【Sqoop学习之二】Sqoop使用
2024-09-21 03:51:26
环境
sqoop-1.4.6
一、基本命令
1、帮助命令
[root@node101 ~]# sqoop help
Warning: /usr/local/sqoop-1.4./../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop-1.4./../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4./../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4./../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
usage: sqoop COMMAND [ARGS] Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information See 'sqoop help COMMAND' for information on a specific command.
查看某个命令的帮助,比如导入
[root@node101 ~]# sqoop help import
Warning: /usr/local/sqoop-1.4./../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop-1.4./../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4./../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4./../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
usage: sqoop import [GENERIC-ARGS] [TOOL-ARGS] Common arguments:
--connect <jdbc-uri> Specify JDBC connect
string
--connection-manager <class-name> Specify connection manager
class name
--connection-param-file <properties-file> Specify connection
parameters file
--driver <class-name> Manually specify JDBC
driver class to use
--hadoop-home <hdir> Override
$HADOOP_MAPRED_HOME_ARG
--hadoop-mapred-home <dir> Override
$HADOOP_MAPRED_HOME_ARG
--help Print usage instructions
-P Read password from console
--password <password> Set authentication
password
--password-alias <password-alias> Credential provider
password alias
--password-file <password-file> Set authentication
password file path
--relaxed-isolation Use read-uncommitted
isolation for imports
--skip-dist-cache Skip copying jars to
distributed cache
--username <username> Set authentication
username
--verbose Print more information
while working Import control arguments:
--append Imports data
in append
mode
--as-avrodatafile Imports data
to Avro data
files
--as-parquetfile Imports data
to Parquet
files
--as-sequencefile Imports data
to
SequenceFile
s
--as-textfile Imports data
as plain
text
(default)
--autoreset-to-one-mapper Reset the
number of
mappers to
one mapper
if no split
key
available
--boundary-query <statement> Set boundary
query for
retrieving
max and min
value of the
primary key
--columns <col,col,col...> Columns to
import from
table
--compression-codec <codec> Compression
codec to use
for import
--delete-target-dir Imports data
in delete
mode
--direct Use direct
import fast
path
--direct-split-size <n> Split the
input stream
every 'n'
bytes when
importing in
direct mode
-e,--query <statement> Import
results of
SQL
'statement'
--fetch-size <n> Set number
'n' of rows
to fetch
from the
database
when more
rows are
needed
--inline-lob-limit <n> Set the
maximum size
for an
inline LOB
-m,--num-mappers <n> Use 'n' map
tasks to
import in
parallel
--mapreduce-job-name <name> Set name for
generated
mapreduce
job
--merge-key <column> Key column
to use to
join results
--split-by <column-name> Column of
the table
used to
split work
units
--table <table-name> Table to
read
--target-dir <dir> HDFS plain
table
destination
--validate Validate the
copy using
the
configured
validator
--validation-failurehandler <validation-failurehandler> Fully
qualified
class name
for
ValidationFa
ilureHandler
--validation-threshold <validation-threshold> Fully
qualified
class name
for
ValidationTh
reshold
--validator <validator> Fully
qualified
class name
for the
Validator
--warehouse-dir <dir> HDFS parent
for table
destination
--where <where clause> WHERE clause
to use
during
import
-z,--compress Enable
compression Incremental import arguments:
--check-column <column> Source column to check for incremental
change
--incremental <import-type> Define an incremental import of type
'append' or 'lastmodified'
--last-value <value> Last imported value in the incremental
check column Output line formatting arguments:
--enclosed-by <char> Sets a required field enclosing
character
--escaped-by <char> Sets the escape character
--fields-terminated-by <char> Sets the field separator character
--lines-terminated-by <char> Sets the end-of-line character
--mysql-delimiters Uses MySQL's default delimiter set:
fields: , lines: \n escaped-by: \
optionally-enclosed-by: '
--optionally-enclosed-by <char> Sets a field enclosing character Input parsing arguments:
--input-enclosed-by <char> Sets a required field encloser
--input-escaped-by <char> Sets the input escape
character
--input-fields-terminated-by <char> Sets the input field separator
--input-lines-terminated-by <char> Sets the input end-of-line
char
--input-optionally-enclosed-by <char> Sets a field enclosing
character Hive arguments:
--create-hive-table Fail if the target hive
table exists
--hive-database <database-name> Sets the database name to
use when importing to hive
--hive-delims-replacement <arg> Replace Hive record \0x01
and row delimiters (\n\r)
from imported string fields
with user-defined string
--hive-drop-import-delims Drop Hive record \0x01 and
row delimiters (\n\r) from
imported string fields
--hive-home <dir> Override $HIVE_HOME
--hive-import Import tables into Hive
(Uses Hive's default
delimiters if none are
set.)
