爬虫之scrapy框架应用selenium
2024-09-08 10:41:48
一、利用selenium 爬取 网易军事新闻
使用流程:
'''
在scrapy中使用selenium的编码流程:
1.在spider的构造方法中创建一个浏览器对象(作为当前spider的一个属性)
2.重写spider的一个方法closed(self,spider),在该方法中执行浏览器关闭的操作
3.在下载中间件的process_response方法中,通过spider参数获取浏览器对象
4.在中间件的process_response中定制基于浏览器自动化的操作代码(获取动态加载出来的页面源码数据)
5.实例化一个响应对象,且将page_source返回的页面源码封装到该对象中
6.返回该新的响应对象
'''
首先需要在中间件导入
from scrapy.html import HtmlResponse
DownloadMiddleware函数
def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest # 获取动态加载出来的数据
print("即将返回一个新的响应对象")
bw = spider.bw
bw.get(url = request.url)
import time
# 防止数据加载过慢
time.sleep(3)
# 包含了动态加载的数据
page_text = bw.page_source
time.sleep(3)
return HtmlResponse(url=spider.bw.current_url,body=page_text,
encoding="utf8",request=request)
spider.py
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver class ScrapySeleniumSpider(scrapy.Spider):
name = 'scrapy_selenium'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://war.163.com/']
def __init__(self):
self.bw = webdriver.Chrome(executable_path="F:\爬虫+数据\chromedriver.exe") def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title) def closed(self, spider):
print('关闭浏览器对象!')
self.bw.quit()
还需要注意的是使用中间件的同时需要在settings中解释一下Downloadmiddleware
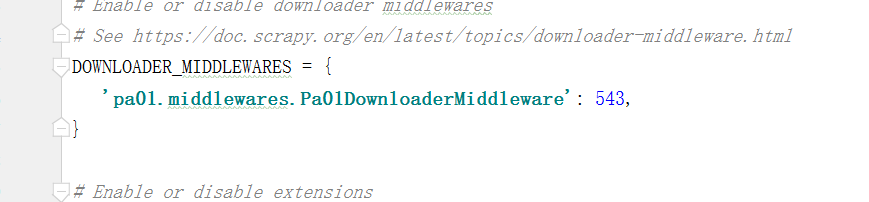
结果是这样就成功喽

最新文章
- [Nhibernate]一级缓存
- 20145227&20145201 《信息安全系统设计基础》实验四
- mysql主从复制的一些东西的整理
- MVP
- Hibernate的集合映射与sort、order-by属性
- bsgrid
- 字符串匹配KMP算法
- android-exploitme(六):基础加密
- MySQL 에서 root 암호 변경하기
- Java 数组在内存中的结构
- Goldbach's Conjecture(哥德巴赫猜想)
- jQuery中的attr()和prop()使用
- JQuery事件与动画总结
- 通过cmd窗口导入导出mysql数据库
- PTA中如何出Java题目?
- samba及其基本应用
- wampserver本地配置域名映射
- Oracle中PL/SQL的循环语句
- Bzoj3122:多项式BSGS
- Window 10 :如何彻底关闭:Windows Defender Service(2015-12-20日更新)