【Python】【正则】
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程: 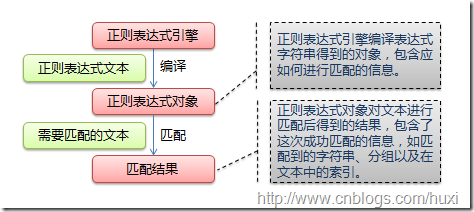
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法: 
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# encoding: UTF-8import re# 将正则表达式编译成Pattern对象pattern = re.compile(r'hello')# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回Nonematch = pattern.match('hello world!')if match: # 使用Match获得分组信息 print match.group()### 输出 #### hello |
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- S(DOTALL): 点任意匹配模式,改变'.'的行为
- L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
|
1
2
3
4
|
a = re.compile(r"""\d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X)b = re.compile(r"\d+\.\d*") |
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
|
1
2
|
m = re.match(r'hello', 'hello world!')print m.group() |
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 - groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 - groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 - end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import rem = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')print "m.string:", m.stringprint "m.re:", m.reprint "m.pos:", m.posprint "m.endpos:", m.endposprint "m.lastindex:", m.lastindexprint "m.lastgroup:", m.lastgroupprint "m.group(1,2):", m.group(1, 2)print "m.groups():", m.groups()print "m.groupdict():", m.groupdict()print "m.start(2):", m.start(2)print "m.end(2):", m.end(2)print "m.span(2):", m.span(2)print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')### output #### m.string: hello world!# m.re: <_sre.SRE_Pattern object at 0x016E1A38># m.pos: 0# m.endpos: 12# m.lastindex: 3# m.lastgroup: sign# m.group(1,2): ('hello', 'world')# m.groups(): ('hello', 'world', '!')# m.groupdict(): {'sign': '!'}# m.start(2): 6# m.end(2): 11# m.span(2): (6, 11)# m.expand(r'\2 \1\3'): world hello! |
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import rep = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)print "p.pattern:", p.patternprint "p.flags:", p.flagsprint "p.groups:", p.groupsprint "p.groupindex:", p.groupindex### output #### p.pattern: (\w+) (\w+)(?P<sign>.*)# p.flags: 16# p.groups: 3# p.groupindex: {'sign': 3} |
实例方法[ | re模块方法]:
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。 - search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。12345678910111213141516# encoding: UTF-8importre# 将正则表达式编译成Pattern对象pattern=re.compile(r'world')# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None# 这个例子中使用match()无法成功匹配match=pattern.search('hello world!')ifmatch:# 使用Match获得分组信息printmatch.group()### 输出 #### world - split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。1234567importrep=re.compile(r'\d+')printp.split('one1two2three3four4')### output #### ['one', 'two', 'three', 'four', ''] - findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。1234567importrep=re.compile(r'\d+')printp.findall('one1two2three3four4')### output #### ['1', '2', '3', '4'] - finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。12345678importrep=re.compile(r'\d+')forminp.finditer('one1two2three3four4'):printm.group(),### output #### 1 2 3 4 - sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。123456789101112131415importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.sub(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.sub(func, s)### output #### say i, world hello!# I Say, Hello World! - subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。123456789101112131415importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.subn(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.subn(func, s)### output #### ('say i, world hello!', 2)# ('I Say, Hello World!', 2)
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束
#【【正则表达式】】
'''
