Python的scrapy之爬取顶点小说网的所有小说
2024-08-27 18:00:43
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息。
看一下网页的构造:
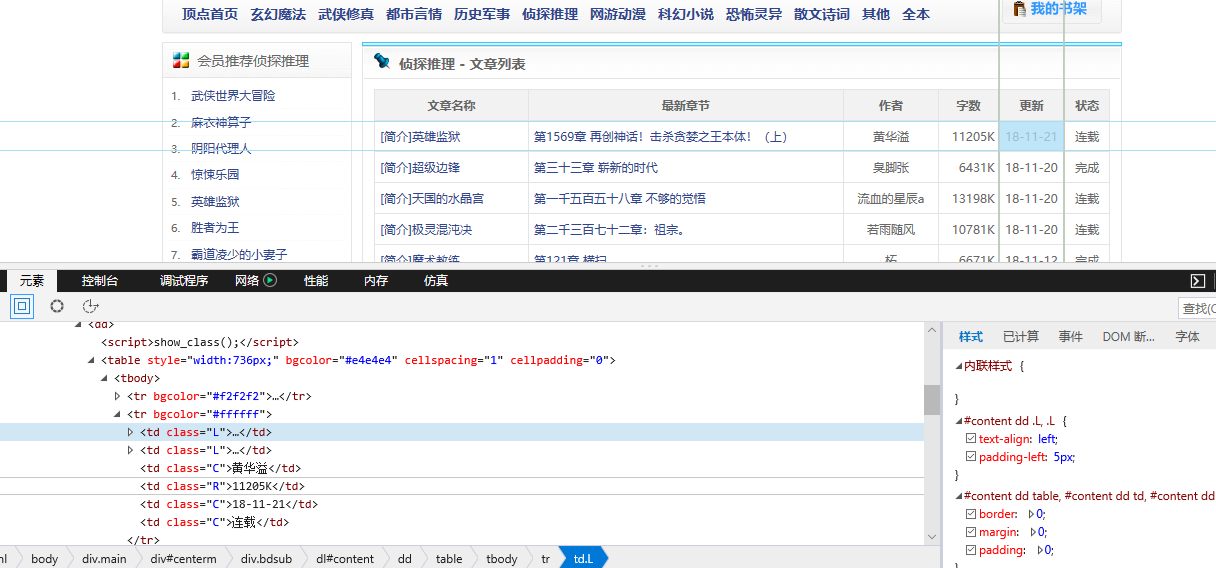
tr标签里面的 td 使我们所要爬取的信息
下面是我们要爬取的二级页面 小说的简介信息:
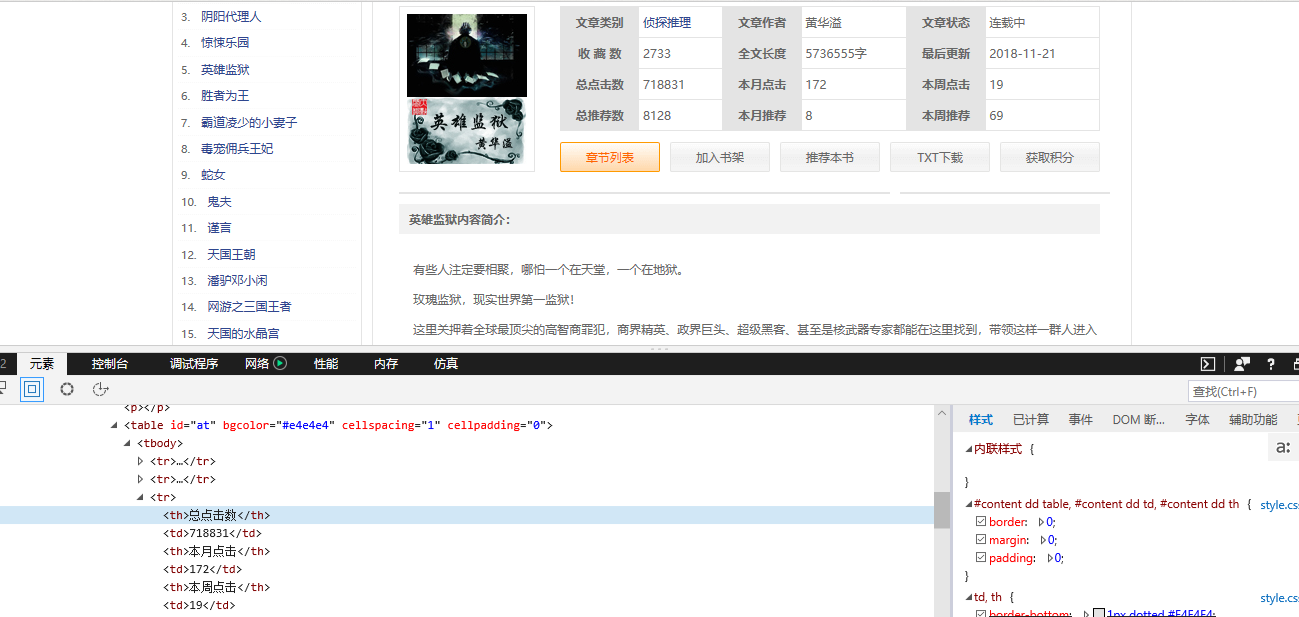
下面上代码:
mydingdian.py
import scrapy
from scrapy.http import Request
from ..items import DingdianItem class MydingdianSpider(scrapy.Spider):
name = 'mydingdian'
allowed_domains = ['www.x23us.com/']
start_url = ['https://www.x23us.com/class/']
starturl=['.html'] def start_requests(self):
# for i in range(1,11):
for i in range(5, 6):
#print(i)
url_con=str(i)+'_1'
#print(url_con)
url1 = self.start_url+list(url_con)+self.starturl
#print(url1)
url=''
for j in url1:
url+=j+''
#print(url)
yield Request(url, self.parse) def parse(self, response): baseurl=response.url #真正的url链接
#print(baseurl)
max_num = response.xpath('//*[@id="pagelink"]/a[14]/text()').extract_first() # 获取当前页面的最大页码数
#print(max_num) #页码数
baseurl = baseurl[:-7]
#print(baseurl) for num in range(1,int(max_num)+1):
#for num in range(1, 5):
#print(list("_" + str(num)))
newurl1 = list(baseurl) + list("_" + str(num)) + self.starturl
#print(newurl1)
newurl=''
for j in newurl1:
newurl+=j+''
print(newurl)
# 此处使用dont_filter和不使用的效果不一样,使用dont_filter就能够抓取到第一个页面的内容,不用就抓不到
# scrapy会对request的URL去重(RFPDupeFilter),加上dont_filter则告诉它这个URL不参与去重。
yield Request(newurl, dont_filter=True, callback=self.get_name) # 将新的页面url的内容传递给get_name函数去处理 def get_name(self,response):
item=DingdianItem()
for nameinfo in response.xpath('//tr'):
#print(nameinfo)
novelurl = nameinfo.xpath('td[1]/a/@href').extract_first() # 小说地址
#print(novelurl)
name = nameinfo.xpath('td[1]/a[2]/text()').extract_first() # 小说名字
#print(name)
newchapter=nameinfo.xpath('td[2]/a/text()').extract_first() #最新章节
#print(newchapter)
date=nameinfo.xpath('td[5]/text()').extract_first() #更新日期
#print(date)
author = nameinfo.xpath('td[3]/text()').extract_first() # 小说作者
#print(author)
serialstatus = nameinfo.xpath('td[6]/text()').extract_first() # 小说状态
#print(serialstatus)
serialsize = nameinfo.xpath('td[4]/text()').extract_first() # 小说大小
#print(serialnumber)
#print('--==--'*10)
if novelurl:
item['novel_name'] = name
#print(item['novel_name'])
item['author'] = author
