Hive详解(02) - Hive 3.1.2安装
Hive详解(02) - Hive 3.1.2安装
安装准备
Hive下载地址
Hive官网地址:http://hive.apache.org/
官方文档查看地址:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
安装包下载地址:http://archive.apache.org/dist/hive/
github地址:https://github.com/apache/hive
环境准备
JDK:Hive和Hadoop使用java语言编写,需要JDK环境。本文使用jdk1.8版本,安装文档《linux安装jdk8》
Hadoop:Hive使用HDFS进行存储,使用MapReduce进行计算。本文使用Hadoop3.1.3版本,安装文档《Hadoop详解(02) - Hadoop3.1.3集群运行环境搭建》
Hive安装部署
安装Hive
把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/software目录下
解压apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
[hadoop@hadoop102 ~]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
修改apache-hive-3.1.2-bin.tar.gz的名称为hive
[hadoop@hadoop102 ~]$ mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
[hadoop@hadoop102 conf]$ cp hive-env.sh.template hive-env.sh
[hadoop@hadoop102 conf]$ vi hive-env.sh
HADOOP_HOME= /opt/module/hadoop-3.1.3
export HIVE_CONF_DIR=/opt/module/hive/conf
[hadoop@hadoop102 ~]$ sudo vi /etc/profile
export PATH=$PATH:$HIVE_HOME/bin
[hadoop@hadoop102 ~]$ source /etc/profile
Hive元数据配置到MySql
将MySQL的JDBC驱动mysql-connector-java-5.1.48.jar拷贝到Hive的lib目录下
[hadoop@hadoop102 ~]$ cp /opt/software/mysql-connector-java-5.1.48.jar /opt/module/hive/lib/
在/opt/module/hive/conf目录下新建hive-site.xml文件
[hadoop@hadoop102 ~]$ cd /opt/module/hive/conf/
[hadoop@hadoop102 conf]$ vi hive-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<name>javax.jdo.option.ConnectionUserName</name>
<name>javax.jdo.option.ConnectionPassword</name>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<name>hive.metastore.schema.verification</name>
<name>hive.metastore.event.db.notification.api.auth</name>
[hadoop@hadoop102 ~]$ mysql -uadmin -pAbc_123456
mysql> create database metastore;
[hadoop@hadoop102 ~]$ schematool -initSchema -dbType mysql –verbose
执行初始化Hive元数据库命令后,可以在mysql的metastore库中看到创建的表
启动Hive
[hadoop@hadoop102 ~]$ cd /opt/module/hive/
[hadoop@hadoop102 hive]$ bin/hive
hive> create table test (id int);
hive> insert into test values(1);
Hive常见属性配置
在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
<name>hive.cli.print.header</name>
<name>hive.cli.print.current.db</name>

Hive的log默认存放在/tmp/当前用户名/hive.log目录下(当前用户名下)
修改hive的log存放日志到/opt/module/hive/logs
修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为hive-log4j.properties
[hadoop@hadoop102 hadoop]$ cd /opt/module/hive/conf/
[hadoop@hadoop102 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties
在hive-log4j.properties文件中修改log存放位置
property.hive.log.dir = /opt/module/hive/logs
另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
[hadoop@hadoop102 hive]$ bin/hive -hiveconf mapred.reduce.tasks=10;
hive (default)> set mapred.reduce.tasks;
hive (default)> set mapred.reduce.tasks=100;
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