--hive-overwrite Overwrite existing data in
the Hive table
--hive-partition-key <partition-key> Sets the partition key to
use when importing to hive
--hive-partition-value <partition-value> Sets the partition value to
use when importing to hive
--hive-table <table-name> Sets the table name to use
when importing to hive
--map-column-hive <arg> Override mapping for
specific column to hive
types. HBase arguments:
--column-family <family> Sets the target column family for the
import
--hbase-bulkload Enables HBase bulk loading
--hbase-create-table If specified, create missing HBase tables
--hbase-row-key <col> Specifies which input column to use as the
row key
--hbase-table <table> Import to <table> in HBase HCatalog arguments:
--hcatalog-database <arg> HCatalog database name
--hcatalog-home <hdir> Override $HCAT_HOME
--hcatalog-partition-keys <partition-key> Sets the partition
keys to use when
importing to hive
--hcatalog-partition-values <partition-value> Sets the partition
values to use when
importing to hive
--hcatalog-table <arg> HCatalog table name
--hive-home <dir> Override $HIVE_HOME
--hive-partition-key <partition-key> Sets the partition key
to use when importing
to hive
--hive-partition-value <partition-value> Sets the partition
value to use when
importing to hive
--map-column-hive <arg> Override mapping for
specific column to
hive types. HCatalog import specific options:
--create-hcatalog-table Create HCatalog before import
--hcatalog-storage-stanza <arg> HCatalog storage stanza for table
creation Accumulo arguments:
--accumulo-batch-size <size> Batch size in bytes
--accumulo-column-family <family> Sets the target column family for
the import
--accumulo-create-table If specified, create missing
Accumulo tables
--accumulo-instance <instance> Accumulo instance name.
--accumulo-max-latency <latency> Max write latency in milliseconds
--accumulo-password <password> Accumulo password.
--accumulo-row-key <col> Specifies which input column to
use as the row key
--accumulo-table <table> Import to <table> in Accumulo
--accumulo-user <user> Accumulo user name.
--accumulo-visibility <vis> Visibility token to be applied to
all rows imported
--accumulo-zookeepers <zookeepers> Comma-separated list of
zookeepers (host:port) Code generation arguments:
--bindir <dir> Output directory for compiled
objects
--class-name <name> Sets the generated class name.
This overrides --package-name.
When combined with --jar-file,
sets the input class.
--input-null-non-string <null-str> Input null non-string
representation
--input-null-string <null-str> Input null string representation
--jar-file <file> Disable code generation; use
specified jar
--map-column-java <arg> Override mapping for specific
columns to java types
--null-non-string <null-str> Null non-string representation
--null-string <null-str> Null string representation
--outdir <dir> Output directory for generated
code
--package-name <name> Put auto-generated classes in
this package Generic Hadoop command-line arguments:
(must preceed any tool-specific arguments)
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions] At minimum, you must specify --connect and --table
Arguments to mysqldump and other subprograms may be supplied
after a '--' on the command line.
