scrapy 当当网 爬虫
前言
好久没有写实战博客了,因为前几个月在公司实习,博客更新就耽搁了下来,现在又受疫情影响无法返校,但是技能还是不能丢的,今天就写一篇使用scrapy爬取当当网的实战练习吧。
创建scrapy项目
目标站点: http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1 这是在当当网搜索关键字python得到的页面
第一步仍然是使用命令行切换到工作目录创建scrapy项目
- D:\pythonwork\cnblog>scrapy startproject cnblog_dangdang

然后使用cd命令进入项目中的spiders文件夹使用命令创建爬虫文件(注意:该命令后的网址跟的是目标网址域名,而不是整个网址)
- D:\pythonwork\cnblog\cnblog_dangdang\cnblog_dangdang\spiders>scrapy genspider dangdang_spider dangdang.com

此时我们的项目与基础爬虫文件已经创建完毕,接下来编写代码使用pycharm打开项目
内容分析
打开目标站点分析我们需要爬取什么内容
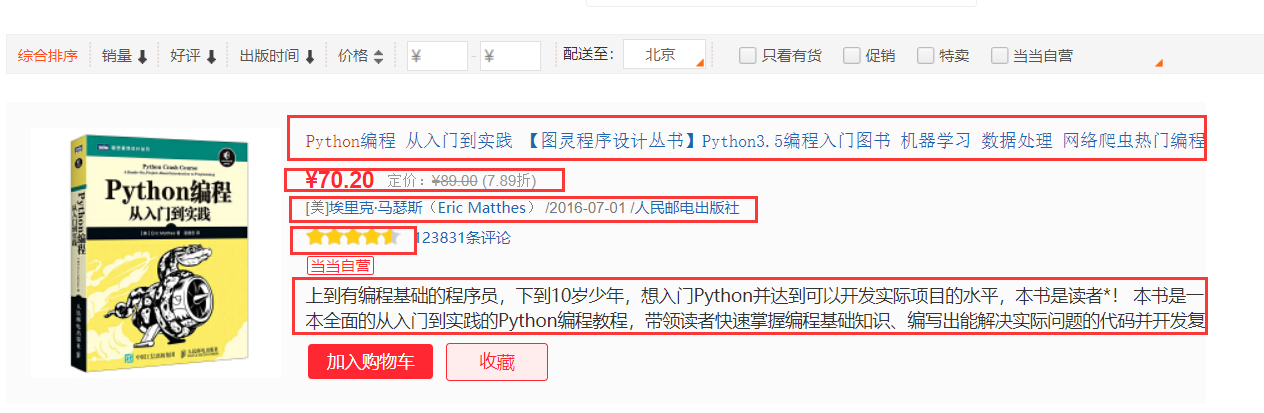
对于目标站点的商品图书而言,我们需要爬取它的标题、价格、作者、评分和概括五个部分
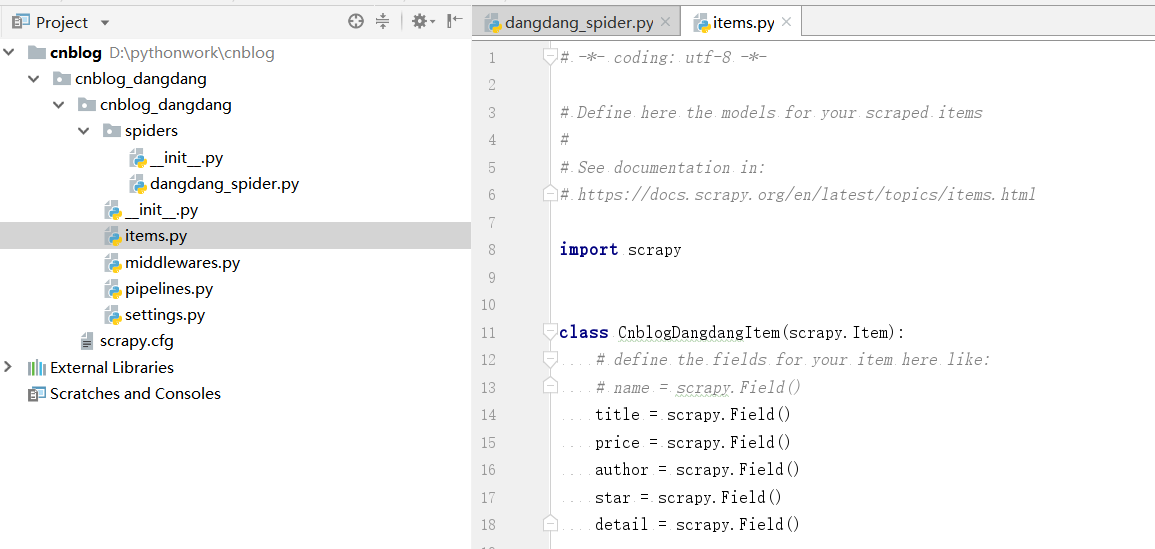
因此首先我们在项目的items.py文件中声明我们需要爬取的内容。
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class CnblogDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
author = scrapy.Field()
star = scrapy.Field()
detail = scrapy.Field()
因此我们的数据表的sql语句创建如下:
CREATE TABLE IF NOT EXISTS dangdang_item (
id INT UNSIGNED AUTO_INCREMENT,
title CHAR(100) NOT NULL,
price CHAR(100) NOT NULL,
author CHAR(100) NOT NULL,
star CHAR(10) NOT NULL,
detail VARCHAR(1000),
PRIMARY KEY (id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
爬虫文件编写
内容分析完成之后我们到了最关键的爬虫文件编写部分,首先我们要测试下该网站有没有反爬措施。
这一步我们只需要简单的将spiders文件夹中的dangdang_spider.py文件进行简单的修改让其输出目标站点的响应内容即可
dangdang_spider.py