使用元数据MetaStore服务的方式访问Hive
2 Hive先连接MetaStore服务,再通过MetaStore服务连接MySQL获取元数据
Hive既是客户端(是HDFS的客户端也是MetaStore的客户端,也是Hive的客户端)又是服务端(因为有MetaStore服务和Hiveserver2服务配置)
在Hive的配置文件hive-site.xml 中是否配置了hive.metastore.uris参数,

如果想用第一种方式连接的话,需要把上面的配置注释掉
,还必需保证有如下mysql链接配置
<name>javax.jdo.option.ConnectionURL</name>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<name>javax.jdo.option.ConnectionUserName</name>
<name>javax.jdo.option.ConnectionPassword</name>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
[hadoop@hadoop102 hive]$ hive --service metastore
2022-01-06 22:25:05: Starting Hive Metastore Server
hive --service metastore命令为前台启动,启动后窗口不能再操作,
nohup hive --service metastore 2>&1 &
若其它机器只作为客户端,hive-site.xml 文件只需如下配置即可通过Metastore服务链接hive

使用JDBC通过Hiveserver2服务的方式访问Hive
Hiveserver2实际是Hive与Hive之间的服务端与客户端连接的方式
上面提到了作为客户端的机器比如hadoop103,当它作为hadoop104的客户端时,那么可以用Hiveserver2服务连接:
1 在hadoop103上启动Hiveserver2服务(如果配置了Metastore服务依旧也要启动)
注:HIve既是客户端又是服务端时,可以在同一个机器上启动服务端和客户端。
<name>hive.server2.thrift.bind.host</name>
<name>hive.server2.thrift.port</name>
[hadoop@hadoop102 conf]$ hive --service hiveserver2
后台启动hiveserver2服务:nohup hive --service hiveserver2 2>&1 &
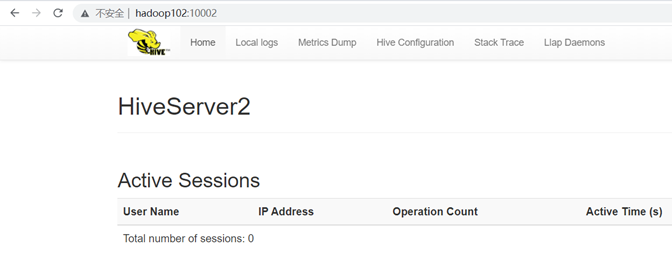
启动beeline客户端(需要多等待一会)
[hadoop@hadoop102 ~]$ beeline -u jdbc:hive2://hadoop102:10000 -n hadoop
看到如下信息说明通过beeline客户端访问hive成功
[hadoop@hadoop102 ~]$ beeline -u jdbc:hive2://hadoop102:10000 -n hadoop
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://hadoop102:10000> show tables;
- 遇到的问题
问题一:Beeline链接hive需要密码的情况:
[hadoop@hadoop102 ~]$ beeline
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: hadoop #hive服务端操作系统用户名
Enter password for jdbc:hive2://hadoop102:10000: ****** #hive服务端操作系统密码
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000>
问题二:在使用beeline链接hive时如果连接失败报错:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://192.168.194.48:10000: Failed to open new session: java.lang.RuntimeException: RemoteException(AuthorizationException): User: hadoop is not allowed to impersonate hadoop (state=08S01,code=0)
解决办法:通过httpfs协议访问rest接口,以hadoop用户包装自己的方式操作HDFS
首先需要开启rest接口,
在hdfs-site.xml文件中加入:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
然后在core-site.xml文件中加入:
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
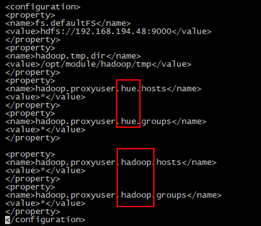
绿色的hadoop是beeline> ! connect jdbc:hive2://192.168.194.48:10000登录时的用户名
当用不同的用户通过rest接口访问hdfs时可以配置多个用户如下图中同时配置了hue和hadoop用户
编写启动metastore和hiveserver2脚本
前台启动的方式导致需要打开多个shell窗口,且终端断开链接后服务就停止运行,可以使用如下方式后台方式启动
nohup hive --service metastore 2>&1 &
nohup hive --service hiveserver2 2>&1 &
编写启动脚本可以更方便的管理
[hadoop@hadoop102 ~]$ cd /opt/module/hive/bin/
[hadoop@hadoop102 bin]$ vi hiveservices.sh
文件中加入如下内容
#!/bin/bash
HIVE_LOG_DIR=/opt/module/hive/logs
if
[
!
