Python+Requests+异步线程池爬取视频到本地
2024-10-19 23:41:06
1、本次项目为获取梨视频中的视频,再使用异步线程池下载视频到本地
2、获取视频时,其地址中的Url是会动态变化,不播放时src值为图片的地址,播放时src值为mp4格式
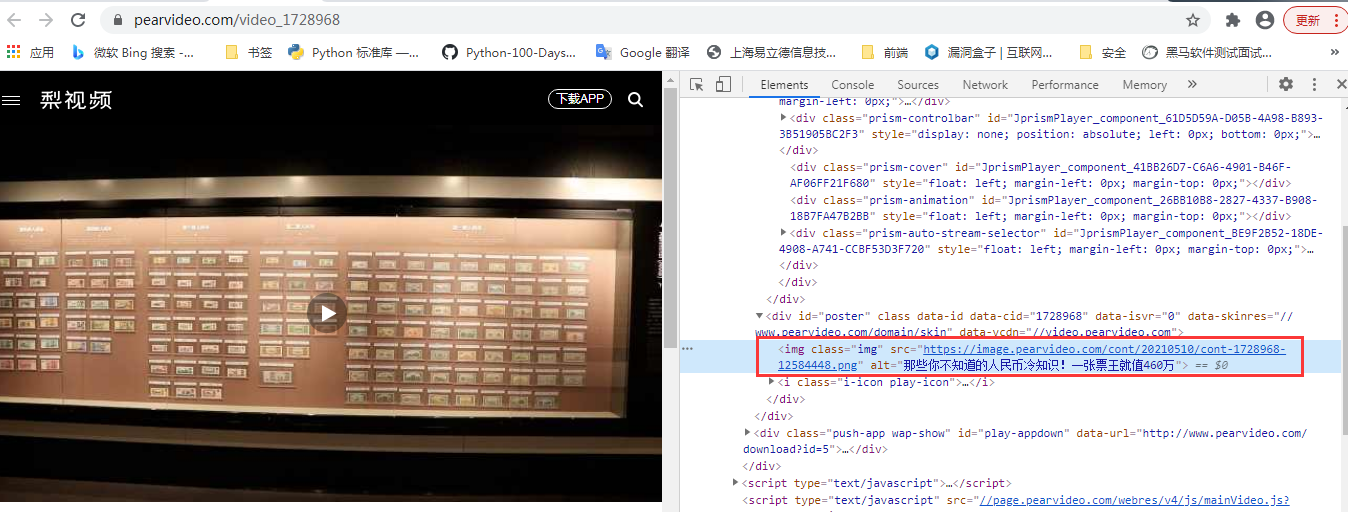

3、查看视频链接是否存在ajax,果然是存在的,但是返回的Url与真实的MP4地址存在部分不一致,此时需要使用字符串替换
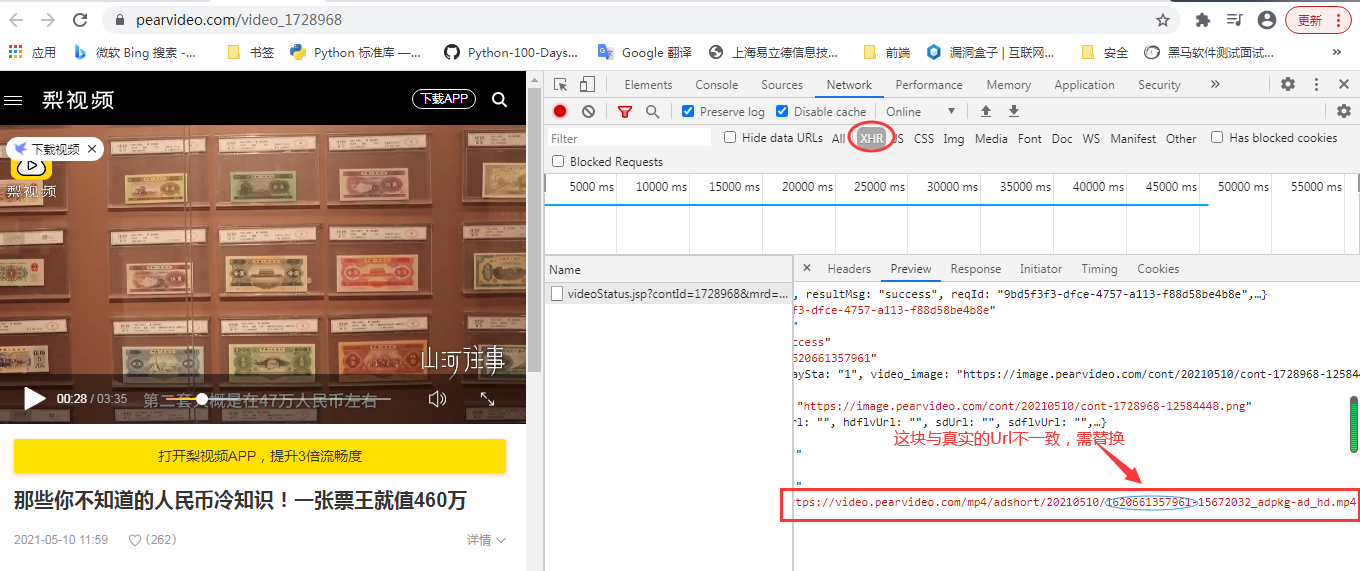
4、获取到真实的mp4视频地址后,再使用二进制流的方式进行下载到本地
5、使用Pool(4),四个线程池进行异步下载,互不干扰
6、源码如下:
import os
import requests
from lxml import etree
import random
import re
#安装fake-useragent库:pip install fake-useragent
from fake_useragent import UserAgent
#导入线程池模块
from multiprocessing.dummy import Pool
# 新建文件存储视频
if not os.path.exists('./threadFile'):
os.makedirs('./threadFile')
session = requests.Session()
# 存储所有视频的Url及标题
video_urls = []
# 梨视频Url
url = 'https://www.pearvideo.com/'
UA = UserAgent().random
headers = {
'User-Agent':UA
}
# 获取首页页面数据
page_text = session.get(url=url,headers=headers).text
#对获取的首页页面数据中的相关视频详情链接进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="vervideoTlist"]/div/ul/li')
for li in li_list:
# 视频详情页的Url
detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
# 视频详情页的Title
detail_title = li.xpath('./div/a/div[2]/div[2]/text()')[0]+'.mp4'
page_text = session.get(url=detail_url,headers=headers).text
# 字符串切割为value值
value = str("".join(li.xpath('./div/a/@href')[0]).split('_')[-1])
# 由于存在ajax则使用新的请求地址
headers_new = {
'User-Agent': UA,
'Referer': 'https://www.pearvideo.com/video_{}'.format(value)
}
