《TensorFlow2深度学习》学习笔记(三)Tensorflow进阶
本篇笔记包含张量的合并与分割,范数统计,张量填充,限幅等操作。
1.合并与分割
合并
张量的合并可以使用拼接(Concatenate)和堆叠(Stack)操作实现,拼接并不会产生新的维度,而堆叠会创建新维度。选择使用拼接还是堆叠操作来合并张量,取决于具体的场景是否需要创建新维度。
拼接 在 TensorFlow 中,可以通过 tf.concat(tensors, axis),其中 tensors 保存了所有需要合并的张量 List,axis 指定需要合并的维度。合并操作可以在任意的维度上进行,唯一的约束是非合并维度的长度必须一致。
a = tf.random.normal([4,35,8]) # 模拟成绩册 A
b = tf.random.normal([6,35,8]) # 模拟成绩册 B
tf.concat([a,b],axis=0) # 合并成绩册
Out[1]:
<tf.Tensor: id=13, shape=(10, 35, 8), dtype=float32, numpy=...>
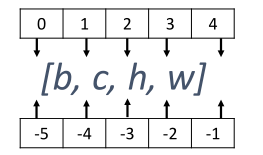
堆叠 如果在合并数据时,希望创建一个新的维度,则需要使用 tf.stack 操作。使用 tf.stack(tensors, axis)可以合并多个张量 tensors,其中 axis 指定插入新维度的位置,axis 的用法与 tf.expand_dims 的一致,当axis ≥ 0时在 axis 之前插入;当axis < 0时,在 axis 之后插入新维度。axis 参数对应的插入位置设置如图:
a = tf.random.normal([35,8])
b = tf.random.normal([35,8])
tf.stack([a,b],axis=0)
Out[4]:
<tf.Tensor: id=55, shape=(2, 35, 8), dtype=float32, numpy=...>
tf.stack 也需要满足张量堆叠合并条件,它需要所有合并的张量 shape 完全一致才可合并。
分割
通过 tf.split(x, axis, num_or_size_splits)可以完成张量的分割操作,其中x代表待分割张量;axis代表分割的维度索引号;num_or_size_splits代表切割方案。当 num_or_size_splits 为单个数值时,如 10,表示切割为 10 份;当 num_or_size_splits 为 List 时,每个元素表示每份的长度,如[2,4,2,2]表示切割为 4 份,每份的长度分别为 2,4,2,2
x = tf.random.normal([10,35,8])
# 等长切割
result = tf.split(x,axis=0,num_or_size_splits=10)
result[0]
Out[9]: <tf.Tensor: id=136, shape=(1, 35, 8), dtype=float32, numpy=...>
切割后的shape 为[1,35,8],保留了维度,这一点需要注意。
特别地,如果希望在某个维度上全部按长度为 1 的方式分割,还可以直接使用 tf.unstack(x,axis)。这种方式是 tf.split 的一种特殊情况,切割长度固定为 1,只需要指定切割维度即可。
x = tf.random.normal([10,35,8])
result = tf.unstack(x,axis=0) # Unstack 为长度为 1
result[0]
Out[12]: <tf.Tensor: id=166, shape=(35, 8), dtype=float32, numpy=...>
可以看到,通过 tf.unstack 切割后,shape 变为[35,8],即班级维度消失了,这也是与 tf.split区别之处。
2.数据统计
在神经网络的计算过程中,经常需要统计数据的各种属性,如最大值,均值,范数等等。由于张量通常 shape 较大,直接观察数据很难获得有用信息,通过观察这些张量统计信息可以较轻松地推测张量数值的分布。
向量范数
向量范数(Vector norm)是表征向量“长度”的一种度量方法,对于矩阵、张量,同样可以利用向量范数的计算公式,等价于将矩阵、张量打平成向量后计算。在神经网络中,常用来表示张量的权值大小,梯度大小等。常用的向量范数有:
- L1 范数,定义为向量
最新文章
- SQL中distinct的用法
- 使用django开发博客过程记录5——日期归档和视图重写
- VIM神器打造Javascript开发环境
- Divide and conquer:Sumsets(POJ 2549)
- 使用Symfony 2在三小时内开发一个寻人平台
- sql 指定范围 获取随机数
- IP地址 子网掩码 默认网关 DNS(转)
- Centos 6修复/boot目录及fstab等系统文件
- vue 解决IE不能用的问题
- Lecture4_1&4_2.多维随机变量及其概率分布
- bat 批处理获取时间语法格式
- 【英文文档】Solidifier for Windows Installation Guide
- springboot多环境(dev、test、prod)配置
- php抽奖概率算法
- 关于web优化(一)
- Unity反射探针用法教程
- sourcetree 跳过注册
- Qt——布局管理器
- BZOJ4543 Hotel加强版
- scala下实现actor多线程基础
热门文章