2、列出MySQL数据有哪些数据库
[root@node101 ~]# sqoop list-databases --connect jdbc:mysql://node102:3306/ --username root --password 123456
Warning: /usr/local/sqoop-1.4./../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop-1.4./../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4./../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4./../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
mysql
performance_schema
sys
3、列出MySQL中的某个数据库有哪些数据表:
[root@node101 ~]# sqoop list-tables --connect jdbc:mysql://node102:3306/mysql --username root --password 123456
Warning: /usr/local/sqoop-1.4./../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop-1.4./../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4./../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4./../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
columns_priv
db
engine_cost
event
func
general_log
gtid_executed
help_category
help_keyword
help_relation
help_topic
innodb_index_stats
innodb_table_stats
ndb_binlog_index
plugin
proc
procs_priv
proxies_priv
server_cost
servers
slave_master_info
slave_relay_log_info
slave_worker_info
slow_log
tables_priv
time_zone
time_zone_leap_second
time_zone_name
time_zone_transition
time_zone_transition_type
user
二、导入
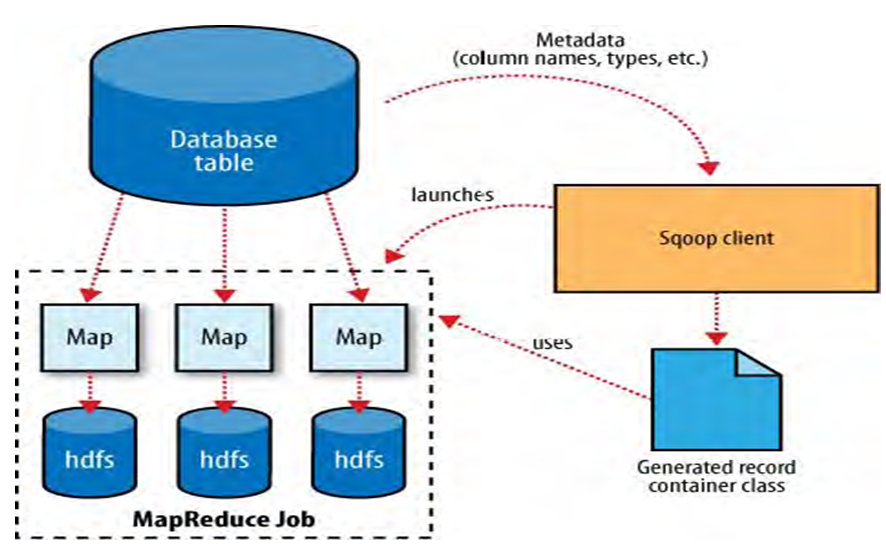
从mysql数据导入到HDFS
(1)普通导入:导入mysql库中的help_keyword的数据到HDFS上
sqoop import \
--connect jdbc:mysql://node102:3306/mysql \
--username root \
--password \
--table help_keyword \
-m
#-m指并行任务数
如果不指定目录,默认导入目录是:/user/root/help_keyword
[root@node101 ~]# sqoop import \
> --connect jdbc:mysql://node102:3306/mysql \
> --username root \
> --password \
> --table help_keyword \
> -m
Warning: /usr/local/sqoop-1.4./../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop-1.4./../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4./../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4./../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
// :: INFO tool.CodeGenTool: Beginning code generation
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `help_keyword` AS t LIMIT
// :: INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `help_keyword` AS t LIMIT
// :: INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop-2.6.
Note: /tmp/sqoop-root/compile/7f309ccd42353a370234a9552dace7e3/help_keyword.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
// :: INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/7f309ccd42353a370234a9552dace7e3/help_keyword.jar
// :: WARN manager.MySQLManager: It looks like you are importing from mysql.
// :: WARN manager.MySQLManager: This transfer can be faster! Use the --direct
// :: WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
// :: INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
// :: INFO mapreduce.ImportJobBase: Beginning import of help_keyword
// :: INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
// :: INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
// :: INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
// :: INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
// :: INFO db.DBInputFormat: Using read commited transaction isolation
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1498908125_0001
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-hadoop-1.4..jar <- /root/parquet-hadoop-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-hadoop-1.4..jar as file:/opt/hadoop/mapred/local//parquet-hadoop-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//commons-logging-1.1..jar <- /root/commons-logging-1.1..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/commons-logging-1.1..jar as file:/opt/hadoop/mapred/local//commons-logging-1.1..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-jackson-1.4..jar <- /root/parquet-jackson-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-jackson-1.4..jar as file:/opt/hadoop/mapred/local//parquet-jackson-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//avro-mapred-1.7.-hadoop2.jar <- /root/avro-mapred-1.7.-hadoop2.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/avro-mapred-1.7.-hadoop2.jar as file:/opt/hadoop/mapred/local//avro-mapred-1.7.-hadoop2.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//jackson-mapper-asl-1.9..jar <- /root/jackson-mapper-asl-1.9..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/jackson-mapper-asl-1.9..jar as file:/opt/hadoop/mapred/local//jackson-mapper-asl-1.9..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-encoding-1.4..jar <- /root/parquet-encoding-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-encoding-1.4..jar as file:/opt/hadoop/mapred/local//parquet-encoding-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-avro-1.4..jar <- /root/parquet-avro-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-avro-1.4..jar as file:/opt/hadoop/mapred/local//parquet-avro-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//kite-data-core-1.0..jar <- /root/kite-data-core-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/kite-data-core-1.0..jar as file:/opt/hadoop/mapred/local//kite-data-core-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//sqoop-1.4..jar <- /root/sqoop-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./sqoop-1.4..jar as file:/opt/hadoop/mapred/local//sqoop-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-column-1.4..jar <- /root/parquet-column-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-column-1.4..jar as file:/opt/hadoop/mapred/local//parquet-column-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-generator-1.4..jar <- /root/parquet-generator-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-generator-1.4..jar as file:/opt/hadoop/mapred/local//parquet-generator-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//xz-1.0.jar <- /root/xz-1.0.