# -*- coding: utf-8 -*-
import scrapy class DangdangSpiderSpider(scrapy.Spider):
name = 'dangdang_spider'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response):
print(response.text)
pass
为了方便我们进行调试,我们在项目下创建一个main.py文件用于启动爬虫,不然我们每次启动都需要在命令行中使用scrapy命令。
main.py
from scrapy import cmdline
cmdline.execute('scrapy crawl dangdang_spider'.split())
然后直接运行main.py文件,发现输出了目标网站的html源代码,所以目标网站并没有反爬措施,我们可以直接拿取内容,接下来就开始拿取内容了。
五部分内容使用xpath拿取,网页结构很简单,直接从源码分析xpath即可。
开始实际编写爬虫文件dangdang_spider.py
# -*- coding: utf-8 -*-
import scrapy
import re
from cnblog_dangdang.items import CnblogDangdangItem str_re = re.compile('\d+') class DangdangSpiderSpider(scrapy.Spider):
name = 'dangdang_spider'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response):
book_item = CnblogDangdangItem()
items = response.xpath("//ul[@class='bigimg']/li")#不用加get 因为此步骤为了拿到一个xpath对象
for item in items:
book_item['title'] = item.xpath("./a/@title").get()
book_item['price'] = item.xpath("./p[@class='price']").xpath("string(.)").get()#使用string(.)方法为了拿取目标节点下的所有子节点文本
book_item['author'] = item.xpath("./p[@class='search_book_author']").xpath("string(.)").get()
book_item['star'] = int(str_re.findall(item.xpath("./p[@class='search_star_line']/span/span/@style").get())[0])/20
book_item['detail'] = item.xpath("./p[@class='detail']//text()").get()
print(book_item)
