CentOS7.6搭建Hadoop2.7.2运行环境-三节点集群模式
一 环境准备
1. 准备机器
2. 修改静态IP
3. 修改主机名
4. 关闭防火墙
5. 创建普通用户hadoop
添加hadoop用户
[root@hadoop102 ~]#useradd hadoop
设置密码
[root@hadoop102 ~]#passwd hadoop
6. 配置hadoop用户具有root权限
修改配置文件
[root@hadoop102 ~]#vi /etc/sudoers
修改 /etc/sudoers 文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
或者配置成采用sudo命令时,不需要输入密码
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL
修改完毕,现在可以用hadoop帐号登录,然后用命令 sudo ,即可获得root权限进行操作。
7.在/opt目录下创建文件夹
(1)在/opt目录下创建module、software文件夹
[hadoop@hadoop102 opt]$ sudo mkdir module
[hadoop@hadoop102 opt]$ sudo mkdir software
(2)修改module、software文件夹的所有者cd
[hadoop@hadoop102 opt]$ sudo chown hadoop:hadoop module/ software/
[hadoop@hadoop102 opt]$ ll
总用量 8
drwxr-xr-x. 2 hadoop hadoop 4096 1月 17 14:37 module
drwxr-xr-x. 2 hadoop hadoop 4096 1月 17 14:38 software
8.修改hosts文件
分别在3台机器上修改/etc/hosts文件
sudo vi /etc/hosts
添加如下内容
192.168.194.102 hadoop102
192.168.194.103 hadoop103
192.168.194.104 hadoop104
9. SSH无密登录配置
(1)生成公钥和私钥:
[hadoop@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(2)将公钥拷贝到要免密登录的目标机器上
[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop102
[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop103
[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop104
注意:
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
还需要在hadoop103上采用hadoop账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
二 安装JDK
1. 卸载现有JDK
(1)查询是否安装Java软件:
[root@hadoop102 opt]$ rpm -qa | grep java
(2)如果安装的版本低于1.7,卸载该JDK:
[root@hadoop102 opt]$ sudo rpm -e 软件包
(3)查看JDK安装路径:
[root@hadoop102 ~]$ which java
2.下载jdk8
最新jdk8下载地址
登录网址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
jdk历史版本下载地址
oracle官网jdk历史下载页面:https://www.oracle.com/technetwork/java/javase/archive-139210.html
3.切换到root用户
su root 获取root用户权限,当前工作目录不变(需要root密码) 或 sudo -i 不需要root密码直接切换成root(需要当前用户密码)
4.上传解压
将jdk安装包上传到服务器并解压
解压:tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/local
5.配置环境变量
编辑配置文件 /etc/profile
vim /etc/profile
末尾添加如下内容:JAVA_HOME根据实际目录来
export JAVA_HOME=/usr/local/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH
6.重新加载环境变量配置文件
[root@hadoop102 ~]# source /etc/profile
7.查看安装版本情况
[root@hadoop102 ~]# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
8.按照如上步骤在其他服务器上安装jdk
三 安装Hadoop
1.Hadoop下载地址:
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
2.上传解压
将hadoop-2.7.2.tar.gz安装包上传到第一台服务器的到opt/software文件夹下面
3.解压安装文件到/opt/module下面
cd /opt/software/
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
查看是否解压成功
[hadoop@hadoop102 software]$ ls /opt/module/
hadoop-2.7.2
4.将Hadoop添加到环境变量
获取Hadoop安装路径
[hadoop@hadoop102 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
打开/etc/profile文件
[hadoop@hadoop102 hadoop-2.7.2]$ sudo vi /etc/profile
在profile文件末尾添加Hadoop环境变量路径:(shitf+g)
## HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存后退出
:wq
让修改后的文件生效
[hadoop@ hadoop102 hadoop-2.7.2]$ source /etc/profile
5.测试是否安装成功
[hadoop@hadoop102 hadoop-2.7.2]$ hadoop version
Hadoop 2.7.2
6.Hadoop目录结构
查看Hadoop目录结构
[hadoop@hadoop102 hadoop-2.7.2]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5月 22 2017 share
