PyTorch DataLoader NumberWorkers Deep Learning Speed Limit Increase
2024-09-03 07:44:04


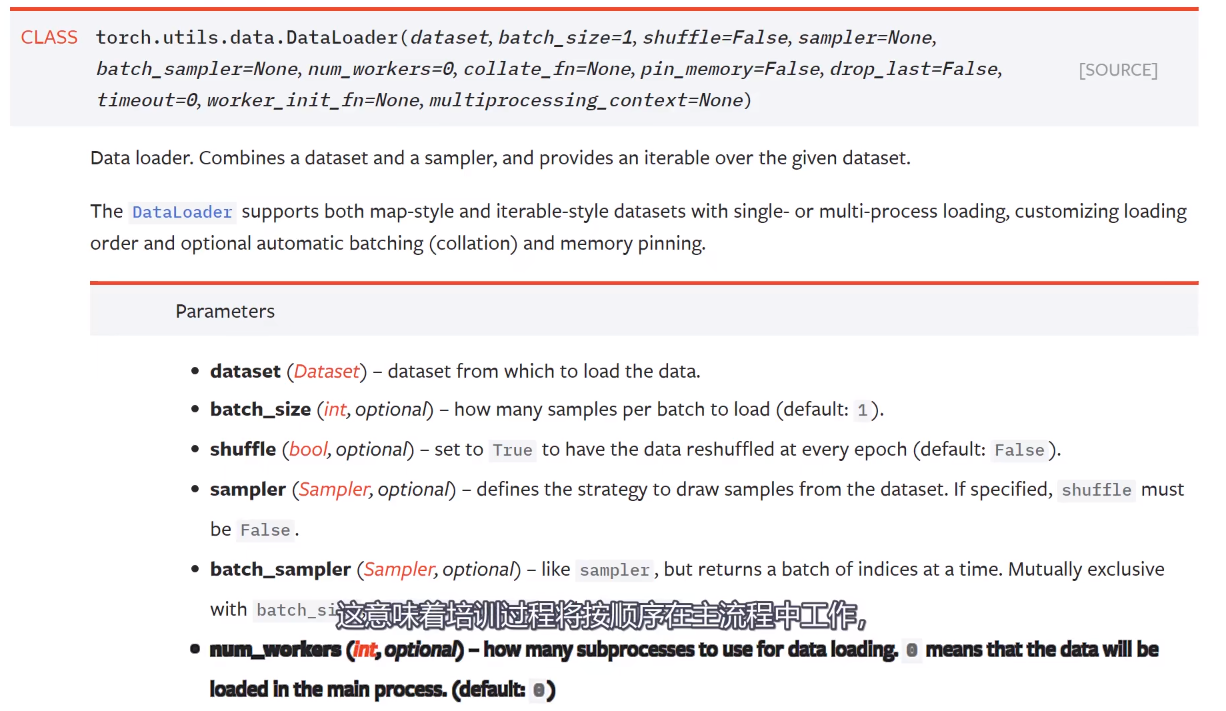
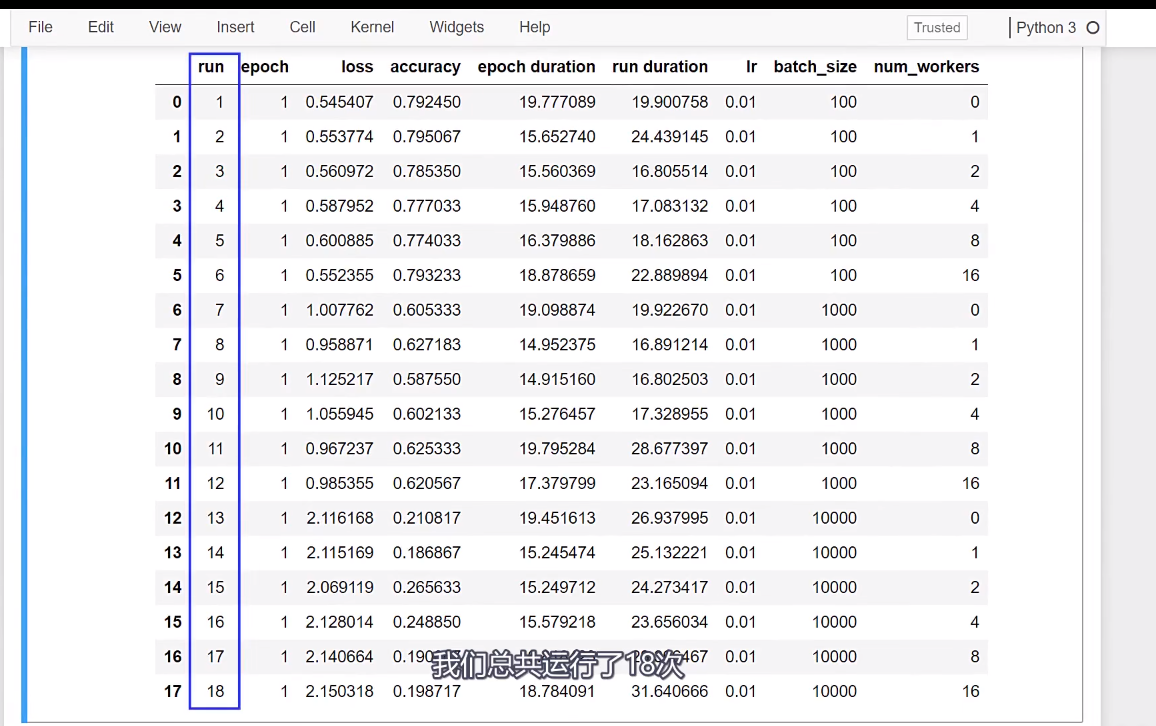
这意味着训练过程将按顺序在主流程中工作。
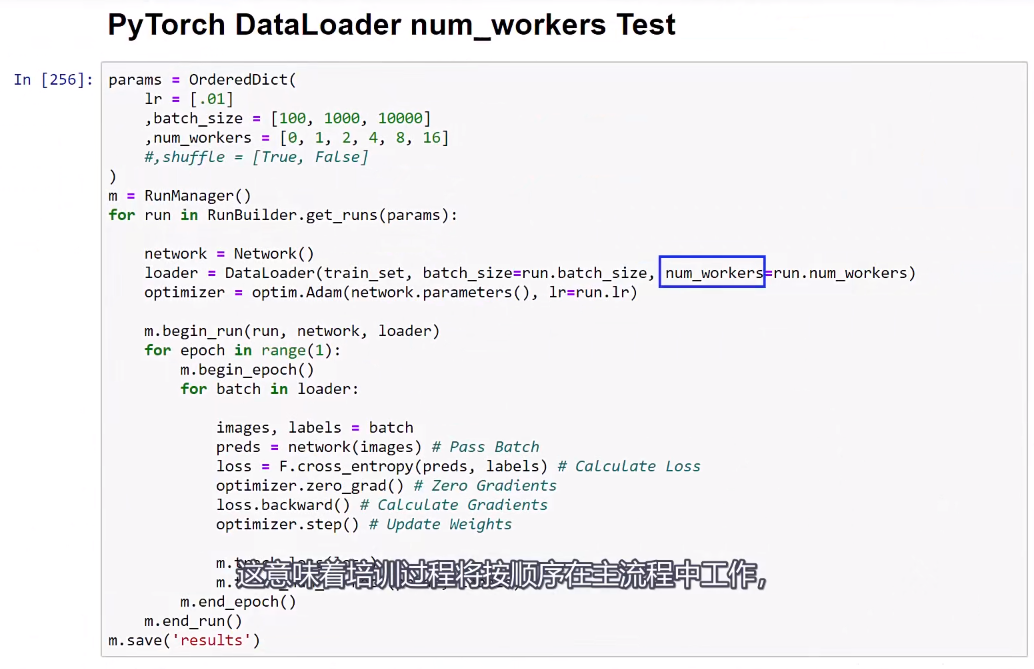




