ElasticSearch 安装中文分词器
1、安装中文分词器IK
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
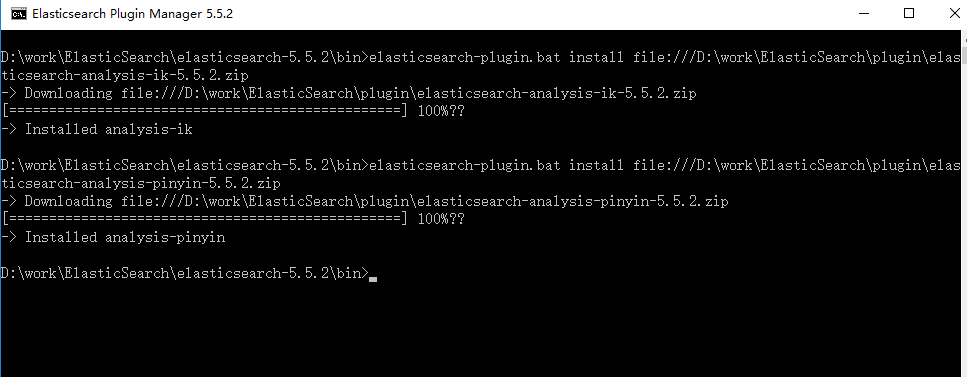
在线下载安装: elasticsearch-plugin.bat install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.2/elasticsearch-analysis-ik-5.5.2.zip
先下载后安装:elasticsearch-plugin.bat install file:///D:\work\ElasticSearch\plugin\elasticsearch-analysis-ik-5.5.2.zip

2、重启 elasticsearch
3、创建空索引
curl -XPUT http://127.0.0.1:9200/index_china

或
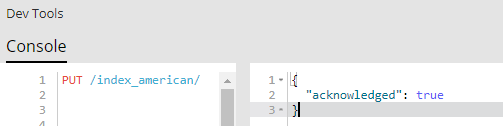
在kibana的Dev Tools中用 PUT /index_american/
4、创建映射
curl -XPOST http://127.0.0.1:9200/index_china/fulltext/_mapping -d "{\"properties\": {\"content\": {\"type\": \"text\",\"analyzer\": \"ik_max_word\",\"search_analyzer\": \"ik_max_word\"}}}"

