搭建hadoop集群 单机版
二、在Ubuntu下创建hadoop用户组和用户
1、创建hadoop用户组
- sudo su //进入管理员root用户
- sudo addgroup hadoop
2、创建hadoop用户
- sudo adduser –ingroup hadoop hadoop
3、给hadoop用户添加权限,打开/etc/sudoers文件
- sudo gedit /etc/sudoers
三、在Ubuntu下安装JDK
- 由于下面使用的是hadoop2.7.3,所以此处至少安装JDK1.7
- 记得先切换成hadoop用户
在Ubuntu下安装JDK图文解析 : http://blog.csdn.net/chongxin1/article/details/68957808
四、修改机器名
1、打开/etc/hostname文件
- sudo su
- sudo gedit /etc/hostname
2、将/etc/hostname文件中的yangcx-virtual-machine改为你想取的机器名
- sudo gedit /etc/hosts
为了后面在windows系统中调用linux系统的hadoop服务,所以应该把127.0.0.1修改为实际IP地址,如:192.168.168.200
五、安装ssh服务
此处采用在线安装方法,所以首先要保证Ubuntu系统能够上网。
VMware Ubuntu如何连接互联网: http://blog.csdn.net/chongxin1/article/details/68959150
1、更新源列表
- sudo apt-get update
2、安装ssh
- sudo apt-get install openssh-server
3、查看ssh服务是否启动
- sudo ps -e |grep ssh
六、建立ssh无密码登录本机
1、创建ssh-key,,这里我们采用rsa方式
- ssh-keygen -t rsa -P "" //(P是要大写的,后面跟"")
2、进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的
- cd ~/.ssh
- cat id_rsa.pub >> authorized_keys
3、登录localhost
- ssh localhost
4、执行退出命令
- exit
七、下载hadoop
hadoop百度网盘下载地址:http://pan.baidu.com/s/1pKQsHJ1
官网下载地址:http://hadoop.apache.org/
下载步骤一:
找到"Getting Started" ----->"Download Hadoop from the release page"
下载步骤二:
找到"Download the release hadoop-X.Y.Z-src.tar.gz from a mirror site
下载步骤三:
下载步骤四:
八、安装Hadoop
1、假设hadoop-2.7.3.tar.gz在桌面,将它复制到安装目录 /usr/local/下1
- sudo cp hadoop-2.7.3.tar.gz /usr/local
2、解压hadoop-2.7.3.tar.gz
- cd /usr/local/
- sudo tar -zxf hadoop-2.7.3.tar.gz
3、将解压出的文件夹改名为hadoop
- sudo mv hadoop-2.7.3 hadoop
4、将该hadoop文件夹的属主用户设为hadoop
- sudo chown -R hadoop:hadoop hadoop
5、打开hadoop/etc/hadoop/hadoop-env.sh文件
- cd hadoop/etc/hadoop
- sudo gedit hadoop-env.sh
6、配置hadoop/etc/hadoop/hadoop-env.sh(找到#export JAVA_HOME=...,去掉,然后加上本机jdk的路径)
把 ${JAVA_HOME} 修改为本机JDK实际的路径
7、打开hadoop/etc/hadoop/core-site.xml文件,编辑如下:
- sudo gedit core-site.xml
- <property>
- <name>fs.default.name</name>
- <value>hdfs://192.168.168.200:9000</value>
- </property>
192.168.168.200 : 本机IP地址,此处不用localhost,为了在windows能够访问
9000:默认端口
8、打开hadoop/etc/hadoop/mapred-site.xml文件,编辑如下:
- //复制并重命名
- cp mapred-site.xml.template mapred-site.xml
- //编辑器打开此新建文件
- sudo gedit mapred-site.xml
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>localhost:9001</value>
- </property>
- </configuration>
9、打开hadoop/etc/hadoop/hdfs-site.xml文件,编辑如下:
- sudo gedit hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.name.dir</name>
- <value>/usr/local/hadoop/namenode</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/usr/local/hadoop/datanode</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
九、在单机上运行hadoop
1、格式化hdfs文件系统
- cd /usr/local/hadoop
- bin/hadoop namenode -format
2、启动hdfs
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh
- jps
3、快捷启动配置
- //配置hadoop环境变量
- sudo gedit /etc/profile
- export HADOOP_HOME=/usr/local/hadoop
- export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
之后即可直接调用start-dfs.sh启动hadoop,无需进入hadoop的安装目录。
4、停止hdfs
- ./sbin/stop-dfs.sh
十、测试hadoop是否安装成功
1、测试用浏览器访问: http://localhost:50070 或者 http://192.168.168.200:50070
2、上传文件测试
- Hello World
- Hello Tom
- Hello Jack
- Hello Hadoop
- Bye hadoop
- bin/hadoop fs -put words.txt /
3、配置启动YARN
①配置etc/hadoop/mapred-site.xml:
- mv mapred-site.xml.template mapred-site.xml
- <configuration>
- <!-- 通知框架MR使用YARN -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
②配置etc/hadoop/yarn-site.xml:
- <configuration>
- <!-- reducer取数据的方式是mapreduce_shuffle -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
③YARN的启动与停止
- //启动
- ./sbin/start-yarn.sh
- 停止
- ./sbin/stop-yarn.sh
4、运行一个简单的MP程序
- ./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
- wordcount hdfs://localhost:9000/words.txt hdfs://localhost:9000/out
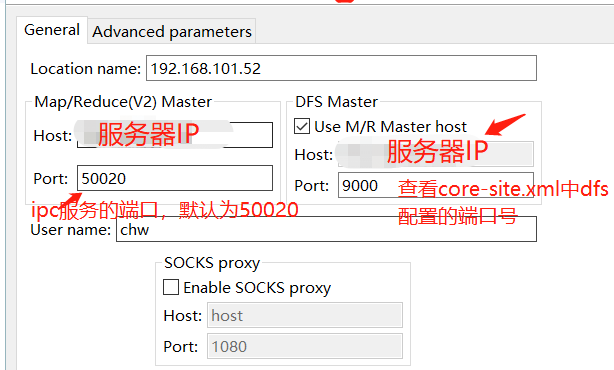 Username随意写
Username随意写添加
firewall-cmd --zone=public --add-port=80/tcp --permanent (--permanent永久生效,没有此参数重启后失效)
重新载入
firewall-cmd --reload
查看
firewall-cmd --zone=public --query-port=80/tcp
删除
firewall-cmd --zone=public --remove-port=80/tcp --permanent
最新文章
- android Activity介绍
- T-SQL 去除特定字段的前导0
- JAVA_DES 加密 解密 生成随机密钥
- device unauthorized & ANDROID_ADB_SERVER_PORT 问题解决
- 【linux】grub加密
- ArcGIS Desktop10.2与CityEngine2012兼容问题
- 终于明白公测的beta 源自何处了
- Linux 共享内存编程
- iOS学习之数据解析
- 关于Ajax的技术组成与核心原理
- C语言中的指针数组和数组指针
- ORACLE PL/SQL开发--bulk collect的用法 .
- 【JCP模式实战--ferrous-framework】ferrous前端开发框架邀您初体验
- Windows上Python2与Python3共存
- App会取代网站吗?
- 前端入门21-JavaScript的ES6新特性
- RecyclerView嵌套ScrollView导致RecyclerView内容显示不全
- centos7救援模式--单机模式(单用户模式)
- [杂谈] 一个关于 as 的小测试
- Beta阶段第二次网络会议