 即:run.num_workers。
即:run.num_workers。










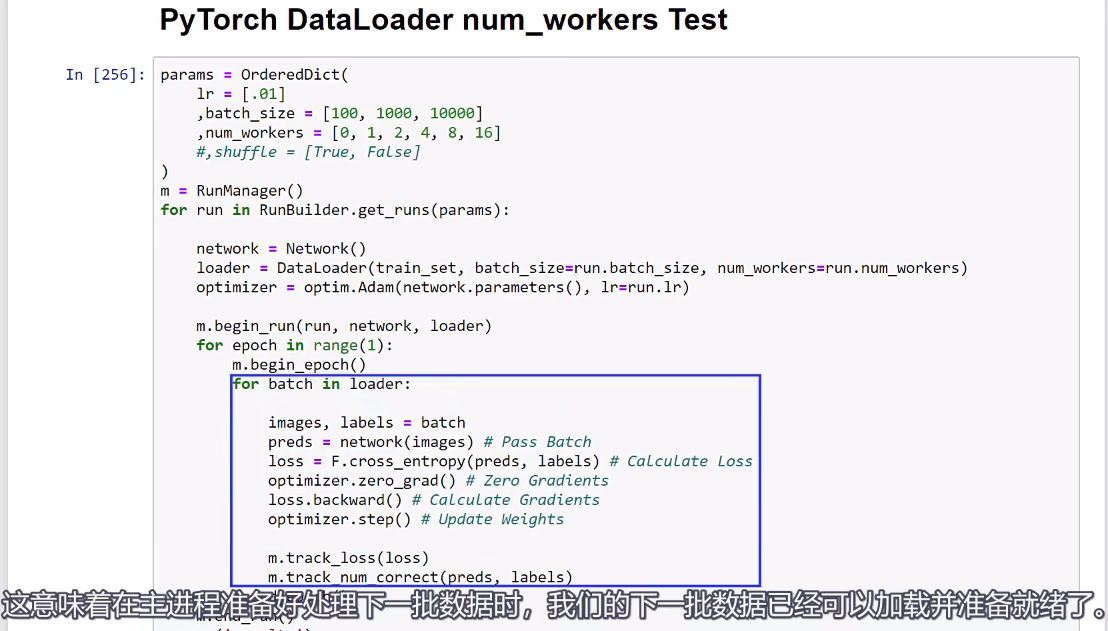
 ,此外,
,此外,





 ,因此,主进程不需要从磁盘读取数据;相反,这些数据已经在内存中准备好了。
,因此,主进程不需要从磁盘读取数据;相反,这些数据已经在内存中准备好了。
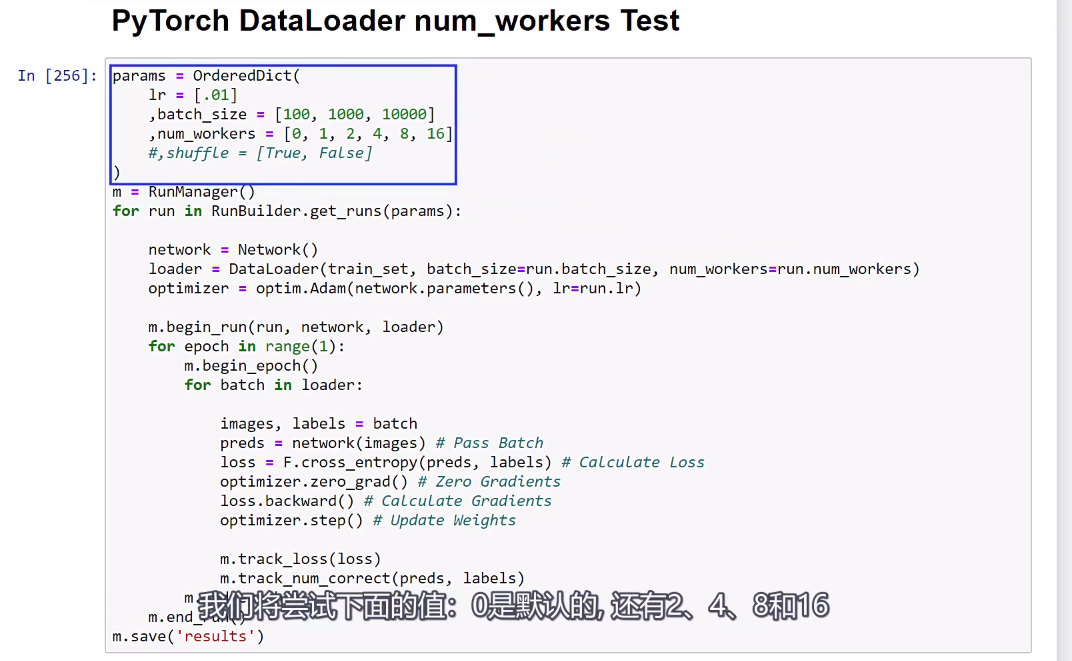
