全面优化MySQL
MySQL性能瓶颈原因
硬件、系统因素
CPU
磁盘I/O
网络性能
操作系统争用
MySQL相关因素
数据库设计
索引、数据类型
应用程序性能
特定请求、短时事务
配置变量
缓冲区、高速缓存、InnoDB
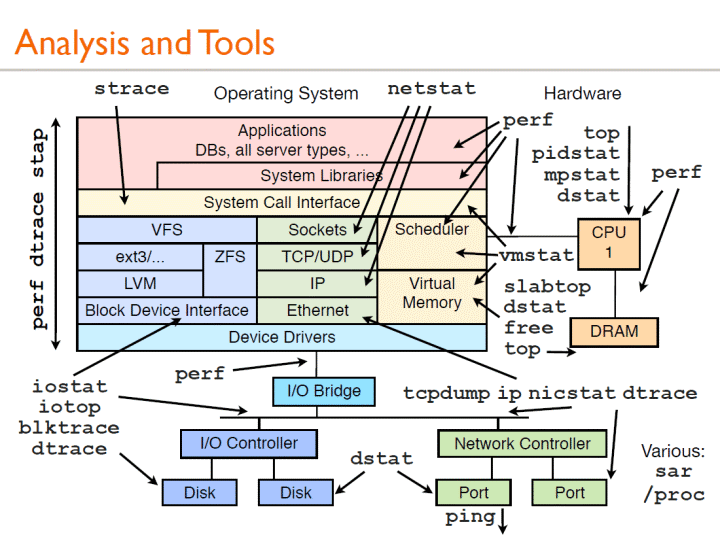
瓶颈分析工具
sysstat工具集
sar、iostat、pidstat、mpstat
perf top
实时显示系统/进程的性能统计信息
pt-ioprofile
MySQL中的iotop
pstack
当MySQL里有线程hang住时,利用pstack排查由于哪些函数调用存在问题
硬件优化
BIOS配置优化
CPU设置最大性能模式,关闭C1E,C-stats
内存设置最大性能模式
关闭NUMA(并关注innodb_numa_interleave选项)
RAID配置优化
RAID-10
CACHE & BBU
WB & FORCE WB (WB是好的,WT是不好的)
使用PCIe-SSD等高速I/O设备
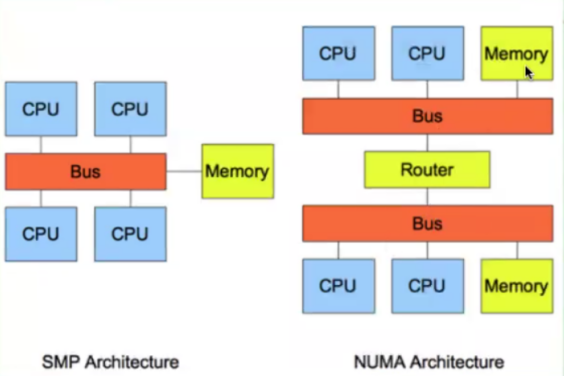
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
node 0 size: 65415 MB
node 0 free: 4086 MB
node distances:
node 0
0: 10
available大于1说明numa没关闭
系统优化
io scheduler
deadline(机械盘)/noop(SSD盘)
filesystems
xfs(强烈建议)
ext4(备选)
kernel
vm.swappiness=1~5 (rhel7以后,设置0要慎重)
vm.dirty_background_radio=5
vm.dirty_radio=10
MySQL配置优化
innodb_buffer_pool_size
innodb_log_file_size >= 1G & innodb_log_files_in_group >= 3
innodb_flush_log_at_trx_commit & sync_binlog = ?
innodb_max_dirty_pages_pct
innodb_thread_concurrency = 0
innodb_io_capacity & innodb_io_capacity_max
innodb_max_purge_lag = 0
innodb_autoinc_lock_mode = 2 & binlog_format = row
max_binlog_cache_size
sort/join/read/read rrd buffer、tmp/heap table (session级别的内存不要设置太高)
thread_handling = one-thread-per-connection | pool-of-thread
long_query_time = 0.05
log_error_verbosity = 3
time_zone = "+8:00" (默认值SYSTEM,设置为具体时区即可)
open_files_limit = 65535
back_log = (max_connections * 2)
max_execution_time = 10000 (/*+ MAX_EXECUTION_TIME(10000)*/)
SCHEMA设计优化
核心宗旨
表越窄越好 - 数据类型够用就好,保持高效
表越小越好 - 数据冷热分离,只留最新热数据
查询够高效 - 令每个SQL效率足够高,不阻塞
InnoDB使用
INT AUTO_INC PK for InnoDB
INT unsigned for IPV4, not CHAR(15)
TINYINT for ENUM type
TEXT、BLOB,or in compressed,并且尽量拆分到子表
JOIN列类型(包括长度、字符集)保持一致
多表JOIN时,排序列一定要属于驱动表,否则有额外filesort
select ... from a straight_join b where ... order by b.x; 需要额外的filesort
所有列设置NOT NULL
主键/唯一索引性能优于普通索引
联合索引比普通索引更合适
基数(cardinality)小的列不建独立索引,因为不支持bitmap索引
长字段使用部分索引,而非全部
可以利用冗余反向字段用于反向检索
sphinx等代替like '%xx%'搜索
SQL优化
多用简单SQL
少用子查询(不熟悉子查询时)
少用复杂表JOIN,并且注意JOIN方式
WHERE条件中不使用函数、表达式(虚拟列变通)
注意类型隐式转换
固定业务逻辑封装成存储过程(存储过程可能会影响未来分库分表、读写分离架构)
限制结果集大小
分页改成基于主键的JOIN或子查询
动态改造成静态,或者降低更新频率
从产品端消减不必要的业务
逻辑优化
以下场景,都可以在redis或cache中暂存,最后再定时持久化存储到DB
游戏人员移动,或是一些技能背包字段的设计,更新可以做合并更新等
过节时人们的发短信或是祝福行为
文章被访问每次加1
用户登录每次加1
MySQL性能瓶颈定位
优化耗时/逻辑读 top sql
找到耗时最慢的 top sql (PFS.events_statements_history_long)
排序TIMER_WAIT/ROWS_EXAMINED/ROWS_SENT
定位这些SQL的性能瓶颈(PFS.events_stages_history_long/profiling)
