(logn)。
结构如下图所示:
总结:
这五种只是最常用的五种数据结构,在Redis中还有其他类型的数据结构或者实现。比如紧凑列表listpack,基数树rax等还等待着我们去探索。
由于篇幅有限,这期就先到这里,预知后事如何,请听下集分解...
最新文章
- [原创]CSS3打造动态3D气球
- CentOS个人目录下中文路径转英文路径
- asp.net mvc 控制器中操作方法重载问题 解决
- Adobe Dreamweaver(DW)
- b2c项目基础架构分析(一)b2c 大型站点方案简述 已补充名词解释
- python 进程信息
- GOOGLE搜索從入門到精通V4.0
- StrokeStart与StrokeEnd动画
- java选择结构
- 17年年终总结——走过2017,迎来2018Flag
- Android 视频通信,低延时解决方案
- SpringBoot之SOAP WebService
- 关于istream_iterator<int>(cin)和istream_iterator<int>()的一点分析
- java使用DateUtils对日期进行运算
- input框中自动展示当前日期 yyyy/mm/dd
- usr/bin/X11各个程序中文详解
- IE8不支持数组的indexOf方法 如何解决
- Android—— 线程 thread 两种实现方法!(转)
- js中以键值对的形式当枚举
- 通用标签、属性(body属性、路径、格式控制)