这个例子中,我们看到了20%的加速效果,那么你可能会想, 


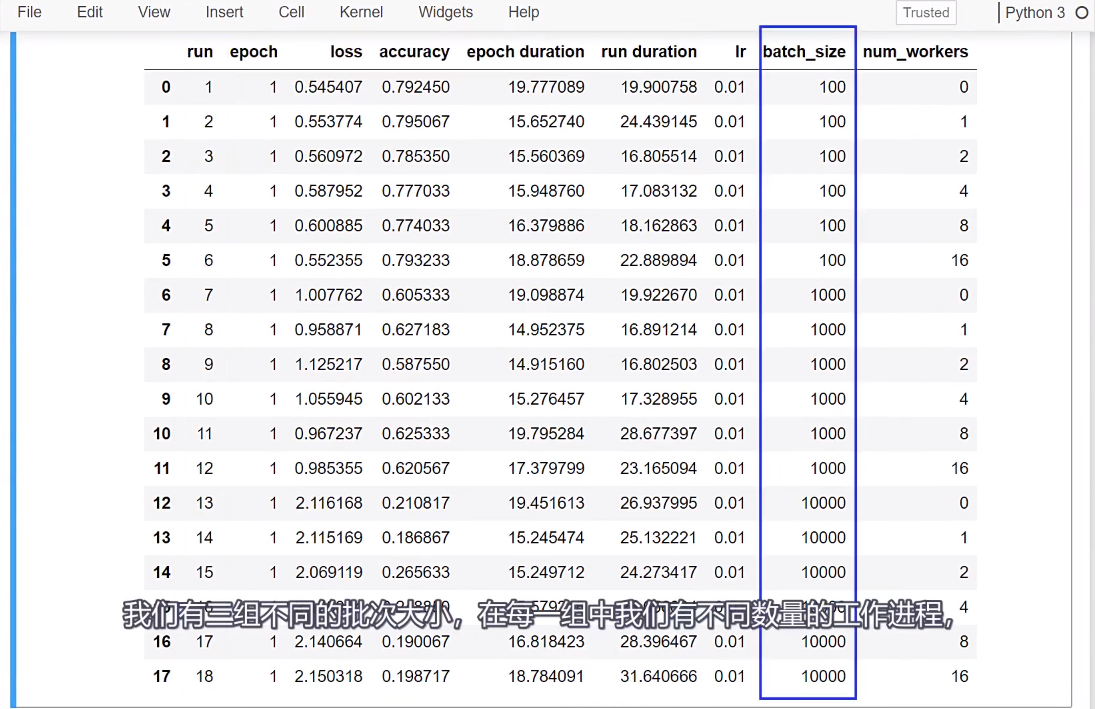
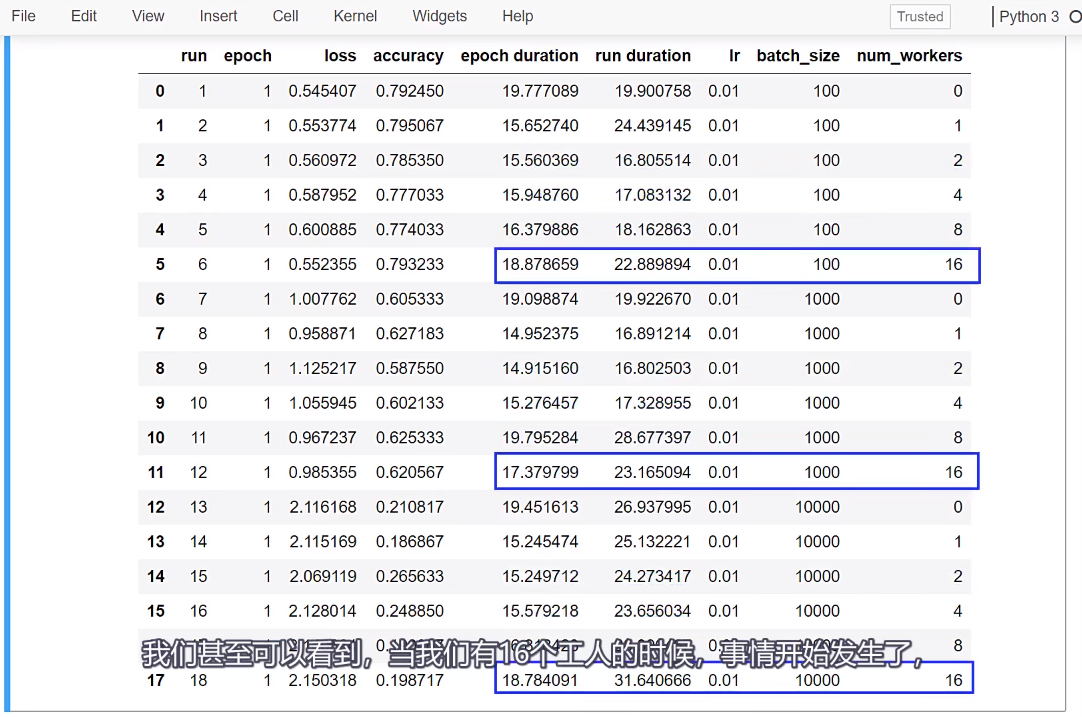
我们考虑一个工人可能足够让队列中充满了主进程的数据,然后将更多的数据添加到队列中,不会在速度上做任何事情。我们在这里看到的就是这些,
只是我们在队列中添加了更多的批次,是否意味着这些批次的加工速度更快?因此,我们受到前向和后向传播所花费的时间的限制,




保存模型,用torch.save()








最新文章
- 邮箱、手机号、中文 js跟php正则验证
- 源程序出现各种奇怪的符号P
- 火箭18号秀光膀为父母割草(FW)
- (六)6.17 Neurons Networks convolutional neural network(cnn)
- 输入内容, 列出可选的项: QComboBox
- Socket,非阻塞,fcntl
- 详解CMS垃圾回收机制
- Windows 8 键盘上推自定义处理
- angular drag and drop (ngDraggable) 笔记
- mycat环境搭建
- python入门 -- 学习笔记4
- Codeforces Round #539 (Div. 2) D 思维
- MongoDB-Oplog详解
- Android的Databinding-普通绑定
- AMAZON数据集
- Quartz2D绘制路径
- javascrpt 代码
- Go第二篇之基本语法总结
- Linux中CPU亲和性(go)
- 漫谈NIO(2)之Java的NIO