yield book_item next_url_end = response.xpath("//li[@class='next']/a/@href").get()
#如果拿到了下一页链接,则访问
if next_url_end:
next_url ='http://search.dangdang.com/'+ next_url_end
yield scrapy.Request(next_url,callback=self.parse)
再次运行爬虫,发现现在已经可以输出拿取到的信息

说明我们的爬虫文件编写成功,接下来就是对我们拿取到的数据进行处理。
数据的存储
此次我们选择使用mysql进行数据的存储,那么我们首先要干什么呢?是直接编写pipeline.py文件吗?并不是,我们还有一个很重要的地方没有弄,就是settings.py文件。
我们想要通过pipeline.py文件来处理爬取到的数据,首先就需要去settings.py中开启我们的pipeline选项,很简单只需要在settings.py中将ITEM_PIPELINES的注释消掉即可如下图

接下来就可以编写pipeline.py文件来对我们的数据进行操作了
pipeline.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import pymysql number = 0
class DangdangPipeline(object): # open_spider()爬虫开启时执行一次
def open_spider(self,spider):
# 连接数据库
print("连接数据库,准备写入数据")
self.db = pymysql.connect('localhost', '你的mysql账户', '你的mysql密码', '你的数据库名称')
self.cursor = self.db.cursor() def process_item(self, item, spider):
global number
number = number+1
print('当前写入第'+str(number)+'个商品数据')
#使用replace是为了避免数据中存在引号与sql语句冲突
title=str(item['title']).replace("'","\\'").replace('"','\\"')
price=str(item['price']).replace("'","\\'").replace('"','\\"')
author=str(item['author']).replace("'","\\'").replace('"','\\"')
star=str(item['star']).replace("'","\\'").replace('"','\\"')
detail=str(item['detail']).replace("'","\\'").replace('"','\\"')
