简单scrapy爬虫实例
2024-09-03 20:58:41
简单scrapy爬虫实例
流程分析
抓取内容:网站课程
页面:https://edu.hellobi.com
数据:课程名、课程链接及学习人数
观察页面url变化规律以及页面源代码帮助我们获取所有数据
1、scrapy爬虫的创建
在pycharm的Terminal中输入以下命令:
创建scrapy项目:scrapy startproject ts
进入到项目目录中:cd first
创建一个新的spider:scrapy genspider -t basic lesson hellobi.com
2、scrapy爬虫代码编写
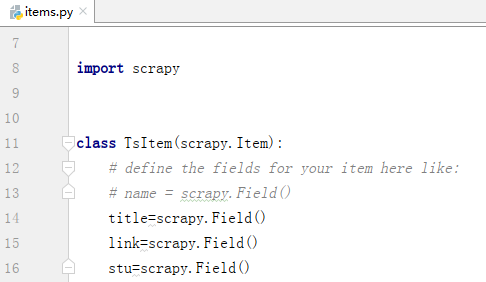
2.1items文件编写
在items.py文件中定义自己要抓取的数据,我们要爬取天善智能网站的课程、课程链接和学习人数,需要这三者的数据,所以此时创建item的三个类。
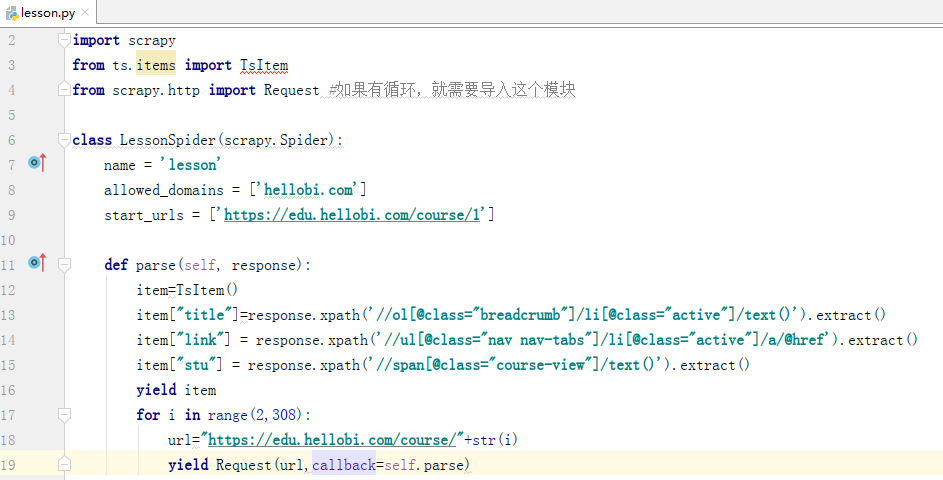
2.2编写spider文件(lesson.py)
由于要提取该网站所有课程的消息,需要构造了所有的课程url。此时观察观察多个url,找出其中url变化的规律,以此来构造所有的url。由于每个课程都需要包含课程名、课程链接以及学习人数,所有设置相应的xpath,分别匹配item的三个类。
2.3修改pipeline.py的内容:
将爬取到的数据写入“F:/天善课程爬取/1.txt”中。

2.4修改settings.py文件,配置pipeline:

3、总结
至此,爬虫就全部编写完成了,在scrapy中xpath很重要,如果xpath提取错误的话,可能会造成许多错误。另外在输出和写入文件时也要注意,不然也会有错误发生。在程序的最后一定要关闭文件,不然最后打开文件的内容为空。
最新文章
- View的滑动
- 不同数据库中同一张表的SQL循环修改语句
- 北京动软VAR团队的HoloLens开发教程最新搜罗整理
- Consul 服务发现和配置
- 神经网络dropout
- HDU 5047 Sawtooth(大数模拟)上海赛区网赛1006
- RAID选项
- Ubuntu 14.10 下设置时间同步
- css文字截取
- cmstop中实例化controller_admin_content类传递$this,其构造方法中接收到的是--名为cmstop的参数--包含cmstop中所有属性
- Hadoop权威指南:MapReduce应用开发
- vue 高德地图之玩转周边
- Cannot load browser "PhantomJS": it is not registered! Perhaps you are missing some plugin? 测试安装遇到的BUG
- 记一次生产环境Nginx日志骤增的问题排查过程
- python_如何为元组中每个元素命名
- vue实现表计监测界面
- 给对话框添加动画 Dialog
- 770. Basic Calculator IV
- 又一个opengl教程,多多益善
- ML_入门