爬取QQ音乐(讲解爬虫思路)
一、问题描述:
本次爬取的对象是QQmusic,为自己后面做django音乐网站的开发获取一些资源。
二、问题分析:
由于QQmusic和网易音乐的方式差不多,都是讲歌曲信息放入到播放界面播放,在其他界面没有media的资源,喜马拉雅的则不是这样的,可以参考我爬取喜马拉雅的blog与代码:https://www.cnblogs.com/future-dream/p/10347354.html。
1.由于上述原因,我们需要对网页进行分析:
获取歌曲菜单的id——>歌曲的所有id信息——>播放网站URL的构建,我们所有的一切都是为播放网站参数需要而努力,得到了对应的参数剩下的就很简单。
(1)歌曲菜单界面
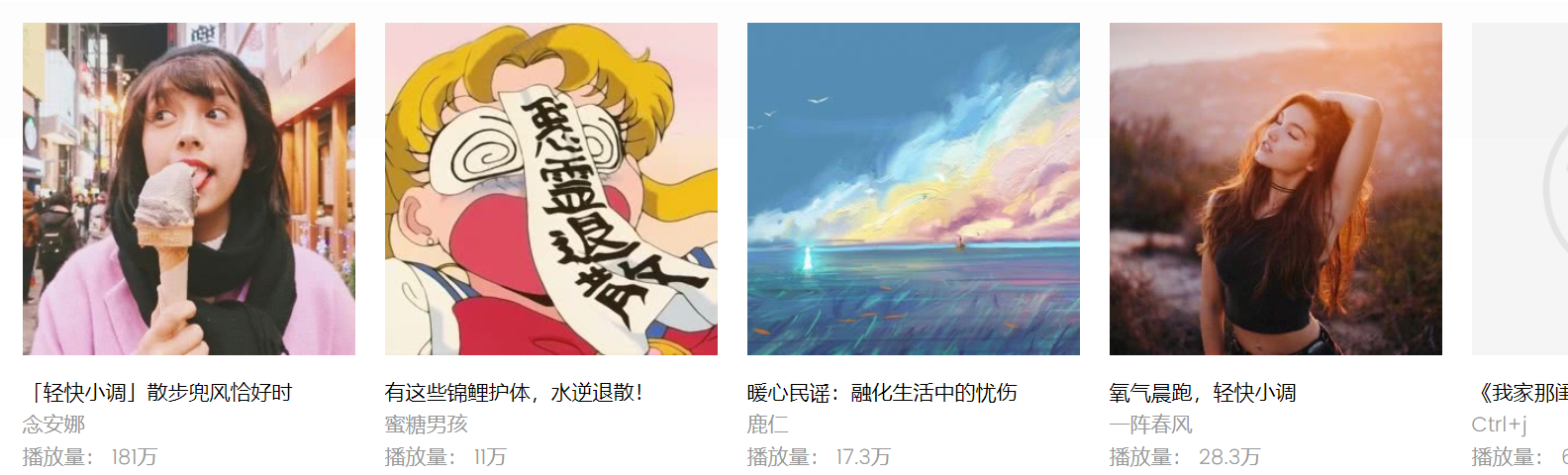
(2)歌曲id信息
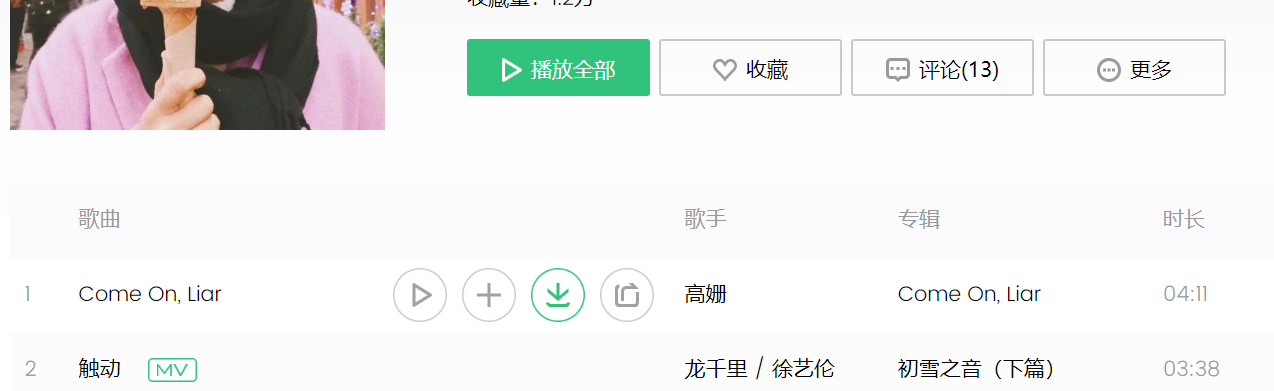
(3)播放网站的解析