-d
$HIVE_LOG_DIR
]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo
$pid
[[
"$pid"
=~
"$ppid"
]]
&&
[
"$ppid"
]
&&
return
0
||
return
1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[
-z
"$metapid"
]
&&
eval
$cmd
||
echo
"Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[
-z
"$server2pid"
]
&&
eval
$cmd
||
echo
"HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[
"$metapid"
]
&&
kill
$metapid
||
echo
"Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[
"$server2pid"
]
&&
kill
$server2pid
||
echo
"HiveServer2服务未启动"
}
case
$1
in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep
2
hive_start
;;
"status")
check_process HiveMetastore 9083
>/dev/null &&
echo
"Metastore服务运行正常"
||
echo
"Metastore服务运行异常"
check_process HiveServer2 10000
>/dev/null &&
echo
"HiveServer2服务运行正常"
||
echo
"HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo
'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
添加执行权限
[hadoop@hadoop102 bin]$ chmod u+x hiveservices.sh
使用脚本
启动:hiveservices.sh start
停止:hiveservices.sh stop
重启:hiveservices.sh restart
查看状态: hiveservices.sh status
Hive常用交互命令
[hadoop@hadoop102 hive]$ bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the console)
"-e"不进入hive的交互窗口执行sql语句
bin/hive -e "select id from student;"
"-f"执行脚本中sql语句
在/opt/module/hive/下创建datas目录并在datas目录下创建hivef.sql文件
touch hivef.sql
文件中写入正确的sql语句
select *from student;
执行文件中的sql语句
bin/hive -f /opt/module/hive/datas/hivef.sql
执行文件中的sql语句并将结果写入文件中
bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/datas/hive_result.txt
Hive其他命令操作
退出hive窗口:
hive(default)>exit;
hive(default)>quit;
在hive cli命令窗口中如何查看hdfs文件系统
hive(default)>dfs -ls /;
查看在hive中输入的所有历史命令
进入到当前用户的根目录/root或/home/atguigu
查看. hivehistory文件
cat .hivehistory
在Hive中配置Tez引擎
Hive运行引擎Tez
Tez是一个Hive的运行引擎,性能优于MR。
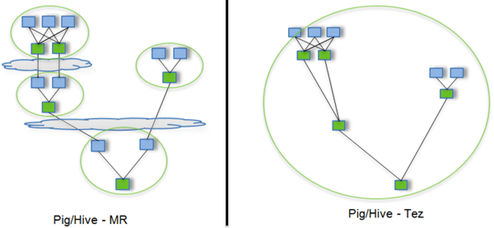
用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
安装准备
hadoop配置支持LZO压缩,参考文档《Hadoop详解(07-1) - Hdfs支持LZO压缩配置》
tez官网:https://tez.apache.org/
tez安装包下载地址:https://downloads.apache.org/tez/0.10.1/apache-tez-0.10.1-bin.tar.gz
上传解压
[hadoop@hadoop102 software]$ tar -zxvf apache-tez-0.10.1-bin.tar.gz -C /opt/module/
修改名称
[hadoop@hadoop102 software]$ cd /opt/module/
[hadoop@hadoop102 module]$ mv apache-tez-0.10.1-bin/ tez-0.10.1
在Hive中配置Tez
- 在hive-env.sh文件中添加tez环境变量配置和依赖包环境变量配置
[hadoop@hadoop102 module]$ cd /opt/module/hive/conf/
[hadoop@hadoop102 conf]$ vi hive-env.sh
在文件末尾添加如下配置
#tez的解压目录
export TEZ_HOME=/opt/module/tez-0.10.1
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
#导入lzo压缩jar包的环境变量
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar$TEZ_JARS
- 在hive-site.xml文件中添加如下配置,更改hive计算引擎
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
- 配置tez-site.xml
在/opt/module/hive/conf下面创建tez-site.xml文件
[hadoop@hadoop102 conf]$ vi tez-site.xml
在tez-site.xml添加如下内容
<?xml
version="1.0"
encoding="UTF-8"?>
<?xml-stylesheet
type="text/xsl"