detail_url_new = "https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}".format(value,float(random.random()))
detail_text = session.get(url=detail_url_new,headers=headers_new)
url = detail_text.json()['videoInfo']['videos']['srcUrl']
ER = '//(.*?)-'
list_url= re.findall(ER,url)
for url1 in list_url:
if url1.split('/')[-1] in url:
url = url.replace(url1.split('/')[-1],'cont-{}'.format(value))
else:
print('替换失败')
dic = {
"url":url,
"title":detail_title
}
video_urls.append(dic)
# 对视频链接发起请求获取视频的二进制数据,然后将视频数据返回
def get_video(dic):
print(dic['title'],'正在下载....')
page_content = session.get(url=dic['url'],headers=headers).content
fileName = './threadFile/'+dic['title']
# 持久化存储数据
with open(fileName,'wb') as fp:
fp.write(page_content)
print(dic['title'], '下载完成!!!')
#实例化线程池对象
# 使用线程池对视频数据进行请求(较为耗时阻塞的操作)
pool = Pool(4)
pool.map(get_video,video_urls)
# 关闭线程池
pool.close()
pool.join()
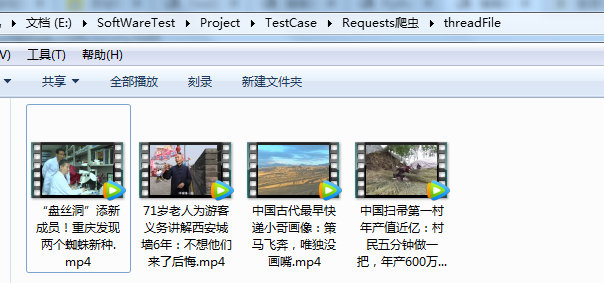
7、下载本地
最新文章
- Android自定义spinner下拉框实现的实现
- selenium对Alert弹框的多种处理
- DedeCMS织梦动态分页类,datalist标签使用实例
- CF Soldier and Badges (贪心)
- dedecms 处理分页样式及去掉分页li
- 谈谈C语言的数据类型
- 数据库 MySQL Jdbc JDBC的六个固定步骤
- linux 上不去网
- DESTOON系统文章模块默认设置第一张图片为标题图的方法
- Windows文件监视器 1.0 绿色版
- perl模块安装
- DHCP服务器 出现的故障
- 【转】从PowerDesigner概念设计模型(CDM)中的3种实体关系说起
- 初始redis数据库
- hihocoder图像算子(高斯消元)
- Linux编程 5 (目录重命名与移动mv,删除文件rm,目录创建mkdir删除rmdir,查看file,cat,more,tail,head)
- BZOJ.2879.[NOI2012]美食节(费用流SPFA)
- requery.js使用姿势
- HDU 1251 统计难题(字典树 裸题 链表做法)
- python 模块导入全局变量