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。 正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。 所以我们判断一个字符串是否是合法的Email的方法是: 创建一个匹配Email的正则表达式; 用该正则表达式去匹配用户的输入来判断是否合法。 因为正则表达式也是用字符串表示的,所以,我们要首先了解如何用字符来描述字符。 在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,\w可以匹配一个字母或数字,所以: '00\d'可以匹配'007',但无法匹配'00A'; '\d\d\d'可以匹配'010'; '\w\w\d'可以匹配'py3'; .可以匹配任意字符,所以: 'py.'可以匹配'pyc'、'pyo'、'py!'等等。
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符: 来看一个复杂的例子:\d{3}\s+\d{3,8}。 我们来从左到右解读一下: \d{3}表示匹配3个数字,例如'010'; \s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等; \d{3,8}表示3-8个数字,例如'1234567'。 综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。 如果要匹配'010-12345'这样的号码呢?由于'-'是特殊字符,在正则表达式中,要用'\'转义,所以,上面的正则是\d{3}\-\d{3,8}。 但是,仍然无法匹配'010 - 12345',因为带有空格。所以我们需要更复杂的匹配方式。 进阶 要做更精确地匹配,可以用[]表示范围,比如: [0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线; [0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等; [a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量; [a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。 A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。 ^表示行的开头,^\d表示必须以数字开头。 $表示行的结束,\d$表示必须以数字结束。 你可能注意到了,py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。 ''' import re
print (re.match(r'^\d{3}\-\d{3,8}$','021-45678')) #<_sre.SRE_Match object; span=(0, 9), match='021-45678'>
print (re.match(r'^\d{3}\-\d{3,8}$','021 45678')) #None
print (re.match(r'^\d{3}-\d{3,8}$','011-3456')) #<_sre.SRE_Match object; span=(0, 8), match='011-3456'> # 切分字符串
#正常的切分代码无法识别连续的空格
print ('a b c'.split(' ')) #['a', 'b', '', '', 'c']
#正则
print (re.split(r'\s+','a b c')) #['a', 'b', 'c']
#正则,假如逗号
print (re.split(r'[\s\,]+','a,b, c')) #['a', 'b', 'c']
#再假如分号
print (re.split(r'[\s\,\;]+','a,b,; ; c')) #['a', 'b', 'c']
#【用途】如果用户输入了一组标签,可用正则来把不规范的输入转化成正确的数组 #分组
#除了简单的匹配判断,正则还有提取子串的功能。用()表示要提取的分组
m = re.match(r'^(\d{3})-(\d{3,8})$','021-34567')
print (m) #<_sre.SRE_Match object; span=(0, 9), match='021-34567'>
print (m.group(0)) #021-34567
print (m.group(1)) #021
print (m.group(2)) #34567 #再来看个更凶残的例子
t = '19:05:30'
m = re.match(r'(0[0-9]|1[0-9]|2[0-3]|[0-9]):(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9]):(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$',t)
print (m.groups()) #('19', '05', '30')
#【备注】这个正则可识别合法的时间。可有些时候,用正则也无法做到完全验证,比如识别日期。对于2-30 4-31这样的。 #贪婪匹配
#正则默认的是贪婪匹配。例子如下,匹配出数字后面的0
print (re.match(r'^(\d+)(0*)$','102300').groups()) #('102300', '')
'''
由于\d+采用贪婪匹配,直接把后面的0全都匹配了,结果0*只能匹配空字符串了
加个?就可以非贪婪匹配
'''
print (re.match(r'^(\d+?)(0*)$','102300').groups()) #('1023', '00') # 编译
'''
当我们在Python中使用正则表达式时,re模块内部会干两件事情: 编译正则表达式,如果正则表达式的字符串本身不合法,会报错; 用编译后的正则表达式去匹配字符串。 如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
'''
import re
#编译
re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
#使用
print (re_telephone.match('010-34567').groups()) #('010', '34567')
print (re_telephone.match('010-7896').groups()) #('010', '7896') # 练习题
'''
尝试写一个验证Email地址的正则表达式。版本一应该可以验证出类似的Email: someone@gmail.com
bill.gates@microsoft.com
版本二可以提取出带名字的Email地址: <Tom Paris> tom@voyager.org => Tom Paris
bob@example.com => bob
'''
import re regex = r'^(<\w[\s\w]+>\s)?(\w+[\w+.]*@\w+.(org|com)$)'
# 题目一:正则匹配
m = re.compile(regex)
# 纯Email地址
if m.match('someone@gmail.com'):
print('match someone@gmail.com')
if m.match('bill.gates@microsoft.com'):
print('match bill.gates@microsoft.com')
# 带名字的Email地址
if m.match('<Tom Paris> tom@voyager.org'):
print('match <Tom Paris> tom@voyager.org')
# 题目二:提取带名字的Email地址
m_email = m.match('<Tom Paris> tom@voyager.org').group(2)
最新文章
- Datazen介绍
- 基本数据类型-集合(set)_上周内容回顾(字符串_数字_列表_元组_字典_集合)
- 表现层的设计(一)——常用的模式、Json与DTO
- html+css源码之实现登录弹出框遮罩层效果
- Python脚本控制的WebDriver 常用操作 <二> 关闭浏览器
- null和空 not null
- xenserver 备份backup和还原restore命令
- linux 命令 备忘
- Axure草记
- 自定义图文混排视图MyImageTextView
- web安全记录
- 关系数据库标准语言SQL的基本问答
- loadrunner多负载机联合产生负载
- HTML5学习知识点
- 剑指offer——python【第38题】二叉树的深度
- duilib进阶教程 -- 在MFC中使用duilib (1)
- shell 多重条件判断
- 【Active入门-2】ActiveMQ学习-生产者与消费者
- Spring Boot 集成 Mybatis(druid 数据库连接池 以及 分页配置)
- kubernetes master 高可用一键部署