sql = f'INSERT INTO dangdang_item (title,price,author,star,detail) VALUES (\'{title}\',\'{price}\',\'{author}\',\'{star}\',\'{detail}\');'
#执行sql语句
self.cursor.execute(sql)
#数据库提交修改
self.db.commit()
return item # close_spider()爬虫关闭后执行
def close_spider(self,spider):
print('写入完成,一共'+str(number)+'个数据')
# 关闭连接
self.cursor.close()
self.db.close()
接下来再次运行main.py文件,看看爬虫效果。

我们去数据库中看一下我们刚刚爬取的数据
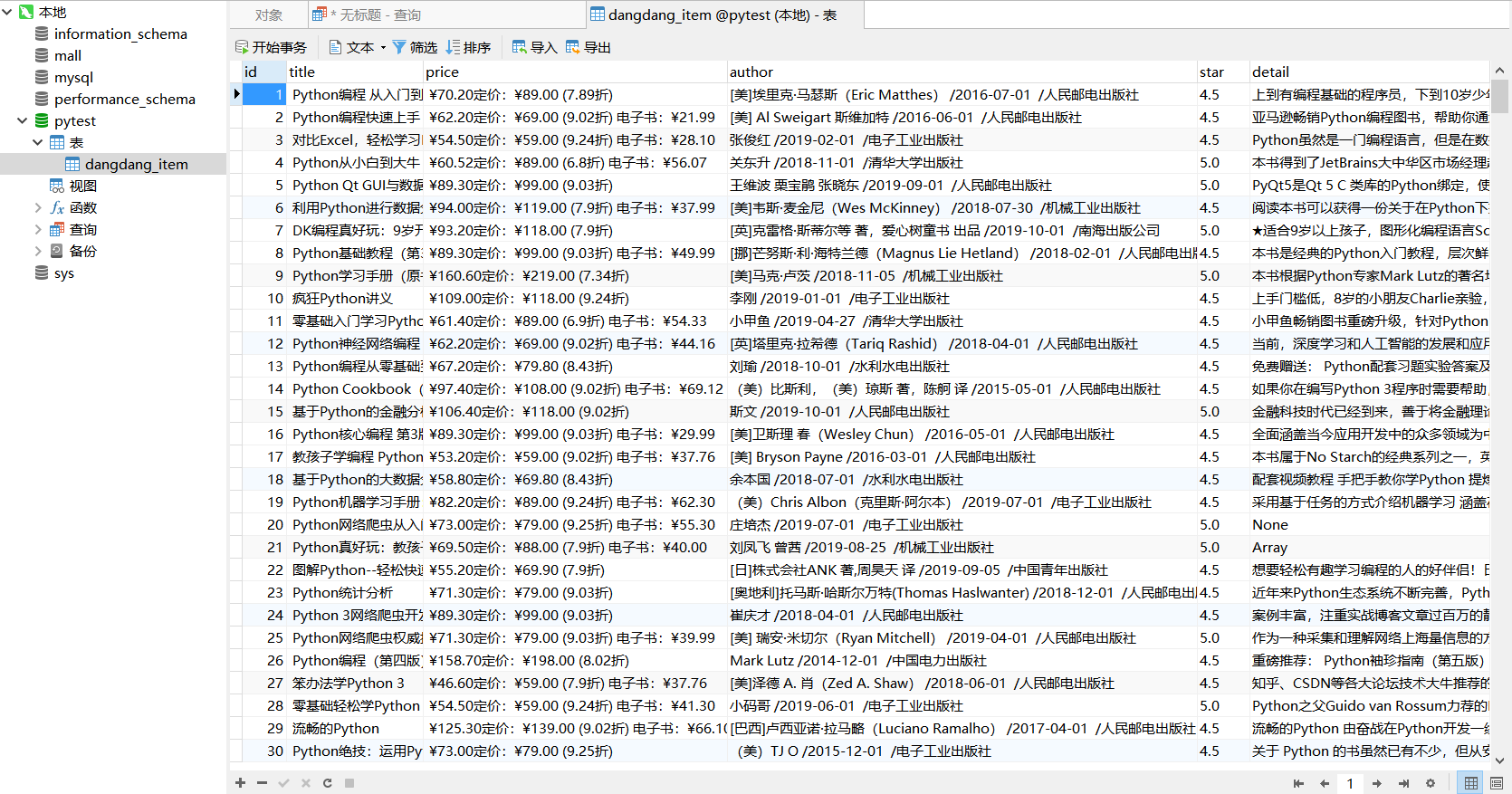
ok,大功完成了,我们的当当网scrapy爬虫就编写好了。
最新文章
- javascript for循环
- Action接收页面传来的参数方法
- 洛谷P1458 顺序的分数 Ordered Fractions
- UVA 10557 XYZZY
- UML--建模
- has leaked ServiceConnection com.baidu.location.LocationClient
- 《深入理解mybatis原理》 Mybatis初始化机制具体解释
- SQL点滴28—一个简单的存储过程
- Shiro 的FilterChain
- POJ 1067 取石子游戏 威佐夫博弈
- HBase伪分布安装
- 标准IO和重定向
- Excel阅读模式/单元格行列指示/聚光灯开发 技术要点再分享
- 认识多线程中start和run方法的区别?
- php 截取 小程序上传到服务器图片,
- FluentData -Micro ORM with a fluent API that makes it simple to query a database 【MYSQL】
- BZOJ 4405 [wc2016]挑战NPC 带花树 一般图最大匹配
- mybatis*中DefaultVFS的logger乱码问题
- bzoj4480: [Jsoi2013]快乐的jyy
- BBS-项目流程分析-表的创建
热门文章
- 创建自定义的RouteBase实现(Creating a Custom RouteBase Implementation) |定制路由系统 |
- 用Python实现根据角4点进行矩阵二维插值并画出伪彩色图
- C语言—期末小黄衫获奖感言
- CSS-02-css的三种基础选择器
- Docker基础内容之数据持久化
- 命令行下使用RAR和7-Zip压缩数据
- pymysql连接提示format: a number is required, not str
- Docker应用部署实录(包含完善Docker安装步骤)
- WeChall_Encodings: URL (Training, Encoding)
- ARTS Week 3