ForkJoin
概述
从JDK1.7开始,Java提供Fork/Join框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
这种思想和MapReduce很像(input --> split --> map --> reduce --> output)
主要有两步:
- 第一、任务切分;
- 第二、结果合并
它的模型大致是这样的:线程池中的每个线程都有自己的工作队列(PS:这一点和ThreadPoolExecutor不同,ThreadPoolExecutor是所有线程公用一个工作队列,所有线程都从这个工作队列中取任务),当自己队列中的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。
工作窃取(work-stealing)
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
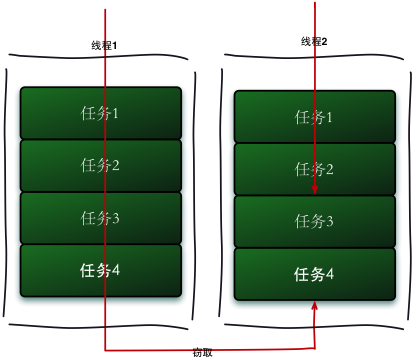
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
ForkJoinPool与其它的ExecutorService区别主要在于它使用“工作窃取”。
ForkJoinTask
ForkJoinTask代表运行在ForkJoinPool中的任务。
主要方法:
- fork() 在当前线程运行的线程池中安排一个异步执行。简单的理解就是再创建一个子任务。
- join() 当任务完成的时候返回计算结果。
- invoke() 开始执行任务,如果必要,等待计算完成。
子类:
- RecursiveAction 一个递归无结果的ForkJoinTask(没有返回值)
- RecursiveTask 一个递归有结果的ForkJoinTask(有返回值)
ForkJoinWorkerThread
ForkJoinWorkerThread代表ForkJoinPool线程池中的一个执行任务的线程。
类图
Contended
即:缓存行与伪共享
如果看过 类似 disrupter 这种高效率队列的开源实现,大家肯定会对cache line记忆犹新,他们通常的做法自己设置伪变量来填充,jdk1.8�中官网为我们带来了sun.misc.Contended,所以你如果阅读ForkJoinPool源码可以发现该类也被sun.misc.Contended标识。
ForkJoinPool
WorkQueue是一个ForkJoinPool中的内部类,它是线程池中线程的工作队列的一个封装,支持任务窃取。
什么叫线程的任务窃取呢?就是说你和你的一个伙伴一起吃水果,你的那份吃完了,他那份没吃完,那你就偷偷的拿了他的一些水果吃了。存在执行2个任务的子线程,这里要讲成存在A,B两个个WorkQueue在执行任务,A的任务执行完了,B的任务没执行完,那么A的WorkQueue就从B的WorkQueue的ForkJoinTask数组中拿走了一部分尾部的任务来执行,可以合理的提高运行和计算效率。
每个线程都有一个WorkQueue,而WorkQueue中有执行任务的线程(ForkJoinWorkerThread owner),还有这个线程需要处理的任务(ForkJoinTask<?>[] array)。那么这个新提交的任务就是加到array中。
ForkJoinWorkerThread
ForkJoinWorkThread持有ForkJoinPool和ForkJoinPool.WorkQueue的引用,以表明该线程属于哪个线程池,它的工作队列是哪个。
使用示例
package bingfa; import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask; /**
* 数字相加
*/
public class ForkJoinTest extends RecursiveTask<Long> { private static final long serialVersionUID = 8396165282949096335L; private static int thresold = 2; private long start; private long end; public ForkJoinTest(long start, long end) {
if (start < end) {
this.start = start;
this.end = end;
} else {
this.start = end;
this.end = start;
}
} @Override
protected Long compute() {
long sum = 0;
boolean canCompute = (end - start) <= thresold;
if (canCompute) {
for (long i = start; i <= end; i++)
{
sum += i;
}
} else {
long mid = (start + end) >> 1;
ForkJoinTest leftTask = new ForkJoinTest(start, mid);
ForkJoinTest rightTask = new ForkJoinTest(mid + 1, end); // 执行子任务
// leftTask.fork();
// rightTask.fork();
invokeAll(leftTask, rightTask); sum = leftTask.join() + rightTask.join();
}
return sum;
} public static void main(String[] args) throws Exception {
ForkJoinPool.commonPool();
ForkJoinPool forkjoinPool = new ForkJoinPool(1);
ForkJoinTest task = new ForkJoinTest(1, 10000);
ForkJoinTask<Long> future = forkjoinPool.submit(task);
System.out.println(future.get());
System.out.println(forkjoinPool.getPoolSize());
}
}
api文档中的两个示例:
package bingfa; import java.util.Arrays;
import java.util.concurrent.*; /**
* 归并
*/
public class RecursiveActionDemo { private static class SortTask extends RecursiveAction { static final int THRESHOLD = 100; final long[] array;
final int lo, hi; public SortTask(long[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
} public SortTask(long[] array) {
this(array, 0, array.length);
