linux - word frequency
2024-09-21 07:42:24
linux 输出某个文件的单词出现频率
解决方式
cat words.txt |awk '{for(i=1;i<=NF;i++) print $i;}'|sort|uniq -c|sort -r|awk '{print $2,$1;}'
1、读出文件 cat xxx.txt

2、awk 逐行读入,按空格将每行分割 然后处理 (awk 常用命令参考 https://www.cnblogs.com/xiaoleiel/p/8349487.html)
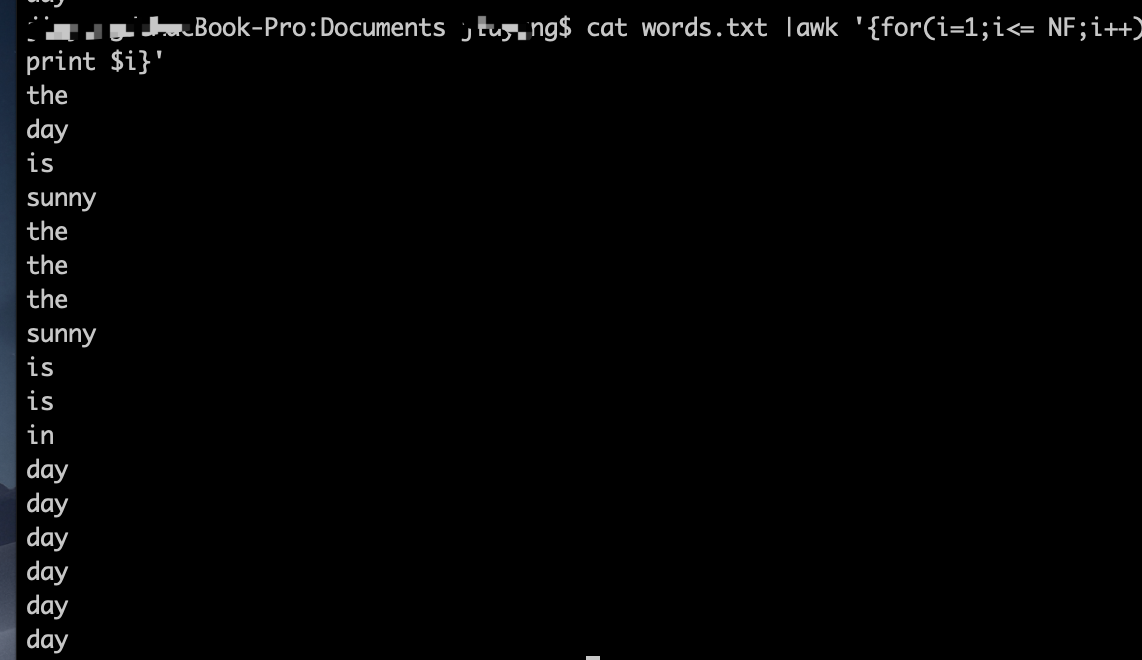
awk NF 每一行的单词数量
'{for(i=1;i<= NF;i++)print $i}' 逐行逐词输出单词
3、sort 按词排序,将相同的词语放在一起

4、uniq -c 按词统计次数
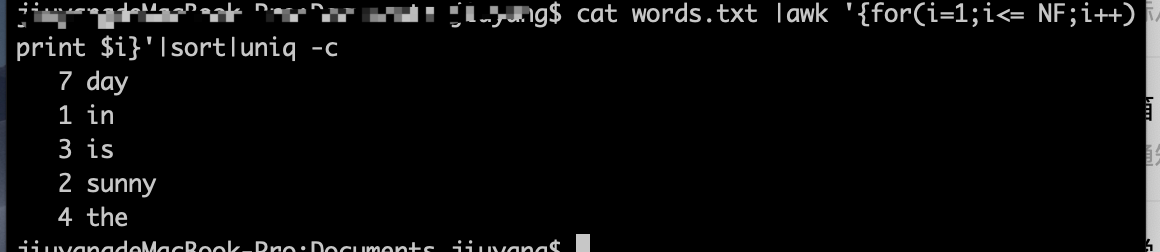
5、sort -r 按照第一行 倒叙排序

6、 awk '{print $2,$1}' 按照格式输出

sort 命令参数 http://www.runoob.com/linux/linux-comm-sort.html
参 数:
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
--help 显示帮助。
--version 显示版本信息
uniq http://www.runoob.com/linux/linux-comm-uniq.html
语法
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][--help][--version][输入文件][输出文件] 参数:
-c或--count 在每列旁边显示该行重复出现的次数。
-d或--repeated 仅显示重复出现的行列。
-f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
-s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
-u或--unique 仅显示出一次的行列。
-w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
--help 显示帮助。
--version 显示版本信息。
[输入文件] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据;
[输出文件] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
最新文章
- flash小游戏在Kongregate上线——BasketBall Master(篮球大师)
- 面试题目——《CC150》树与图
- JS通过身份证号码获取出生年月日
- Qt配置信息设置(QSettings在不同平台下的使用路径)
- c语言 typedef
- 纯HTML页面为了避免频繁前后台Ajax交互方案
- SqlServer2000下实现行列转换
- k-means均值聚类算法(转)
- commands - `tar`
- QT QTextBrowser
- 200 OK (from cache)原因
- 标准IO:常用函数集合
- Android 消息机制 (Handler、Message、Looper)
- c++只能编译无法运行或许缺少命令
- 谷歌浏览器安装json格式化插件
- 原来这就是 UI 设计师的门槛
- 软件工程(FZU2015) 赛季得分榜,第七回合
- Reservoir sampling
- 201671010142 java类与对象的定义及使用
- RIDE 接口自动化请求体参数中文时报错:“UnicodeDecodeError: 'ascii' codec can't decode byte 0xd7 in position 9......”