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/xz-1.0.jar as file:/opt/hadoop/mapred/local//xz-1.0.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//paranamer-2.3.jar <- /root/paranamer-2.3.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/paranamer-2.3.jar as file:/opt/hadoop/mapred/local//paranamer-2.3.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//jackson-core-asl-1.9..jar <- /root/jackson-core-asl-1.9..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/jackson-core-asl-1.9..jar as file:/opt/hadoop/mapred/local//jackson-core-asl-1.9..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//snappy-java-1.0..jar <- /root/snappy-java-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/snappy-java-1.0..jar as file:/opt/hadoop/mapred/local//snappy-java-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//jackson-core-2.3..jar <- /root/jackson-core-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/jackson-core-2.3..jar as file:/opt/hadoop/mapred/local//jackson-core-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-common-1.4..jar <- /root/parquet-common-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-common-1.4..jar as file:/opt/hadoop/mapred/local//parquet-common-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//commons-io-1.4.jar <- /root/commons-io-1.4.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/commons-io-1.4.jar as file:/opt/hadoop/mapred/local//commons-io-1.4.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//mysql-connector-java-5.1.-bin.jar <- /root/mysql-connector-java-5.1.-bin.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/mysql-connector-java-5.1.-bin.jar as file:/opt/hadoop/mapred/local//mysql-connector-java-5.1.-bin.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//hsqldb-1.8.0.10.jar <- /root/hsqldb-1.8.0.10.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/hsqldb-1.8.0.10.jar as file:/opt/hadoop/mapred/local//hsqldb-1.8.0.10.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//parquet-format-2.0..jar <- /root/parquet-format-2.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/parquet-format-2.0..jar as file:/opt/hadoop/mapred/local//parquet-format-2.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//slf4j-api-1.6..jar <- /root/slf4j-api-1.6..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/slf4j-api-1.6..jar as file:/opt/hadoop/mapred/local//slf4j-api-1.6..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//commons-jexl-2.1..jar <- /root/commons-jexl-2.1..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/commons-jexl-2.1..jar as file:/opt/hadoop/mapred/local//commons-jexl-2.1..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//jackson-annotations-2.3..jar <- /root/jackson-annotations-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/jackson-annotations-2.3..jar as file:/opt/hadoop/mapred/local//jackson-annotations-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//kite-hadoop-compatibility-1.0..jar <- /root/kite-hadoop-compatibility-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/kite-hadoop-compatibility-1.0..jar as file:/opt/hadoop/mapred/local//kite-hadoop-compatibility-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//ant-eclipse-1.0-jvm1..jar <- /root/ant-eclipse-1.0-jvm1..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/ant-eclipse-1.0-jvm1..jar as file:/opt/hadoop/mapred/local//ant-eclipse-1.0-jvm1..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//opencsv-2.3.jar <- /root/opencsv-2.3.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/opencsv-2.3.jar as file:/opt/hadoop/mapred/local//opencsv-2.3.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//jackson-databind-2.3..jar <- /root/jackson-databind-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/jackson-databind-2.3..jar as file:/opt/hadoop/mapred/local//jackson-databind-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//ant-contrib-.0b3.jar <- /root/ant-contrib-.0b3.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/ant-contrib-.0b3.jar as file:/opt/hadoop/mapred/local//ant-contrib-.0b3.jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//avro-1.7..jar <- /root/avro-1.7..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/avro-1.7..jar as file:/opt/hadoop/mapred/local//avro-1.7..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//kite-data-hive-1.0..jar <- /root/kite-data-hive-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/kite-data-hive-1.0..jar as file:/opt/hadoop/mapred/local//kite-data-hive-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//kite-data-mapreduce-1.0..jar <- /root/kite-data-mapreduce-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/kite-data-mapreduce-1.0..jar as file:/opt/hadoop/mapred/local//kite-data-mapreduce-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//commons-compress-1.4..jar <- /root/commons-compress-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/commons-compress-1.4..jar as file:/opt/hadoop/mapred/local//commons-compress-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: Creating symlink: /opt/hadoop/mapred/local//commons-codec-1.4.jar <- /root/commons-codec-1.4.jar