item['novelurl'] = novelurl
#print(item['novelurl'])
item['serialstatus'] = serialstatus
item['serialsize'] = serialsize
item['date']=date
item['newchapter']=newchapter print('小说名字:', item['novel_name'])
print('小说作者:', item['author'])
print('小说地址:', item['novelurl'])
print('小说状态:', item['serialstatus'])
print('小说大小:', item['serialsize'])
print('更新日期:', item['date'])
print('最新章节:', item['newchapter']) print('===='*5) #yield Request(novelurl,dont_filter=True,callback=self.get_novelcontent,meta={'item':item})
yield item
'''
def get_novelcontent(self,response):
#print(123124) #测试调用成功url
item=response.meta['item']
novelurl=response.url
#print(novelurl)
serialnumber = response.xpath('//tr[2]/td[2]/text()').extract_first() # 连载字数
#print(serialnumber)
category = response.xpath('//tr[1]/td[1]/a/text()').extract_first() # 小说类别
#print(category)
collect_num_total = response.xpath('//tr[2]/td[1]/text()').extract_first() # 总收藏
#print(collect_num_total)
click_num_total = response.xpath('//tr[3]/td[1]/text()').extract_first() # 总点击
novel_breif = response.xpath('//dd[2]/p[2]').extract_first() #小说简介 # item['serialnumber'] = serialnumber
# item['category'] = category
# item['collect_num_total']=collect_num_total
# item['click_num_total']=click_num_total
# item['novel_breif']=novel_breif
#
# print('小说字数:', item['serialnumber'])
# print('小说类别:', item['category'])
# print('总收藏:', item['collect_num_total'])
# print('总点击:', item['click_num_total'])
# print('小说简介:', item['novel_breif'])
# print('===='*10) yield item
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class DingdianItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
novel_name = scrapy.Field() # 小说名字
author = scrapy.Field() # 作者
novelurl = scrapy.Field() # 小说地址
serialstatus = scrapy.Field() # 状态
serialsize = scrapy.Field() # 连载大小
date=scrapy.Field() #小说日期
newchapter=scrapy.Field() #最新章节 serialnumber = scrapy.Field() # 连载字数
category = scrapy.Field() # 小说类别
collect_num_total = scrapy.Field() # 总收藏
click_num_total = scrapy.Field() # 总点击
novel_breif = scrapy.Field() # 小说简介
插入数据库的管道 iopipelines.py
from 爬虫大全.dingdian.dingdian import dbutil # 作业: 自定义的管道,将完整的爬取数据,保存到MySql数据库中
class DingdianPipeline(object):
def process_item(self, item, spider):
dbu = dbutil.MYSQLdbUtil()
