NVIDIA GPU Volta架构简述
NVIDIA GPU Volta架构简述
本文摘抄自英伟达Volta架构官方白皮书:https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/sc18-tesla-democratization-tech-overview-r4-web.pdf
SM
- Volta架构目前仅GV100支持
Volta architecture comprises a single variant: GV100.
- Volta的每个SM包含4个线程束调度器。每个调度单元处理一个线程束组,并有一组专用的算术指令单元。
Each Turing SM includes 4 warp-scheduler units.Each scheduler handles a static set of warps and issues to a dedicated set of arithmetic instruction units.
- 指令在两个周期内执行,调度器可以在每个周期发出独立的指令。而核心数学运算相关指令如FMA需要4个周期的延迟,相比之下,Pascal需要六个周期。
Instructions are performed over two cycles, and the schedulers can issue independent instructions every cycle. Dependent instruction issue latency for core FMA math operations is four clock cycles, like Volta, compared to six cycles on Pascal.
- Volta提供了64个fp32核心,32个fp64核心,64个int32核心和8个混合精度Tensor Cores。V100最多提供了84个SM。不同于Pascal,Volta包含了专用的fp32和int32核心,这意味着Volta支持同时执行fp32和int32运算。
Similar to GP100, the GV100 SM provides 64 FP32 cores and 32 FP64 cores. The GV100 SM additionally includes 64 INT32 cores and 8 mixed-precision Tensor Cores. GV100 provides up to 84 SMs. Unlike Pascal GPUs, the GV100 SM includes dedicated FP32 and INT32 cores. This enables simultaneous execution of FP32 and INT32 operations.
- Volta对线程束中的每个线程提供了独立线程调用,现在可以支持支持线程束内部的线程同步__syncwarp()。
The Volta architecture introduces Independent Thread Scheduling among threads in a warp. This feature enables intra-warp synchronization patterns previously unavailable and simplifies code changes when porting CPU code.
- Turing架构上编程需要注意如下几点
- 使用带_sync后缀的线程束指令 (__shfl*, __any, __all, and __ballot) 代替原有的
To avoid data corruption, applications using warp intrinsics (__shfl*, __any, __all, and __ballot) should transition to the new, safe, synchronizing counterparts, with the *_sync suffix.
- 在需要线程束同步的位置插入__syncwarp()指令
Applications that assume reads and writes are implicitly visible to other threads in the same warp need to insert the new __syncwarp() warp-wide barrier synchronization instruction between steps where data is exchanged between threads via global or shared memory.
- 使用__syncthreads()指令时需要确保线程块中的所有线程必须都能达到此位置
Applications using __syncthreads() or the PTX bar.sync (and their derivatives) in such a way that a barrier will not be reached by some non-exited thread in the thread block must be modified to ensure that all non-exited threads reach the barrier.
- 与Pascal 架构相同,Volta支持最多64个线程束并行执行。
The maximum number of concurrent warps per SM remains the same as in Pascal (i.e., 64)
8.与Pascal 架构相同,Turing架构每SM拥有64k个32-bit寄存器,每个线程最多可使用255个寄存器,每SM支持最多32个线程块驻留,每SM的共享内存大小为96KB。
The register file size is 64k 32-bit registers per SM.
The maximum registers per thread is 255.
The maximum number of thread blocks per SM is 32.
Shared memory capacity per SM is 96KB, similar to GP104, and a 50% increase compared to GP100.
Tensor Cores
- 每个Tensor Core执行矩阵乘加操作:D = AxB + C,其中矩阵ABCD都是4x4大写,矩阵AB为fp16浮点数,矩阵CD可fp16或fp32。
Each Tensor Core performs the following operation: D = AxB + C, where A, B, C, and D are 4x4 matrices. The matrix multiply inputs A and B are FP16 matrices, while the accumulation matrices C and D may be FP16 or FP32 matrices.
- 在CUDA层面,线程束接口假设16x16矩阵分配到了线程束中32个线程。
At the CUDA level, the warp-level interface assumes 16x16 size matrices spanning all 32 threads of the warp.
- GV100的每个HBM2堆栈和4堆栈最多使用8个存储芯片,最大支持32GB的GPU内存,其中HBM2理论内存带宽高达900GB/s。
GV100 uses up to eight memory dies per HBM2 stack and four stacks, with a maximum of 32 GB of GPU memory.A faster and more efficient HBM2 implementation delivers up to 900 GB/s of peak memory bandwidth, compared to 732 GB/s for GP100.
- Volta架构中,L1缓存、纹理缓存、共享内存共享128KB缓存,Volta支持配置每SM 0、8、16、32、64、96 KB共享内存。
In Volta the L1 cache, texture cache, and shared memory are backed by a combined 128 KB data cache.Volta supports shared memory capacities of 0, 8, 16, 32, 64, or 96 KB per SM.
- Volta允许一个线程块使用全部的96KB的共享内存,当静态分配限制最多48KB,超过48KB则需要动态分配。
Volta enables a single thread block to address the full 96 KB of shared memory. To maintain architectural compatibility, static shared memory allocations remain limited to 48 KB, and an explicit opt-in is also required to enable dynamic allocations above this limit.
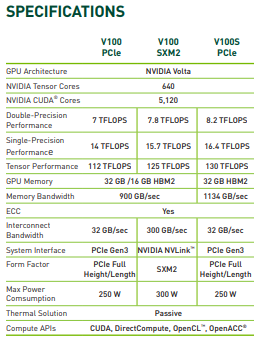
附1:Volta架构机型V100配置数据
最新文章
- 《开源大数据分析引擎Impala实战》目录
- Java开发之JSP指令
- ACM: FZU 2148 Moon Game - 海伦公式
- bzoj1029 [JSOI2007]建筑抢修
- 反编译android应用,降低权限去广告及重新签名
- Spring中bean的scope
- uva 11324 The Largest Clique (Tarjan+记忆化)
- DLL模块:C++在VS下创建、调用dll
- Android学习总结——Popup menu:弹出式菜单
- MonkeyDevcie API 实践全记录
- 【转载】DHCP流程
- 关于Random(47)与randon.nextInt(100)的区别
- 微信小程序之跳转、请求、带参数请求小例子
- git 下载部分目录
- 一套简单的git版本控制代码
- sqlserver日志文件
- Matlab_audiowrite_音频生成
- 解决tomcat启动慢问题
- laravel 在linux环境下解决.htaccess无效和去除index.php
- docker 构建带健康检查的redis镜像