href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1,${fs.defaultFS}/tez/tez-0.10.1/lib</value>
</property>
<property>
<name>tez.lib.uris.classpath</name>
<value>${fs.defaultFS}/tez/tez-0.10.1,${fs.defaultFS}/tez/tez-0.10.1/lib</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>
- 上传Tez目录到hdfs集群
1)将tez安装目录/opt/module/tez-0.9.1上传到HDFS的/tez路径
[hadoop@hadoop102 conf]$ hadoop fs -mkdir /tez
[hadoop@hadoop102 conf]$ hadoop fs -put /opt/module/tez-0.10.1/ /tez
[hadoop@hadoop102 conf]$ hadoop fs -ls /tez
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2022-01-14 01:40 /tez/tez-0.10.1
- 测试
启动Hive
启动hive过程不报错,如果报错说明tez引擎配置有问题
[hadoop@hadoop102 hive]$ bin/hive
hive (default)> create table student(
hive (default)> insert into student values(1,"zhangjk");
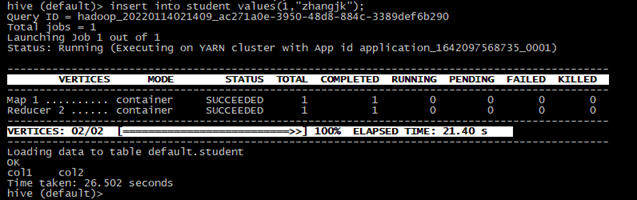
hive (default)> select * from student;
Time taken: 0.187 seconds, Fetched: 1 row(s)
创建输入数据是lzo输出是text,支持json解析的分区表
hive (default)> drop table if exists log;
CREATE EXTERNAL TABLE log (`line` string)
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/user/hive/warehouse/log';
[hadoop@hadoop102 module]$ vi 1.log
hadoop fs -put /opt/module/1.log /user
hive (gmall)> load data inpath '/user/1.log' into table log partition(dt='2022-01-01');
解决内存不足问题
如果在虚拟机上运行Tez时经常会出现内存不足道情况而被NodeManager杀死进程,如:
这种问题是从机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
<name>yarn.nodemanager.vmem-check-enabled</name>
方案二:mapred-site.xml中设置Map和Reduce任务的内存配置
value中实际配置的内存需要根据自己机器内存大小及应用情况进行修改
<name>mapreduce.map.memory.mb</name>
<name>mapreduce.map.java.opts</name>
<name>mapreduce.reduce.memory.mb</name>
<name>mapreduce.reduce.java.opts</name>
常见错误及解决方案
将$HADOOP_HOME/etc/hadoop/capacity-scheduler.xml文件中的
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
(2)修改user表中的主机名称没有都修改为%,而是修改为localhost
-
hive (default)> set hive.input.format;
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
可以采用HiveInputFormat就会根据分区数输出相应的文件。
hive (default)> set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
-
解决方案:在/var/lib/mysql 目录下创建: -rw-rw----. 1 mysql mysql 5 12月 22 16:41 hadoop102.pid 文件,并修改权限为 777。
- JVM堆内存溢出
描述:java.lang.OutOfMemoryError: Java heap space
<name>yarn.scheduler.maximum-allocation-mb</name>
<name>yarn.scheduler.minimum-allocation-mb</name>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<name>mapred.child.java.opts</name>
<name>yarn.nodemanager.vmem-check-enabled</name>
最新文章
- Solr部分更新MultiValued的Date日期字段时报错及解决方案
- Nginx快速入门菜鸟笔记
- asp.net、 mvc session影响并发
- enmo_day_05
- Android网络编程系列 一 TCP/IP协议族之链路层
- .NET概念:.NET程序编译和运行
- mac安装IE浏览器
- 1079. Total Sales of Supply Chain (25)
- 归档 NSKeyedArchiver
- cf B Three matrices
- JS函数的属性
- 大白菜U盘启动制作工具装机维护版V5.0–大白菜U盘下载中心
- java基础:数组的复制
- Java程序员的情书
- burp的dns记录功能
- 项目开发之package.json
- 洛谷 p1434 滑雪【记忆化搜索】
- 逆袭之旅DAY10.东软实训.
- python sockerserver tcp 文件下载 udp
- android openCL的so库目录(转)