或
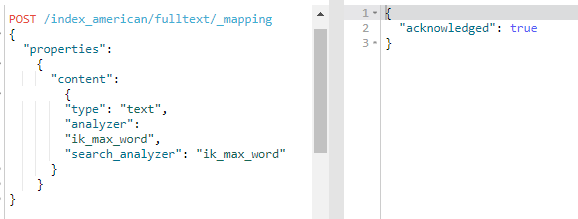
POST /index_american/fulltext/_mapping
{
"properties":
{
"content":
{
"type": "text",
"analyzer":
"ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
5、索引数据
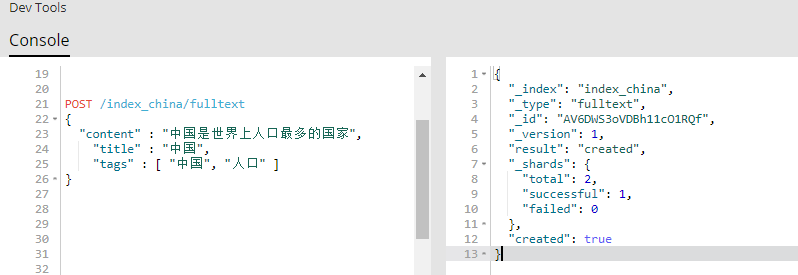
POST /index_china/fulltext
{
"content" : "中国是世界上人口最多的国家",
"title" : "中国",
"tags" : [ "中国", "人口" ]
}
批量索引数据
POST /_bulk
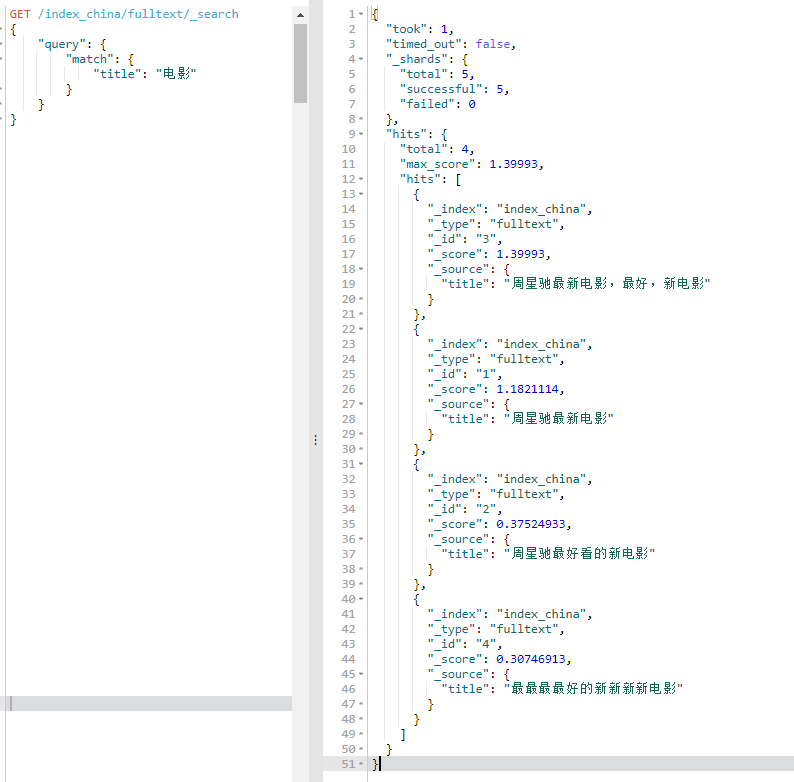
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "周星驰最新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "周星驰最好看的新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "周星驰最新电影,最好,新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "最最最最好的新新新新电影" }
{ "create": { "_index": "index_china", "_type": "fulltext", "_id": } }
{ "title": "I'm not happy about the foxes" }
6、查询
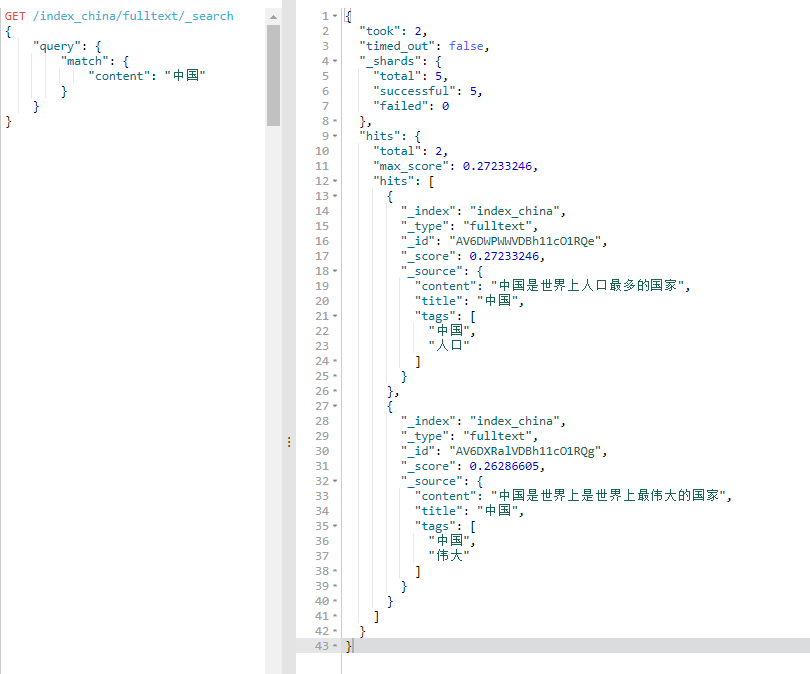
GET /index_china/fulltext/_search
{
"query": {
"match": {
"content": "中国"
}
}
}
7、最大分词和最小分词
ik_smart,
ik_max_word
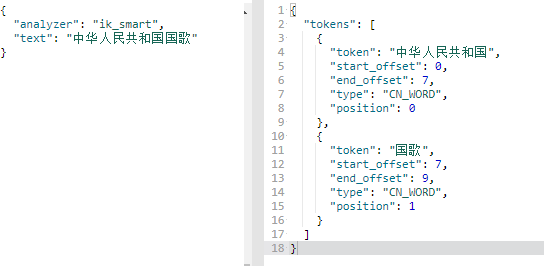

GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
#删除索引
DELETE /ott_test #创建索引 PUT /ott_test
{
"mappings": {
"ott_type" : {
"properties" : {
"title" : {
"type" : "text",
"index":true,
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"date" : {
"type" : "date"
},
"keyword" : {
"type" : "keyword"
},
"source" : {
"type" : "keyword"
},
"link" : {
"type" : "keyword"
}
}
}
}
} #索引数据
POST /ott_test/ott_type
{
"title":"微博新规惹争议:用户原创内容版权归属于微博?",
"link":"http://www.yidianzixun.com/article/0HHoxgVq",
"date":"2017-09-17",
"source":"虎嗅网",
"keyword":"内容"
} #分析
GET /ott_test/_analyze
{
"field": "title",
"text": "内容"
} #查询 GET /ott_test/ott_type/_search
{
"query": {
"match": {
"title": "内容"
}
}
} #只查询title和date两个字段的数据 GET /ott_test/ott_type/_search
{
"query": {"match_all": {}},
"_source": ["title","date"]
}
最新文章
- Python3.5 day3作业一:实现简单的shell sed替换功能
- mongodb的查询语句学习摘要
- struts.xml配置详解 内部资料 请勿转载 谢谢合作
- html5/css学习笔记
- TestNG官方文档中文版(5)-测试方法/类和组
- codevs 1082 线段树练习3
- jsp机制基础
- FIleReader无法解决编码问题
- uboot启动内核(3)
- Global::time2StrHHMM_DNT
- Android Activity形象描述
- ASP.NET页面不被缓存
- RDLC(Reportview)报表直接打印,支持所有浏览器,客户可在linux下浏览使用
- Uva 11300 Spreading the Wealth(递推,中位数)
- 20175224 2018-2019-2 《Java程序设计》第三周学习总结
- 数学模块_math
- Spring Web项目spring配置文件随服务器启动时自动加载
- SQL Server 数据类型映射(转载)
- Mysql存储引擎特性总结
- 总结:独立开发 jar 包组件——功能主要是支持查询数据库的所有表数据