kafka为什么吞吐量高,怎样保证高可用
2024-09-08 15:37:02
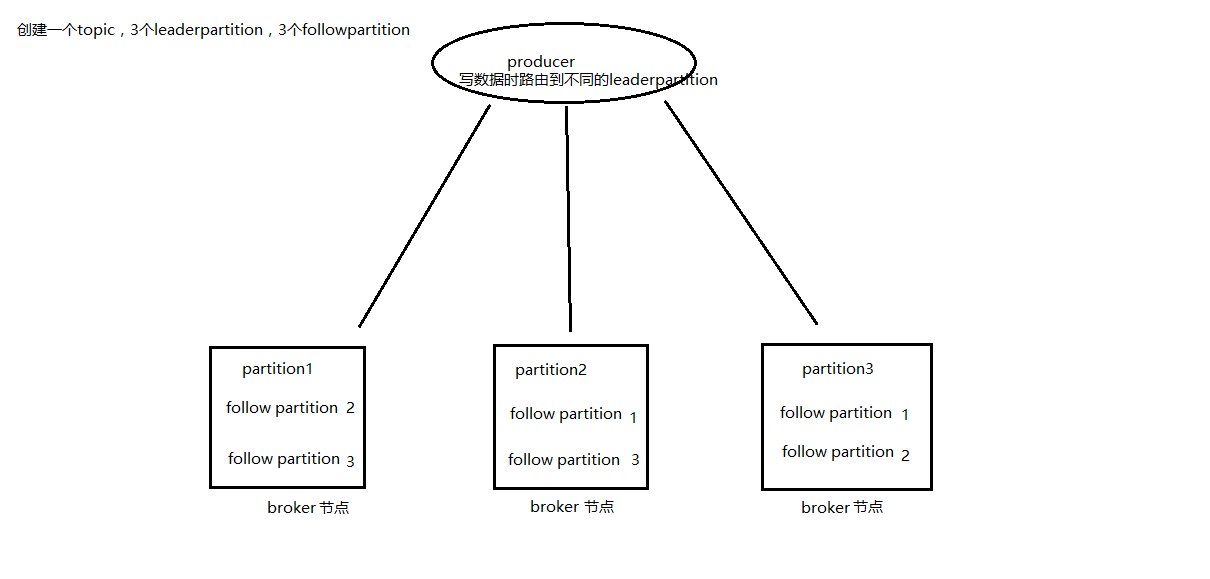
1:kafka可以通过多个broker形成集群,来存储大量数据;而且便于横向扩展。
2:kafka信息存储核心的broker,通过partition的segment只关心信息的存储,而生产者只负责向leader角色的partition提交数据,而消费者pull数据的时候自己通过zk存储offset信息,严格讲broker基本只关心存储数据;
3:kafka的ack策略也是提高吞吐量的手段:
1)生产者的acks如果设置0则只向leader发送数据,并不关心leader数据是否存储成功;
2)如果设置为1在向leader发送数据后需要等待leader存储成功后才会认为一次操作成功;
3)如果设置为-1在向leader发送数据后不但需要等待leader存储成功,还要等待各个follow角色的partition,从leader拉取数据后存储完成才算一次完整的ack,当然这种情况会降低kafka的吞吐量;
而且follow从leader拉去后存储完成才能将本地的(segmentLog)LEO标记移动到最后,如果follow未同步完成kafka为了保证数据一致性“HW高水位线”也只能保证到一个较低水平;
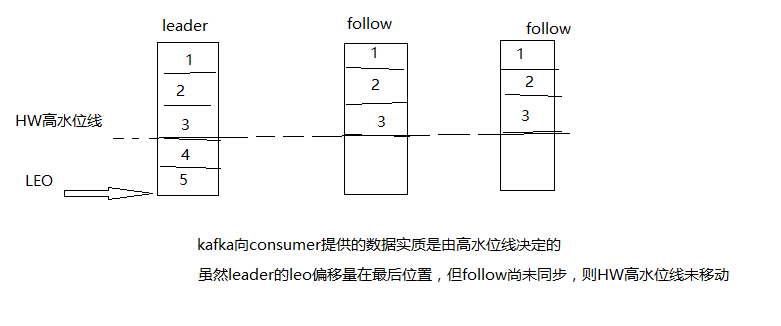
高可用:
ps:而且kafka底层是通过NIO顺序写数据,效率也是非常高的
最新文章
- Windows server 修改mysql端口
- Object-C中ARC forbids explicit message send of ' ' 错误
- MicroService/web Service/webAPI/RPC
- JPA与Hibernate的关系
- .NET跨平台之OWEN中 过滤器的使用
- win8以上系统,设置英文为默认输入法
- Threading in C#
- [转载]python中将普通对象作为 字典类(dict) 使用
- centos msyql 安装与配置
- Java跳出循环-break和continue语句
- Django数据库配置
- 一步一步实现FormsAuthentic验证登录
- Python 智能处理方向的工具
- CSS.04 -- 浮动float、overflow、定位position、CSS初始化
- SpringMVC 支持使用Servlet原生API作为目标方法的参数
- Oracle Database 10g安装
- Mergeable Stack(链表实现栈)
- 【BZOJ】3144: [Hnoi2013]切糕
- 背水一战 Windows 10 (49) - 控件(集合类): Pivot, Hub
- SQL Server 2016将内置R语言