} public void sortSequentially(int lo, int hi) {
Arrays.sort(array, lo, hi);
} public void merge(int lo, int mid, int hi) {
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++) {
array[j] = (k == hi || buf[i] < array[k]) ? buf[i++] : array[k++];
}
} @Override
protected void compute() {
if (hi - lo < THRESHOLD) {
sortSequentially(lo, hi);
}else {
int mid = (lo + hi) >>> 1;
invokeAll(new SortTask(array, lo, mid), new SortTask(array, mid, hi));
merge(lo, mid, hi);
}
}
} public static void main(String[] args) throws ExecutionException, InterruptedException {
long[] array = new long[120];
for (int i = 0; i < array.length; i++) {
array[i] = (long) (Math.random() * 1000);
}
System.out.println(Arrays.toString(array)); ForkJoinPool pool = new ForkJoinPool();
pool.submit(new SortTask(array));
pool.awaitTermination(5, TimeUnit.SECONDS);
pool.shutdown();
System.out.println(Arrays.toString(array));
} }
package com.cjs.boot.demo;
import java.util.concurrent.*;
public class RecursiveTaskDemo {
private static class Fibonacci extends RecursiveTask<Integer> {
final int n;
public Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}else {
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 1);
return f2.compute() + f1.join();
}
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
ForkJoinPool pool = new ForkJoinPool();
Future<Integer> future = pool.submit(new Fibonacci(10));
System.out.println(future.get());
pool.shutdown();
}
}
错误范例
protected Long compute() {
if (任务足够小?) {
return computeDirect();
}
// 任务太大,一分为二:
SumTask subtask1 = new SumTask(...);
SumTask subtask2 = new SumTask(...);
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
// 合并结果:
Long subresult1 = subtask1.join();
Long subresult2 = subtask2.join();
return subresult1 + subresult2;
}
DK用来执行Fork/Join任务的工作线程池大小等于CPU核心数。在一个4核CPU上,最多可以同时执行4个子任务。对400个元素的数组求和,执行时间应该为1秒。但是,换成上面的代码,执行时间却是两秒。
这是因为执行compute()方法的线程本身也是一个Worker线程,当对两个子任务调用fork()时,这个Worker线程就会把任务分配给另外两个Worker,但是它自己却停下来等待不干活了!这样就白白浪费了Fork/Join线程池中的一个Worker线程,导致了4个子任务至少需要7个线程才能并发执行。
打个比方,假设一个酒店有400个房间,一共有4名清洁工,每个工人每天可以打扫100个房间,这样,4个工人满负荷工作时,400个房间全部打扫完正好需要1天。
Fork/Join的工作模式就像这样:首先,工人甲被分配了400个房间的任务,他一看任务太多了自己一个人不行,所以先把400个房间拆成两个200,然后叫来乙,把其中一个200分给乙。
紧接着,甲和乙再发现200也是个大任务,于是甲继续把200分成两个100,并把其中一个100分给丙,类似的,乙会把其中一个100分给丁,这样,最终4个人每人分到100个房间,并发执行正好是1天。
如果换一种写法:
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
这个任务就分!错!了!
比如甲把400分成两个200后,这种写法相当于甲把一个200分给乙,把另一个200分给丙,然后,甲成了监工,不干活,等乙和丙干完了他直接汇报工作。乙和丙在把200分拆成两个100的过程中,他俩又成了监工,这样,本来只需要4个工人的活,现在需要7个工人才能1天内完成,其中有3个是不干活的。
其实,我们查看JDK的invokeAll()方法的源码就可以发现,invokeAll的N个任务中,其中N-1个任务会使用fork()交给其它线程执行,但是,它还会留一个任务自己执行,这样,就充分利用了线程池,保证没有空闲的不干活的线程。
最新文章
- TYPESDK手游聚合SDK服务端设计思路与架构之一:应用场景分析
- 使用Apache Server 的ab进行web请求压力测试
- SeleniumIDE从0到1 (Selenium IDE 回放)
- crack.vbs病毒,优盘里所有文件全变成快捷方式
- 如何解读SQL Server日志(2/3)
- Hadoop I/O操作原理整理
- 第一篇 SQL Server安全概述
- 30天轻松学习javaweb_模拟tomcat
- Android:监听ListView
- ASP.NET页面生命周期总结(2)
- KindEditor放在包含模版页的页面里不显示解决方案
- LoadRunner日志(归档记录,以便自己查阅)
- angularjs1.6.4中使用ng-table出现data.slice is not a function的问题
- Java VisualVM无法检测到本地java程序 的 解决办法
- C-Free 5.0 注册码
- vue 常用语法糖
- Java多线程之实现Runnable接口
- shell怎么判断两个文件内容是否相同
- Morris
- HttpClient之EntityUtils对象