Java基础之(一)——从synchronized优化看Java锁概念
一、悲观锁和乐观锁概念
悲观锁和乐观锁是一种广义的锁概念,Java中没有哪个Lock实现类就叫PessimisticLock或OptimisticLock,而是在数据并发情况下的两种不同处理策略。
针对同一个数据并发操作,悲观锁认为自己在使用数据时,一定有其它的线程操作数据,因此获取数据前先加锁确保数据使用过程中不会被其它线程修改;乐观锁则认为自己在使用数据的时候不会被其它线程修改。基于两者的不同点我们不难发现:
(1)悲观锁适用于写操作较多的场景。
(2)乐观锁适用于读操作较多的场景。
二、乐观锁的一种实现方案
乐观锁通常采用了无锁编程方法,基于CAS(Compare And Swap)算法实现,下面重点介绍一下该算法:
先看一个例子,假设有100个线程同时并发,且每个线程累加1000次,那么结果很容易算出时100,000,实现代码如下:
1 public class Test {
2 private static int sum = 0;
3
4 public static void main(String[] args) throws InterruptedException {
5 final CountDownLatch latch = new CountDownLatch(100);
6 for (int i = 0; i < 100; i++) {
7 new Thread(() -> {
8 for (int j = 0; j < 1000; j++) {
9 sum += 1;
10 }
11 latch.countDown();
12 }).start();
13 }
14 latch.await();
15 System.out.println(String.format("Sum=%s", sum));
16 }
17 }
很显然,由于资源(sum变量)同步的问题,上述代码运行结果跟我们预期不一样,而且每次结果也不一样。
那么sum变量增加volatile修饰符呢?结果还是有问题,这是因此为sum +=1不是原子语句,很显然我们需要把sum+=1这个语句加锁,那么每次执行结果都一样且跟预期(100,000)相符。
定义一个可重入锁
1 private static Lock lock = new ReentrantLock();
资源加锁
1 lock.lock();
2 sum += 1;
3 lock.unlock();
ReentrantLock是基于悲观锁实现方案,每次加锁、释放锁都涉及到用户态和内核态切换(保存、恢复线程上下文以及线程调度等),因此性能损失较大。那么乐观锁又是如何实现的呢?实现方法如下:
1 public class Test {
2 private static AtomicInteger sum = new AtomicInteger(0);
3
4 public static void main(String[] args) throws InterruptedException {
5 final CountDownLatch latch = new CountDownLatch(100);
6 for (int i = 0; i < 100; i++) {
7 new Thread(() -> {
8 for (int j = 0; j < 1000; j++) {
9 sum.addAndGet(1);
10 }
11 latch.countDown();
12 }).start();
13 }
14
15 latch.await();
16
17 System.out.println(String.format("Sum=%s", sum.get()));
18 }
19 }
上述这个例子会出现频繁写入,在实际工程中并不一定适合乐观锁,这里主要讲解一下乐观锁实现原理。
AtomicInteger是针对Integer类型的封装,除此之外还包括AtomicLong、AtomicReference等,下面重分析addAndGet这个方法。

addAndGet会调用unsafe.getAndAddInt,第一个参数是AtomaticInteger实例(sum对象);第三个参数是我们传入要累加的值;第二个参数valueOffset是AtomaticInteger中value属性(我们每次累加的结果就是保存在value中)的偏移地址,初始化代码如下:

getAndAddInt实现代码如下:

其中,var5 = this.getIntVolatile(var1, var2),var1是sum对象、var2是value的偏移量地址,getIntVolatile就是根据偏移量地址读取sum对象中存储的value值,即var5=value
compareAndSwapInt(var1, var2, var5, var5 + var4),var1是sum对象,var2是sum对象中value的偏移量地址,var5是之前读取的value值,var5+var4是本次操作期望写入的value新值。写入新值之前会判断最新的value值是否和之前获取的值(var5)相等,相等的话更新新值并返回true;否则直接返回false,不做任何操作。
当写入成功时就会跳出do-while循环,否则会一直重试,注意整个循环体是没有阻塞的,因此也避免了线程上下文切换。
compareAndSwapInt是Java的native方法,并不由Java语言实现,其底层依赖于CPU提供的指令集(比如x86的cmpxchg )保证其操作的原子性。
三、轻量级自旋锁
自旋锁是指当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程阻塞状态,自旋锁的好处是避免线程上下文切换,但是坏处也很明显,如果没有获取到锁时会不停的循环监测,这个循环监测过程就是自旋操作。
本节还是基于CAS操作实现一个简单的自旋锁,代码如下:
1 public class SimpleSpinLock {
2
3 private AtomicReference<Thread> atomicReference = new AtomicReference<>();
4
5 public void lock() {
6 Thread currentThread = Thread.currentThread();
7 //没有获取到锁时候,处于自旋过程而不是阻塞状态。
8 while (!atomicReference.compareAndSet(null, currentThread)) {
9 }
10 System.out.println(String.format("Lock success. atomic=%s", atomicReference.get().getName()));
11 }
12
13 public void unLock() {
14 Thread currentThread = Thread.currentThread();
15 if (atomicReference.compareAndSet(currentThread, null)) {
16 System.out.println(String.format("Unlock success. atomic=%s", currentThread.getName()));
17 } else {
18 System.out.println(String.format("Unlock failure. atomic=%s", currentThread.getName()));
19 }
20 }
21 }
22
23 public class Test {
24 private static int sum = 0;
25 private static SimpleSpinLock lock = new SimpleSpinLock();
26
27 public static void main(String[] args) throws InterruptedException {
28 final CountDownLatch latch = new CountDownLatch(100);
29 for (int i = 0; i < 100; i++) {
30 Thread thread = new Thread(() -> {
31 for (int j = 0; j < 1000; j++) {
32 lock.lock();
33 sum++;
34 lock.unLock();
35 }
36 latch.countDown();
37 });