// :: INFO mapred.LocalDistributedCacheManager: Localized file:/usr/local/sqoop-1.4./lib/commons-codec-1.4.jar as file:/opt/hadoop/mapred/local//commons-codec-1.4.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-hadoop-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//commons-logging-1.1..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-jackson-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//avro-mapred-1.7.-hadoop2.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//jackson-mapper-asl-1.9..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-encoding-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-avro-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//kite-data-core-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//sqoop-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-column-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-generator-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//xz-1.0.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//paranamer-2.3.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//jackson-core-asl-1.9..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//snappy-java-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//jackson-core-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-common-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//commons-io-1.4.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//mysql-connector-java-5.1.-bin.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//hsqldb-1.8.0.10.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//parquet-format-2.0..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//slf4j-api-1.6..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//commons-jexl-2.1..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//jackson-annotations-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//kite-hadoop-compatibility-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//ant-eclipse-1.0-jvm1..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//opencsv-2.3.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//jackson-databind-2.3..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//ant-contrib-.0b3.jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//avro-1.7..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//kite-data-hive-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//kite-data-mapreduce-1.0..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//commons-compress-1.4..jar
// :: INFO mapred.LocalDistributedCacheManager: file:/opt/hadoop/mapred/local//commons-codec-1.4.jar
// :: INFO mapreduce.Job: The url to track the job: http://localhost:8080/
// :: INFO mapreduce.Job: Running job: job_local1498908125_0001
// :: INFO mapred.LocalJobRunner: OutputCommitter set in config null
// :: INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
// :: INFO mapred.LocalJobRunner: Waiting for map tasks
// :: INFO mapred.LocalJobRunner: Starting task: attempt_local1498908125_0001_m_000000_0
// :: INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
// :: INFO db.DBInputFormat: Using read commited transaction isolation
// :: INFO mapred.MapTask: Processing split: = AND =
// :: INFO db.DBRecordReader: Working on split: = AND =
// :: INFO db.DBRecordReader: Executing query: SELECT `help_keyword_id`, `name` FROM `help_keyword` AS `help_keyword` WHERE ( = ) AND ( = )
// :: INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
// :: INFO mapred.LocalJobRunner:
// :: INFO mapreduce.Job: Job job_local1498908125_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapred.Task: Task:attempt_local1498908125_0001_m_000000_0 is done. And is in the process of committing
// :: INFO mapred.LocalJobRunner:
// :: INFO mapred.Task: Task attempt_local1498908125_0001_m_000000_0 is allowed to commit now
// :: INFO output.FileOutputCommitter: Saved output of task 'attempt_local1498908125_0001_m_000000_0' to hdfs://node101:8020/user/root/help_keyword/_temporary/0/task_local1498908125_0001_m_000000
// :: INFO mapred.LocalJobRunner: map
// :: INFO mapred.Task: Task 'attempt_local1498908125_0001_m_000000_0' done.
// :: INFO mapred.LocalJobRunner: Finishing task: attempt_local1498908125_0001_m_000000_0
// :: INFO mapred.LocalJobRunner: map task executor complete.
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_local1498908125_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ImportJobBase: Transferred 9.5195 KB in 5.2139 seconds (1.8258 KB/sec)
// :: INFO mapreduce.ImportJobBase: Retrieved records.
查看导入数据:
[root@node101 ~]# hdfs dfs -cat /user/root/help_keyword/part-m-
,(JSON
,->
,->>
,<>
,ACCOUNT
,ACTION
,ADD
,AES_DECRYPT
.
.
.