优化物理逻辑 i/o top sql
找到逻辑 i/o 请求最多的对象 (PFS.table_io_waits_summary_by_table)
找到物理 i/o 请求最多的对象 (sys.io_global_by_file_by_bytes)
定位、优化这些请求
不建议打开pfs
几个案例
insert慢的几种场景
innodb_thread_concurrency > 0
innodb_max_purge_lag > 0
innodb_io_capacity太小
redo & binlog 2PC
锁等待
semi-sync延迟
disk full
中间件性能太差,导致mysqld server端大量请求被阻塞
SQL瓶颈分析之PROFILE
mysql> set profiling=1;
mysql> select * from customer order by address_id;
mysql> show profiles;

mysql> show profile for query 1;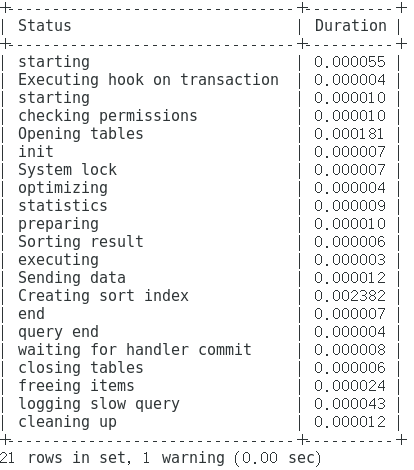
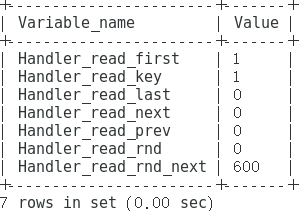
SQL效率对比分析之SHOW STATUS
mysql> flush status;
mysql> select * from customer order by address_id;
mysql> show status like 'handler_read_%';
内存临时表
基于内存的临时表(in-memory internal temporary tables),引擎由默认的memory改成了新的TempTable引擎
默认内存相对于tmp-table-size,从16M提升到1G
对varchar、varbinary的处理效率更高
internal_tmp_mem_storage_engine = TempTable | MEMORY
设置变量temptable_max_ram 来控制实际存储内存区域大小,默认为1G
slow query log
解析:
mysqldumpslow
pt-query-digest(推荐)
也可以启用general log + pt-query-digest
可视化管理:Box Anemometer/Query-Digest-UI
相关选项:
long-query-time = 0.01
log_queries_not_using_indexes = 1
log_throttle_queries_not_using_indexes = 60
min_examined_row_limit = 100
log_slow_admin_statements = 1
log_slow_slave_statements = 1
5.7 & 8.0 版本下,可以利用sys schema.statement_analysis视图
执行次数最多的TOP 10 SQL
select ... order by exec_count desc limit 10
平均响应耗时最慢的TOP 10 SQL
select ... order by avg_latency desc limit 10
每次扫描行数最多的TOP 10 SQL
select ... order by rows_examined desc limit 10
优先级高:执行次数多,高峰期慢SQL,核心业务慢SQL
优先级低:执行时间长,低谷期慢SQL,周边业务慢SQL
最新文章
- javascript学习目录
- 深度学习入门教程UFLDL学习实验笔记二:使用向量化对MNIST数据集做稀疏自编码
- Tornado 中的 get() 或 post() 方法
- [Quick-x lua]CCLabel类数字变化动作
- photoshop 魔术橡皮擦
- IOS开发创建开发证书及发布App应用(六)——打包应用
- 轻量级操作系统FreeRTOS的内存管理机制(一)
- MYSQL———正则表达式查询!
- Spring 中 SQL 的存储过程
- json_encode里面经常用到的 JSON_UNESCAPED_UNICODE和JSON_UNESCAPED_SLASHES
- Oracle minus用法详解及应用实例
- java指针与引用(转载)
- mysql 删除表
- 多线程--Thread.join方法
- Mac改变系统截图存储路径
- python学习笔记十七:base64及md5编码
- hdu2010(dfs+剪枝)
- 继续学习:C语言关键字
- Java探索之旅(10)——数组线性表ArrayList和字符串生成器StringBuffer/StringBuilder
- MongoDB 基本操作具体解释
热门文章
- java本地与树莓派中采用UDP传输文本、图片
- 常见的医学基因筛查检测 | genetic testing | 相癌症早筛 | 液体活检
- variant变异 | Epigenome表观基因组 | Disease-susceptible gene 疾病易感基因
- Flutter -------- 网络请求之HttpClient
- composer Changed current directory to没反应
- error C1002: 在第 2 遍中编译器的堆空间不足
- Python 初级 5 判断再判断(三)
- if判断用法
- 【430】BST and Splay Tree
- PAT 甲级 1068 Find More Coins (30 分) (dp,01背包问题记录最佳选择方案)***