Spark Streaming 交互 Kafka的两种方式
2024-09-03 00:15:28
一、Spark Streaming连Kafka(重点)
方式一:Receiver方式连:走磁盘
使用High Level API(高阶API)实现Offset自动管理,灵活性差,处理数据时,如果某一时刻数据量过大就会磁盘溢写,通过WALS(Write Ahead Logs)进行磁盘写入,0.10版本之后被舍弃,
相当于一个人拿着一个水杯去接水,水龙头的速度不定,水杯撑不下就会往盆(磁盘)中接。
zookeeper自动管理偏移量
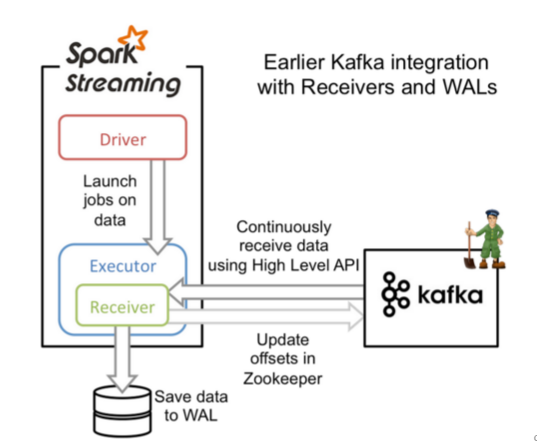
Receiver方式说明:Receiver会以固定的时间向kafka中通过zookeeper自动管理偏移量拉取数据,当拉取的数据过多Executor处理不完就会落入磁盘中,
方式二:Direct方式直连:不走磁盘
使用Direct API(底层API)实现Offset偏移量自定义管理,灵活性极高,保证了数据的安全性,不用担心数据量过大,因为它有预处理机制,进行提前处理,之后批次提交任务。
相当于将水管直接拉到了需要用的地方,中间有预处理机制。不经过磁盘
实现自己维护偏移量(偏移量可以保存到MySQL,Redis,zookeeper)中
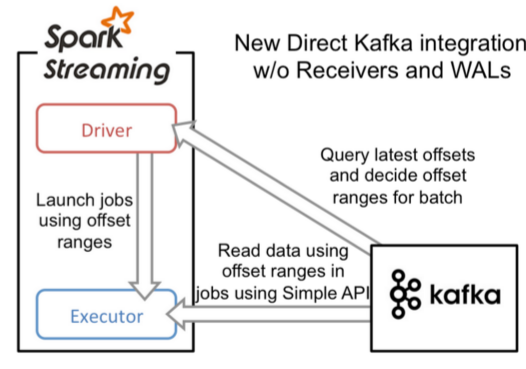
SparkStreaming的Receiver方式和Direct直连方式有什么区别?
Receiver接收固定时间间隔的数据(放在内存中的),使用Kafka高级到API,自动维护偏移量,达到固定的时间才进行处理,效率低并且容易丢失数据
Direct直连方式,相当于连接到Kafka的分区上,使用Kafka底层的API,效率高,需要自己维护偏移量。
最新文章
- MySQL数据库的初始化mysql_install_db 【基础巩固】
- JQUERY UI Datepicker Demo
- java-sql注入攻击
- ubuntu13.04下建立嵌入式开发平台
- MySQL主从复制与读写分离
- C#设计模式(11)——外观模式(Facade Pattern)
- 关于Java的this关键字
- 【spring-boot】快速构建spring-boot微框架
- SPRING IN ACTION 第4版笔记-第四章ASPECT-ORIENTED SPRING-003-Spring对AOP支持情况的介绍
- Hadoop最基本的wordcount(统计词频)
- Ubuntu下tomcat或eclipse启动提示没有java环境问题
- Install OpenCV 3.0 and Python 2.7+ on OSX
- SQL2005打SP4补丁报错:无法安装Windows Installer MSP文件解决方案
- OpenCV-Python:K值聚类
- 51Nod - 1046 (附关于快速幂的讨论)
- Docker在Linux上运行NetCore系列(一)配置运行DotNetCore控制台
- Vim auto-pairs设置选项
- ArcGIS地图文档优化 mxdPerfstat工具使用体验
- 自学工业控制网络之路1.5-典型的现场总线介绍DeviceNet
- 【linux】之查看物理CPU个数、核数、逻辑CPU个数
热门文章
- java 使用Queue在队列中异步执行任务
- dos命令执行mysql的sql文件
- 在CentOS的profile文件中配置环境变量
- 赶集网mysql开发36条军规
- poi读取excel的辅助类
- Row_number() OVER(PARTITION BY xxx ORDER BY XXX)分组排序
- Mybatis:Reader entry: ���� 4
- php的yii框架开发总结5
- Python基础学习之字符串(1)
- 其他信息: 尝试加载 Oracle 客户端库时引发 BadImageFormatException。如果在安装 32 位 Oracle 客户端组件的情况下以 64 位模式运行,将出现此问题。在VS中的解决方法