python3笔记二十三:正则表达式之元字符
一:学习内容
- 匹配单个字符与数字:.、[]、^、\d、\D、\w、\W、\s、\S
- 匹配锚字符(边界字符):^、$、\A、\Z、\b、\B
- 匹配多个字符:(xyz) 、x?、x*、.*、x+、x{n}、x{n,}、x{n,m}、x|y
- 非贪婪匹配:*?、+?、??、{n,m}?
二:匹配单个字符与数字
1.点.:匹配除换行符以外的任意字符
2.[]:是字符集合,表示匹配方括号中所包含的任意一个字符
[0123456789] 表示匹配任意一个数字
[0-9] 表示匹配任意一个数字
[yml] 表示匹配'y','m','l'中任意一个字符
[a-z] 表示匹配任意一个小写字符
[A-Z] 表示匹配任意一个大写字符
[0-9a-zA-Z] 表示匹配任意一个数字和字母
[0-9a-zA-Z_] 表示匹配任意一个数字、字母和下划线
3.^:是脱字符,表示不匹配集合中的字符,注意^在[]中才表示不匹配,在其他位置意义不一样
[^test] 表示匹配除了test这几个字母以外的所有字符
[^0-9] 表示匹配所有的非数字字符
4.\d:匹配数字,效果同[0-9]
\d 表示匹配任意一个数字,这里可以不写[],直接使用\d
[^\d] 表示匹配所有的非数字字符,效果同[^0-9]
5.\D:匹配非数字字符,效果同[^0-9]
6.\w:匹配数字、字母和下划线,效果同[0-9a-zA-Z]
7.\W:匹配非数字、字母和下划线,效果同[^0-9a-zA-Z]
8.\s:匹配任意的空白符(空格、换行、回车、换页、制表符),效果同[ \f\n\r\t]
9.\S:匹配任意的非空白符(空格、换行、回车、换页、制表符),效果同[^ \f\n\r\t]
10.举例:
print(re.search(".","tester is a good girl!")) #.可以代表任意字符,所以匹配t,结果匹配一个t
print(re.search("[0123456789]","yml is a good gril 7")) #匹配结果为数字7
print(re.search("[tester]","tester is a good gril 7")) #匹配结果为一个t
print(re.search("[^tester]","tester is a good gril 7")) #匹配除tester之外的任意一个字符结果为空" "
print(re.search("[^0-9]","tester is a good gril 7")) #匹配一个非数字字符结果为t
print(re.search("\d","tester is a good gril 7")) #匹配结果为数字7
print(re.search("[^\d]","tester is a good gril 7")) #匹配结果为一个t
print(re.search("\D","tester is a good gril 7")) #匹配一个非数字字符结果为t
print(re.search("\w","tester is a good gril 7")) #匹配任意一个数字字母或下划线,结果为t
print(re.findall(".","_tester is test\nd girl 3")) #匹配除换行符以外的任意字符
print(re.findall(".","_tester is test\nd girl 3",flags=re.S)) #匹配包括换行符在内的任意字符
三:匹配锚字符(边界字符)
1.^:行首匹配,注意^在[]中才表示不匹配集合中的字符
2.$:行尾匹配
3.\A:匹配字符串开始,它和^区别是:
\A只匹配整个字符串的开头即使在re.M模式下,也不会匹配其他行的行首
^匹配的是每行的行首
4.\Z:匹配字符串结束,它和$区别是:
\Z只匹配整个字符串的结束即使在re.M模式下,也不会匹配其他行的行尾