38 thread.setName(String.format("CountThread-%s", i));
39 thread.start();
40 }
41
42 latch.await();
43
44 System.out.println(String.format("Sum=%d", sum));
45 }
46 }
上述SimpleSpinLock是一个最简的实现方案,假如某个线程一直申请不到锁,那么就会一直处于空转自旋状态,这个使用我们通常会设置一个自旋次数,超过这个次数(比如10次)时膨胀成重量级的互斥锁,减少CPU空转消耗。
那么本节的最后一个问题,在实际工程使用中如何定义自旋次数?
JDK1.6引入了自适应自旋锁,所谓自适应自旋锁,就意味着自旋的次数不再是固定的,具体规则如下:
自旋次数通常由前一次在同一个锁上的自旋时间及锁的拥有者的状态决定。比如线程T1自旋10次成功,那么等到下一个线程T2自旋时,也会默认认为T2自旋10次。
如果T2自旋了5次就成功了,那么此时这个自旋次数就会缩减到5次。
四、偏向锁
偏向锁是JDK 1.6提出的一种锁优化方式。其核心思想是如果资源没有竞争,就取消之前已经取得锁得线程同步操作。具体实现方案如下:
- 某一线程第一次获取锁时便进入偏向模式,当该线程再次请求这个锁时,无需再进行相关得同步操作(不需要CAS计算)。
- 如果在此期间有其它线程进行了锁请求,则锁退出偏向模式。
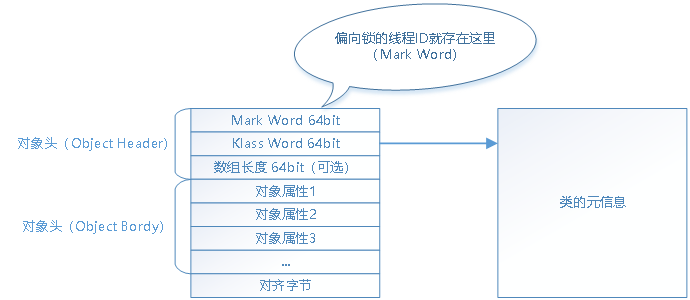
- 当锁处于偏向模式时,虚拟机中的Mark Word会记录获得锁得线程ID。
最后我们看一下Mark Word在哪里:
五、再谈synchronized
看完偏向锁实现方案,你是否和我一样有这样的疑问?没有资源竞争情况偏向锁才有用,一旦有有竞争偏向锁就失效了,那么在没有资源竞争的情况下,我为什么要加锁呢?好吧,本节的最后我将回答这个问题。
synchronized在JDK 1.5的早期版本中使用重量级锁(通过Monitor关联到操作系统的互斥锁),效率很低,因此JDK 1.6做了大幅度优化,整个资源同步过程支持锁升级(无锁、偏向锁、轻量级锁、重量级锁),且升级后不能降级。这一升级过程都伴随着Mark Word存储内容的改变,Mark Word会根据对象的不同状态存放不同的数据,数据格式如下:
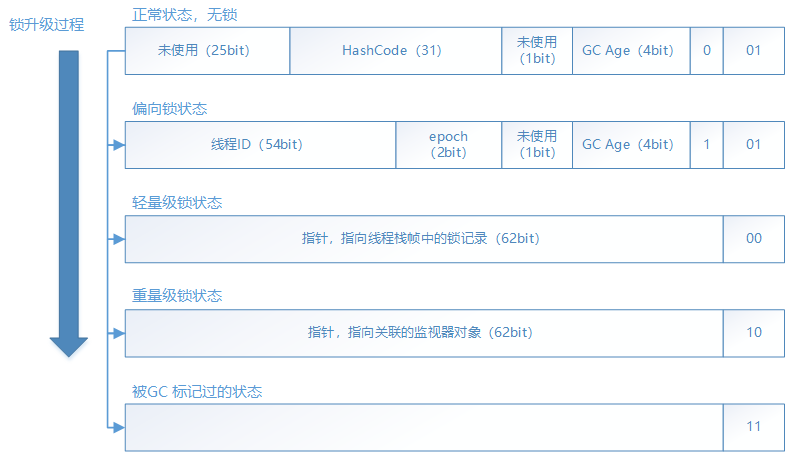
好吧,到这里我们来回答一下开头的那个疑惑,早期的Java版本提供了Vector、HashTable、StringBuffer 等这些线程安全的集合,其内部实现依赖于synchronized实现重量级锁,因此效率低下,但是开发人员使用这些集合时大部分都是在单线程环境下,并不会出现资源竞争的场景,因此在后续优化synchornized时,顺便增加了这个偏向锁在保证可能出现并发的情况下提高的Vector、HashTable执行效率。然而今天我们在写Java代码时,任何一本编码规范都有要求我们优先考虑ArrayList、HashMap、StringBuilder这些非线程安全的集合,那么我们还需要偏向锁吗?O(∩_∩)O
最新文章
- python模块:base64
- Adobe Flash Builder 4.7破解方法(绝对可用)
- JDK 对应的设计模式
- .NET MVC HtmlHepler
- Gitlab的Gravatar头像无法显示的问题
- Natural language style method declaration and usages in programming languages
- sql临时表和表变量
- Unity3D 优化相关
- 获取地理位置的html5代码
- pylinter could not automatically determined the path to `lint.py`
- qtp不识别树结构中的点击事件
- Mac上安装boost开放环境
- Asp.Net--下载文件
- Swift - 初始化方法返回nil表示初始化失败
- 怎样给Win7系统设置一个默认的浏览器
- 对比 Git 与 SVN,这篇讲的很易懂
- PHP全栈学习笔记6
- C# yield return 和 yield break
- Kong(v1.0.2)代理参考
- mybatis的typeHandler