(2)导入: 指定分隔符和导入路径
sqoop import \
--connect jdbc:mysql://node102:3306/mysql \
--username root \
--password \
--table help_keyword \
--target-dir /sqoop/mysql/my_help_keyword1 \
--fields-terminated-by '\t'
-m
查看导入数据:
[root@node101 ~]# hdfs dfs -cat /sqoop/mysql/my_help_keyword1/part-m-
SQLSTATE
SQL_AFTER_GTIDS
SQL_AFTER_MTS_GAPS
SQL_BEFORE_GTIDS
SQL_BIG_RESULT
SQL_BUFFER_RESULT
SQL_CACHE
(3)导入数据:带where条件
sqoop import \
--connect jdbc:mysql://node102:3306/mysql \
--username root \
--password \
--table help_keyword \
--where "name='STRING' " \
--target-dir /sqoop/mysql/my_help_keyword2 \
-m
查看导入数据:
[root@node101 ~]# hdfs dfs -cat /sqoop/mysql/my_help_keyword2/part-m-
,STRING
(4)查询指定列
sqoop import \
--connect jdbc:mysql://node102:3306/mysql \
--username root \
--password \
--columns "name" \
--table help_keyword \
--where "name='STRING' " \
--target-dir /sqoop/mysql/my_help_keyword3 \
-m
查看导入数据:
[root@node101 ~]# hdfs dfs -cat /sqoop/mysql/my_help_keyword3/part-m-
STRING
(5)指定自定义查询SQL
sqoop import \
--connect jdbc:mysql://node102:3306/mysql \
--username root \
--password \
--query 'select help_keyword_id,name from mysql.help_keyword where $CONDITIONS and name = "STRING"' \
--split-by help_keyword_id \
--fields-terminated-by '\t' \
--target-dir /sqoop/mysql/my_help_keyword4 \
-m
查看导入数据:
[root@node101 ~]# hdfs dfs -cat /sqoop/mysql/my_help_keyword4/part-m-
STRING
注意:
在以上需要按照自定义SQL语句导出数据到HDFS的情况下:
1、引号问题,要么外层使用单引号,内层使用双引号,$CONDITIONS的$符号不用转义, 要么外层使用双引号,那么内层使用单引号,然后$CONDITIONS的$符号需要转义
2、自定义的SQL语句中必须带有WHERE $CONDITIONS
三、导出
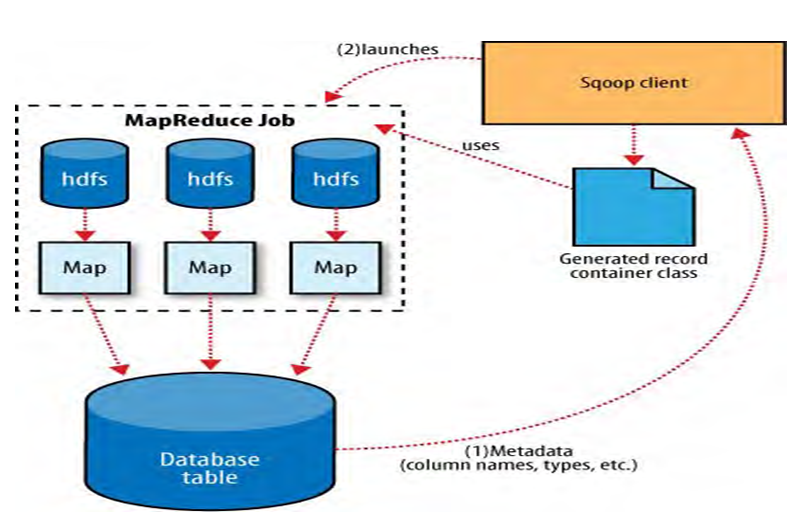
将HDFS数据导出到mysql
sqoop export \
--connect jdbc:mysql://node102:3306/hdfs \
--username root \
--password \
--table help_keyword \
--input-fields-terminated-by "\t" \
--export-dir /sqoop/mysql/my_help_keyword1 \
-m
最新文章
- (原创)JS闭包看代码理解
- Squid 操作实践
- 让git忽略文件模式的改变
- Path,Files巩固,题目:从键盘接收两个文件夹路径,把其中一个文件夹中(包含内容)拷贝到另一个文件夹中
- linux 开机自动启动脚本方法
- 杭电ACM2084--数塔
- String与StringBuilder
- 基于 USB 传输的针式打印机驱动程序开发
- Redis事务原理分析
- The component and implementation of a basic gradient descent in python
- 记录线上与本地docker镜像一致,但Dockerfile却构建失败的问题
- minitab的鱼骨图的制作
- ios 获取视频截图
- jenkins之从0到1利用Git和Ant插件打war包并自动部署到tomcat(第一话):初次启动jenkins,输入给定密码后登录失败问题解决
- Java远程通讯技术及原理分析
- CSS 小结笔记之BFC
- BZOJ 2761 不重复数字 set
- mfc 动态创建EDIT控件
- smartsvn学习(一)Xcode下svn客户端使用指南
- 利用样式——android2.3实现android4.0风格的edittext