[斯坦福大学2014机器学习教程笔记]第六章-代价函数(Cost function)
2024-08-29 22:28:11
在这节中主要讲的是如何更好地拟合逻辑回归模型的参数θ.具体来说,要定义用来拟合参数的优化目标或者叫代价函数,这便是监督学习问题中的逻辑回归模型的拟合问题。
我们有一个训练集,训练集中有m个训练样本:{(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))},像之前一样,每个样本用n+1维特征向量表示,如下:

和以前一样x0=1,第0个特征一直是1.而且因为这是一个分类问题的训练集,所以所有的标签y不是0就是1.假设函数如下所示,它的参数是θ.
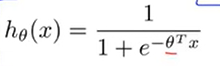
下面要讲的问题是,对于这个函数如何选定合适的参数θ.
回归一下之前讲线性回归模型的时候,使用了如下的代价函数。
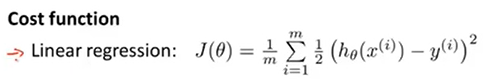
下面将对这个函数换一种写法:
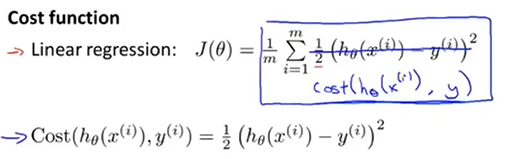
那么此时代价函数等于1/m * 这个Cost项在训练集范围上的求和。可以除去上标来对该公式简化。它是在输出的预测值是h(x),但实际值是y的时候我们的学习算法付出的代价。去掉上标之后,这个代价值就是 1/2 * 预测值与实际值差的平方。这个代价函数在线性回归里面是十分好用的,但是我们现在要用在逻辑回归里。如果我们要最小化代价函数J,它也能工作。但是如果我们这样做的话它就会变成参数θ的非凸函数。
当我们把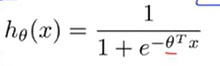 代入J(θ)中,因为hθ(x)是一个很复杂的非线性函数,我们很有可能得到的函数图像如下,它有很多局部最优值。
代入J(θ)中,因为hθ(x)是一个很复杂的非线性函数,我们很有可能得到的函数图像如下,它有很多局部最优值。
代入J(θ)中,因为hθ(x)是一个很复杂的非线性函数,我们很有可能得到的函数图像如下,它有很多局部最优值。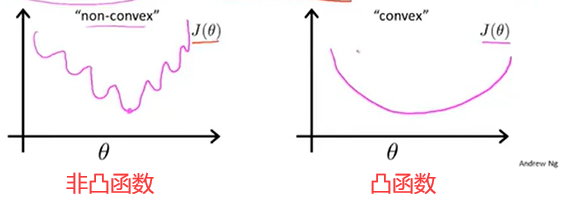
如果我们对非凸函数用梯度下降法,并不能保证可以收敛到全局最小值。我们更希望得到的是一个凸函数,这样对它使用梯度下降法的话就可以收敛到该函数的全局最小值。所以,我们重新定义这个算法要付出的代价。
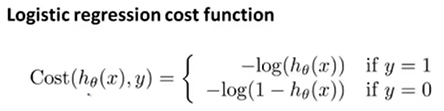
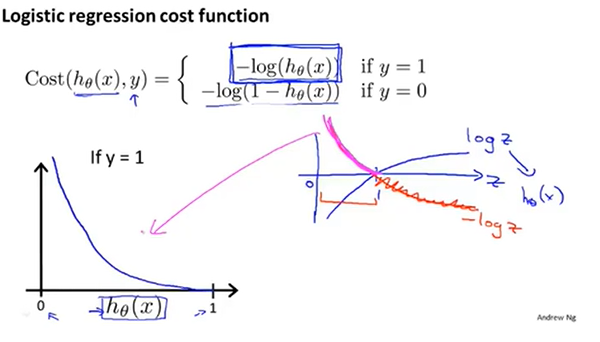
这看起来是一个很复杂的函数,我们画出这个函数。图像如下:
这个函数的性质有:
如果y=1而且hθ(x)=1,那么代价值就为0.但是如果y=1但是预测值hθ(x)=0的时候,此时代价值趋于∞.
上面为y=1的情况。下面来看y=0的情况。
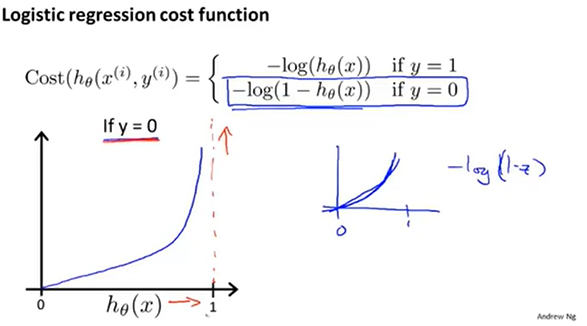
当实际值y=0时,预测值hθ(x)=0的情况下付出的代价值就为0,预测值hθ(x)=1的情况下付出的代价值趋于∞.以上讲的主要是单训练样本的代价函数。下面将将其推广得到整个训练样本的代价函数,接着对其运用梯度下降法。
python代码:
1 import numpy as np
2 def cost(theta, X, y):
3 theta = np.matrix(theta)
4 X = np.matrix(X)
5 y = np.matrix(y)
6 first = np.multiply(-y, np.log(sigmoid(X* theta.T)))
7 second = np.multiply((1 - y), np.log(1 - sigmoid(X* theta.T)))
8 return np.sum(first - second) / (len(X))
最新文章
- Gulp基础
- Mysql 主从热备份
- animated js动画示例
- reset代码
- Java-练习方法之冒泡排序
- c++ 常数后缀说明
- Javascript模块化编程(二):AMD规范 作者: 阮一峰
- MQ的通讯模式
- Oracle数据库程序包全局变量的应用
- test_wifi
- 利用jQuery接受和处理xml数据
- 配置mac自带的Apache服务器
- HTML5 CSS3专题 纯CSS打造相册效果
- Contest2162 - 2019-3-28 高一noip基础知识点 测试5 题解版
- [HEOI2014]平衡(整数划分数)
- python网络编程(十一)
- String 源码探究
- Windows环境——MySQL安装及配置
- The Little Prince-12/04
- [蓝桥杯]ALGO-15.算法训练_旅行家的预算