dbu.getConnection() # 开启事物 # 1.添加
try:
#sql = "insert into movies (电影排名,电影名称,电影短评,评价分数,评价人数)values(%s,%s,%s,%s,%s)"
sql = "insert into ebook (novel_name,author,novelurl,serialstatus,serialsize,ebookdate,newchapter)values(%s,%s,%s,%s,%s,%s,%s)"
#date = [item['rank'],item['title'],item['quote'],item['star']]
#dbu.execute(sql, date, True)
dbu.execute(sql, (item['novel_name'],item['author'],item['novelurl'],item['serialstatus'],item['serialsize'],item['date'],item['newchapter']),True)
#dbu.execute(sql,True)
dbu.commit()
print('插入数据库成功!!')
except:
dbu.rollback()
dbu.commit() # 回滚后要提交
finally:
dbu.close()
return item
settings.py
# -*- coding: utf-8 -*- # Scrapy settings for dingdian project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'dingdian' SPIDER_MODULES = ['dingdian.spiders']
NEWSPIDER_MODULE = 'dingdian.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'dingdian (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 2 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'dingdian.middlewares.DingdianSpiderMiddleware': 543,
} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'dingdian.middlewares.DingdianDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None,
'dingdian.rotate_useragent.RotateUserAgentMiddleware' :400
} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'dingdian.pipelines.DingdianPipeline': 300,
#'dingdian.iopipelines.DingdianPipeline': 301,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' LOG_LEVEL='INFO'
LOG_FILE='dingdian.log'
在往数据库插入数据的时候 ,我遇到了
pymysql.err.InterfaceError: (0, '') 这种问题,百度了好久才解决。。。
那是因为scrapy异步的存储的原因,太快。
解决方法:只要放慢爬取速度就能解决,setting.py中设置 DOWNLOAD_DELAY = 2
详细代码 附在Github上了
tyutltf/dingdianbook: 爬取顶点小说网的所有小说信息 https://github.com/tyutltf/dingdianbook
最新文章
- 【代码笔记】iOS-图片旋转
- Redis 数据类型-List
- 人性的弱点&&影响力
- Help Viewer 2.2 独立运行
- appium 常用api介绍(2)
- hdu 1050 Moving Tables 解题报告
- I-frame、B-frame、P-frame及DTS、PTS的关系(转)
- hdu 2112 HDU Today (最短路,字符处理)
- C#学习1
- 导入showb时候出错--2015-12-4
- HDU1510 White rectangles
- 老李分享:Eclipse中开发性能测试loadrunner脚本
- css3中的动画效果
- 201521123087 《Java程序设计》第11周学习总结
- 快速排序算法分析--C++版
- 【一天一道LeetCode】#8. String to Integer (atoi)
- Ubuntu上部署tomcat后无法访问8080端口问题
- mysql 开发进阶篇系列 26 数据库RPM安装演示
- VS2008版本引入第三方dll无强签名
- ES6-循环