重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
四 Hadoop集群配置
1.集群部署规划
|
hadoop102 |
hadoop103 |
hadoop104 |
|
|
HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2.编辑配置文件
(1)核心配置文件
配置core-site.xml
[hadoop@hadoop102 hadoop]$ vi core-site.xml
在该文件中编写如下配置
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property> <!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(2)HDFS配置文件
配置hadoop-env.sh
[atguigu@hadoop102 hadoop]$ vi hadoop-env.sh
修改JAVA_HOME的环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_191
配置hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vi hdfs-site.xml
在该文件中编写如下配置
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
(3)YARN配置文件
配置yarn-env.sh
[atguigu@hadoop102 hadoop]$ vi yarn-env.sh
修改JAVA_HOME的环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_191
配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vi yarn-site.xml
在该文件中增加如下配置
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
(4)MapReduce配置文件
配置mapred-env.sh
修改JAVA_HOME的环境变量
[atguigu@hadoop102 hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[atguigu@hadoop102 hadoop]$ vi mapred-site.xml
在该文件中增加如下配置
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(4)配置slaves
cd /opt/module/hadoop-2.7.2/etc/hadoop/slaves
[hadoop@hadoop102 hadoop]$ vi slaves
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行
3.分发
将/opt/module/hadoop-2.7.2/目录分发到其他服务器
scp -r /opt/module/hadoop-2.7.2/ root@hadoop103:/opt/module
scp -r /opt/module/hadoop-2.7.2/ root@hadoop104:/opt/module
五 启动测试
1.格式化集群
集群第一次启动,需要格式化NameNode
[hadoop@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
如果需要重新格式化,需要先停止启动的所有namenode和datanode进程,然后删除data和log数据,重新执行bin/hdfs namenode -format命令
2.启动hdfs
在主节点上执行
[hadoop@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
查看启动进程
[hadoop@hadoop102 hadoop-2.7.2]$ jps
1345 NameNode
5443 Jps
4356 DataNode
[hadoop@hadoop103 hadoop-2.7.2]$ jps
9382 DataNode
3948 Jps
[hadoop@hadoop104 hadoop-2.7.2]$ jps
3438 DataNode
2345 SecondaryNameNode
2456 Jps
3.启动YARN
[hadoop@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
4.查看web页面
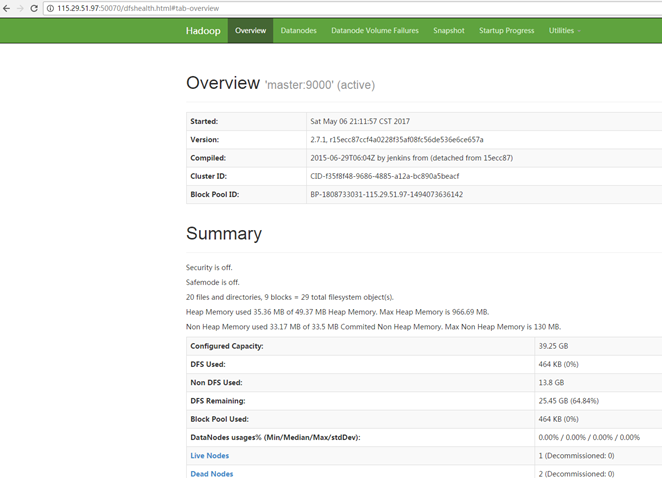
hdfs web页面 http://hadoop102:50070/
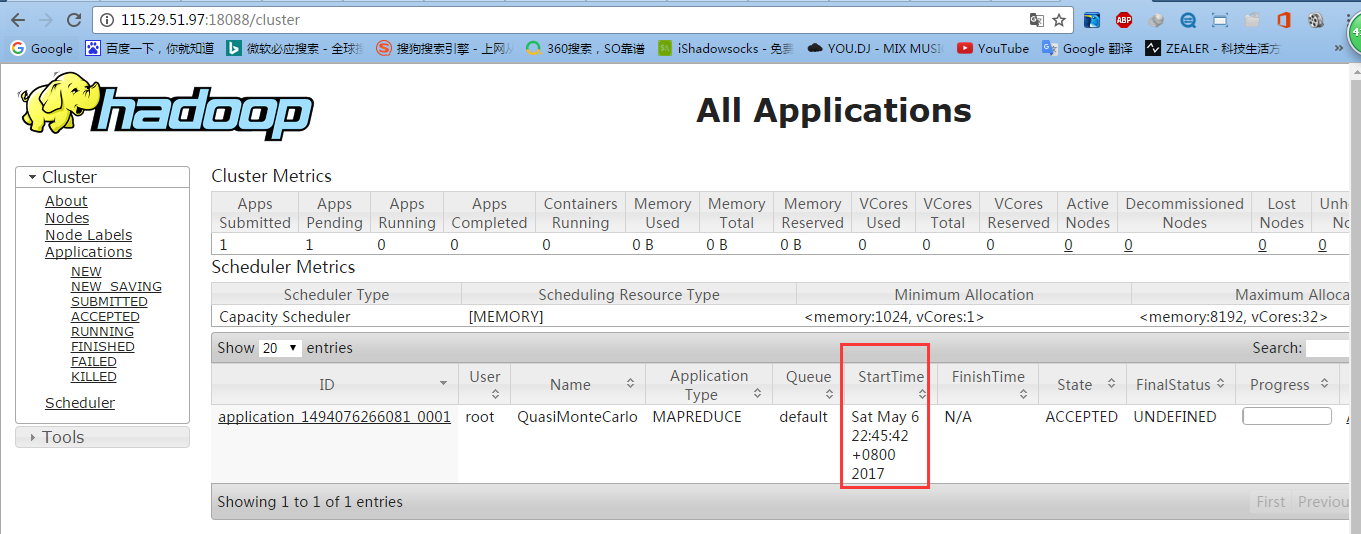
yarn web页面 http://hadoop103:18088/
最新文章
- 关于控件的Invoke(...)方法和BeginInvoke(...)方法的区别
- 【BZOJ】1006: [HNOI2008]神奇的国度
- CSS之border
- python之获取页面标签的方法
- NOP登录验证管理
- iOS开发:Swift多线程NSOperation的使用
- CSS基础(01)
- 通过命令行连接oracle数据库/进入sql plus
- Java面试宝典2013版(超长版)
- 安卓webview下使用zepto的swipe失效
- Sumsets(完全背包)
- C语言,题目:函数调用,内存,malloc找错
- WorkFlow介绍及用法
- FFmepg 如何在 window 上使用?
- how tomcat works 读书笔记(二)----------一个简单的servlet容器
- IntelliJ IDEA配置maven远程仓库
- React 入门学习笔记整理(五)—— state
- C++遍历目录和文件夹
- solr 5.5使用 和pyg里 的4.10.3版 部署到tomcat中不一样(不使用内置jetty)
- 如何成为一名合格的Android工程师?
热门文章
- 利用Hutool-(Java工具类)实现验证码校验
- 论文解读(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》
- linux下rsync的同步
- 第三方库openPyxl读取excel文件
- 2.CBV和类视图as_view源码解析
- AIR32F103(三) Linux环境基于标准外设库的项目模板
- go基础语法50问,来看看你的go基础合格了吗?
- static 关键字分析
- Android 跨进程渲染
- python基础类型,字符串