莫烦python教程学习笔记——总结篇
一、机器学习算法分类:
监督学习:提供数据和数据分类标签。——分类、回归
非监督学习:只提供数据,不提供标签。
半监督学习
强化学习:尝试各种手段,自己去适应环境和规则。总结经验利用反馈,不断提高算法质量
遗传算法:淘汰弱者,留下强者,进行繁衍和变异穿产生更好的算法。
二、选择机器学习算法和数据集
sklearn中有很多真实的数据集可以引入,也可以根据自己的需求自动生成多种数据集。对于数据集可以对其进行归一化处理。
sklearn中的有着多种多样的算法,每一种算法都有其适用的场合、不同的属性和功能,按需选择。
三、评价机器学习算法:
1、算法效果不好:在训练过程中,可能因为数据集问题,学习效率,参数问题可能导致算法效果不好。
2、评价学习算法:将数据集分为训练集和测试集,根据算法在测试集上的表现评价算法,随着训练时间变长,网络层数变多,误差变小,精确度变高,但是变化的速度都是减缓的。
不同的模型有着是个自己的不同的评分方法:
R2-score:衡量回归问题的精度。最大精度也是100%
F1-score:用于测量不均衡数据的精度。
3、交叉验证用于调参(手动写循环):用于算法的调参(不同的参数也就是不同的模型)。
用交叉验证的方法进行调参或者模型选择时不需要手动划分用于k折验证的数据集,只需要将X和Y,还有k作为参数传进去即可:
#for regreesion
losss=-cross_val_score(knn,X,y,cv=10,scoring=’mean_squared_error’)
#for classification
scores=cross_val_score(knn,X,y,cv=10,scoring=’accuracy’)
交叉验证时,对于模型的评分,分类时用精确度accuracy来衡量模型表现,回归时用损失值mean_squard_error来衡量模型表现。
losss和 scores是两个数组,数组的长度为交叉验证的分割份数。
可使用scores.mean()来得到交叉验证的平均分数。
改变Knn中的参数值,根据交叉验证的得分高低来选择合适的模型参数。
4、learn_curve曲线用于过拟合问题:横轴数据量,纵轴模型得分
过拟合:对于样本的过度学习,过分关注样本的细节。
解决过拟合:L1/L2 regularization,dropout(留出法)
为了找出欠拟合和过拟合的节点我们可以绘制learn_curve曲线,这是一个根据数据量不同显示算法性能的图。显示了过拟合问题的两种误差:蓝色是traindata的算法表现,红色是testdata的算法表现。因为模型是基于traindata进行训练的,所以其在traindata上的表现更好一些。

train_sizes,train_loss,test_loss=learning_curve(
SVC(gramma=0.001),
X,
y,
Cv=10.
Scoring=’mean_squard_error’,
Train_sizes=[0.1,0.25,0.5,0.75,1])
Train_loss_mean=-np.mean(train_loss,axis=1) #10次交叉验证结果取平均
Test_loss_mean=-np.mean(test_loss,axis=1)
train_loss,test_loss是二维数组,长度为5,即为Train_sizes的步数
train_loss[0]是一个数组,存放0.1数据量时10个交叉验证的结果。
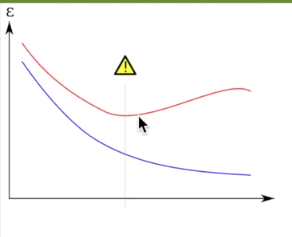
如上图所示,黄色警告处即为欠拟合和过拟合的分界点处。
5、使用交叉验证validation_curve自动调参:横坐标是模型参数,纵坐标是模型交叉验证得分
param_range = np.logspace(-6, -2.3, 5)
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10,
scoring='mean_squared_error')
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
train_loss,test_loss是二维数组,长度为参数的取值个数
train_loss[0]是一个数组,存放参数为某一个值时10个交叉验证的结果。
以模型参数为横坐标,以模型交叉验证得分为纵坐标绘图,最低点即为最佳参数。
最新文章
- phpexcel导入数据提示失败
- .net core
- c#隐藏和重写基类方法的异同
- jQuery.buildFragment源码分析以及在构造jQuery对象的作用
- NodeJs和ReactJs单元测试工具——Jest
- 如何用Jquery实现 ,比如点击图片之后 ,该图片变成向下的箭头,再点击向下箭头的图片 又变成原始图片呢
- UI设计师零基础入门到精通精品视频教程【155课高清完整版】
- Oracle 排序分析函数之ROW_NUMBER、RANK和DENSE_RANK
- [转载]启用 VIM 中的 Python 自动补全及提示功能
- 阿里云主机试用之自建站点和ftp上传所遇的2个问题
- eclipse中搜狗输入法中文状态下输出的全是英文
- java基础之二分法查找
- /usr/lib/x86_64-linux-gnu/libopencv_highgui.so:对‘TIFFReadRGBAStrip@LIBTIFF_4.0’未定义的引用
- 解决Invalid character found in the request target. The valid characters are defined in RFC 7230 and RFC 问题
- BZOJ3772 精神污染 主席树 dfs序
- 块级元素或者行内元素在设置float属性之后是否改变元素的性质?
- LightCapture for Mac(流程化截图工具)破解版安装
- iOS - Xcode项目统计总代码行数
- MapReduce中的partitioner
- [游记] Noip 2018