$匹配的是每行的行尾
5.\b:匹配一个单词的边界,也就是指单词和空格间的位置
6.\B:匹配非单词的边界,也就是指单词和空格间的位置
7.举例:
print(re.search("^test","test is a good girl")) #表示行首必须要是test开头
print(re.search("girl$","test is a good girl")) #表示行尾必须要是girl结尾
print(re.search("\Atest","test is a good girl"))
print(re.findall("^test","test is a good girl\ntest is a good girl",flags=re.M))
print(re.findall("\Atest","test is a good girl\ntest is a good girl",flags=re.M))
print(re.findall("girl$","test is a good girl\ntest is a good girl",flags=re.M))
print(re.findall("girl\Z","test is a good girl\ntest is a good girl",flags=re.M))
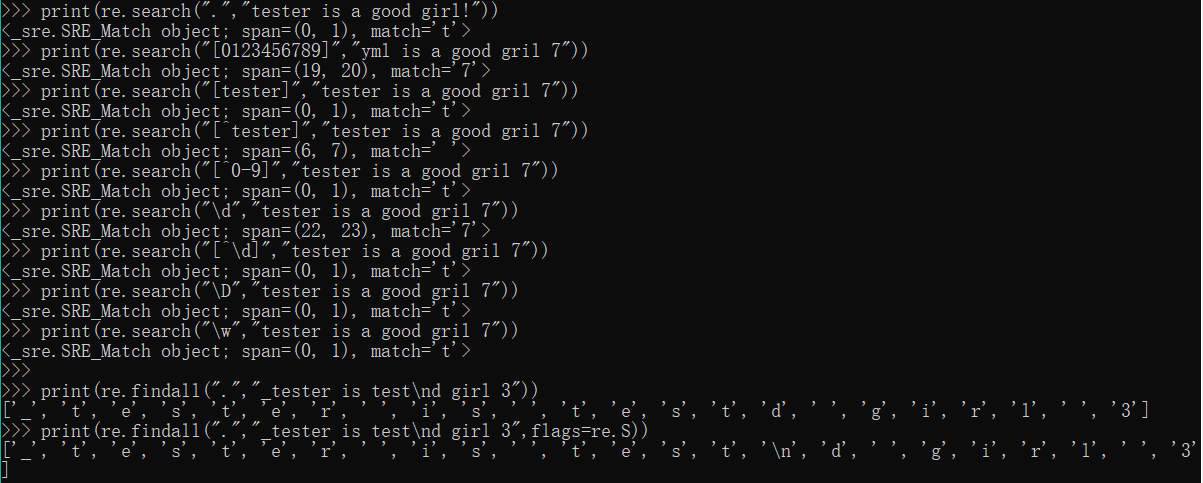
print(re.findall(r"er\b","never"))
print(re.findall(r"er\B","never"))
print(re.findall(r"er\b","nerve"))
print(re.findall(r"er\B","nerve"))
四:匹配多个字符
说明:下方的x、y、z均为假设的普通字符,n、m为非负整数,不是正则表达式的元字符
1.(xyz):匹配小括号内的内容,()内的内容xyz作为一个整体去匹配
2.x?:匹配0个或者1个x,非贪婪匹配(尽可能少的匹配)
3.x*:匹配0个或者任意多个x,贪婪匹配(尽可能多的匹配)
.*:表示匹配0个或任意多个字符(换行符除外)
4.x+:匹配至少一个x,贪婪匹配(尽可能多的匹配)
5.x{n}:匹配确定的n个x,n是一个非负整数
6.x{n,}:匹配至少n个x,n是一个非负整数
7.x{n,m}:匹配至少n个最多m个x,注意:n <= m
8.x|y:|表示或,匹配的是x或y
9.举例:
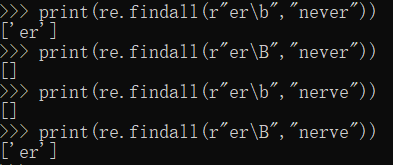
print(re.findall(r"(test)","test"))
print(re.findall(r"y?","ytesttest")) #匹配0个或1个
print(re.findall(r"y*","ytesttest")) #匹配0个或任意多个,贪婪匹配
print(re.findall(r"y+","ytesttest")) #匹配至少1个,贪婪匹配
print(re.findall(r"y{3}","ytestyyytest")) #匹配3个y
print(re.findall(r"y{3,}","yytestyyytest")) #匹配至少3个y
print(re.findall(r"y{3,6}","yytestyyytest")) #匹配至少3个y,最多6个y

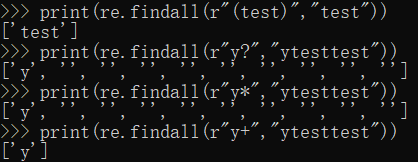
print(re.findall(r"(t|T)est","tttestttttest")) #匹配t或T
print(re.findall(r"t|Test","tttestttttest"))
print(re.findall(r"((t|T)est)","tttestttttest"))
#需求:提取tester......girl
str = "tester is a good girl!tester is a nice girl!tester is a very dddd girl"
print(re.findall(r"tester.*girl",str))
print(re.findall(r"tester.*?girl",str)) #非贪婪

五:非贪婪匹配
1. *?:前一个字符0次或无限次扩展,最小匹配
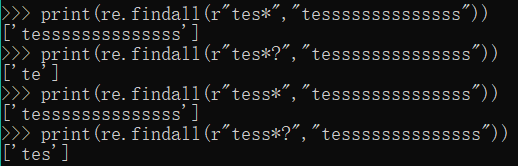
print(re.findall(r"tes*","tessssssssssssss"))
print(re.findall(r"tes*?","tessssssssssssss"))
print(re.findall(r"tess*","tessssssssssssss"))
print(re.findall(r"tess*?","tessssssssssssss"))
2. +?:前一个字符1次或无限次扩展,最小匹配
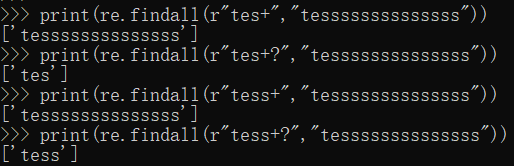
print(re.findall(r"tes+","tessssssssssssss"))
print(re.findall(r"tes+?","tessssssssssssss"))
print(re.findall(r"tess+","tessssssssssssss"))
print(re.findall(r"tess+?","tessssssssssssss"))
3. ??:前一个字符0次或1次扩展,最小匹配
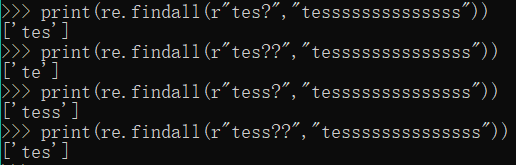
print(re.findall(r"tes?","tessssssssssssss"))
print(re.findall(r"tes??","tessssssssssssss"))
print(re.findall(r"tess?","tessssssssssssss"))
print(re.findall(r"tess??","tessssssssssssss"))
4. {n,m}?:扩展前一个字符n到m次,含m,最小匹配
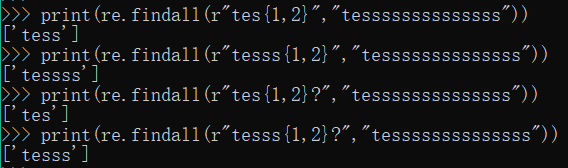
print(re.findall(r"tes{1,2}","tessssssssssssss"))
print(re.findall(r"tesss{1,2}","tessssssssssssss"))
print(re.findall(r"tes{1,2}?","tessssssssssssss"))
print(re.findall(r"tesss{1,2}?","tessssssssssssss"))
最新文章
- 在Linux配置Nginx web服务器步骤
- css3样式二
- SVN服务器与测试服务器代码同步
- phpmyadmin上传大sql文件办法
- SQLServer 关闭自增长,插入数据
- Fluent NHibernate example
- RF-BM-S02(V1.0)蓝牙4.0模块 使用手册
- HDU 2602 (简单的01背包) Bone Collector
- Operation与GCD的不同
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
- CSS凹型导航按钮
- Azure机器学习入门(三)创建Azure机器学习实验
- 纯Socket(BIO)长链接编程的常见的坑和填坑套路
- Feign源码解析系列-核心初始化
- CP IPS功能测试
- web进修之—Hibernate 懒加载(6)
- OpenStack的基本概念与架构图
- Scala的映射和元组操作
- JS中,如何判断一个数是不是小数?如果是小数,如何判断它是几位小数??
- css 常用类名