三、实施步骤:
爬虫基本的思路都是倒序根据需要的信息一步一步往上推
1.播放界面的请求参数
(1)一个播放界面

(2)另一个播放界面

通过观察我们可以看到,只有vkey参数不一样,而我们的目的也是得到这个vkey参数,这样可以完成对歌曲内容的获取。
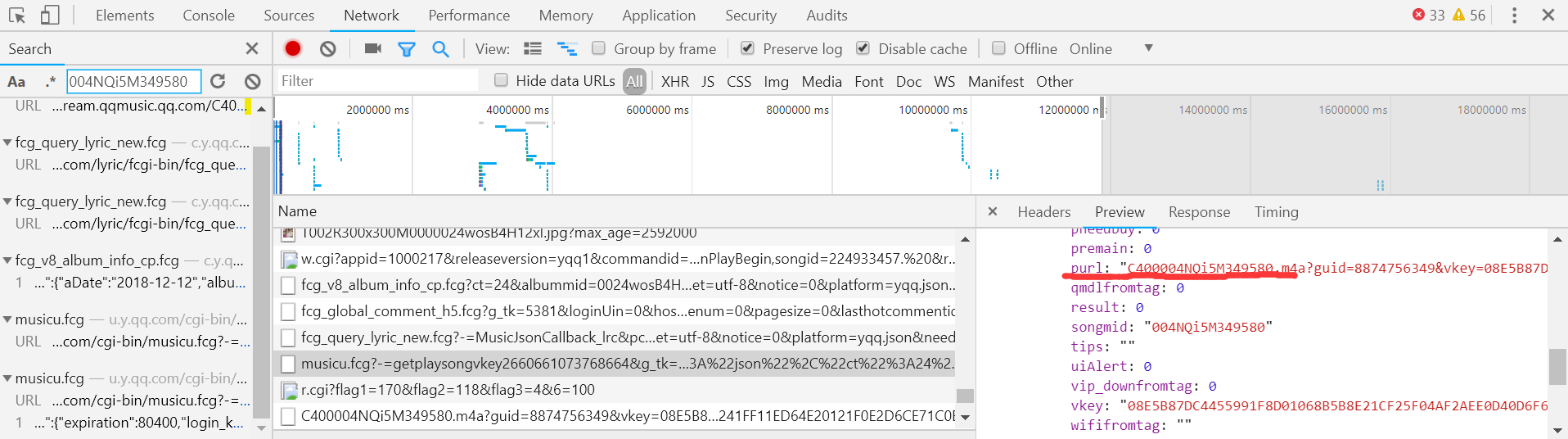
2.查看vkey所在的文件
(1)由于我们是在播放界面点出来的因此需要回到播放界面去查找信息,可以通过对id进行查询,可以看到如图灰色的响应,包含了所有关于歌曲信息的url信息。
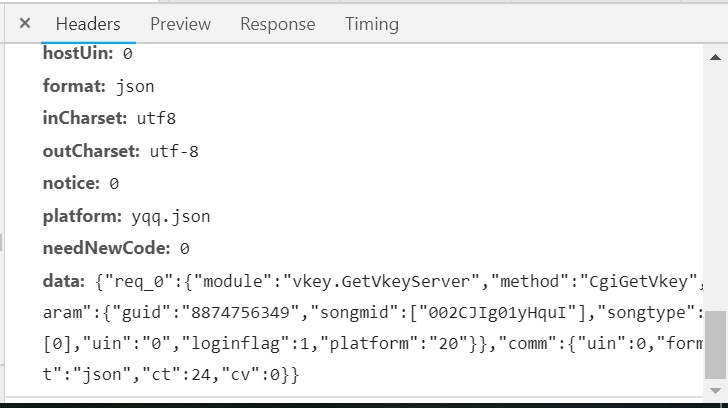
(2)查看参数可以知道我们需要的参数,注意:第一个参数是可有可无的,因此就省去这个参数。
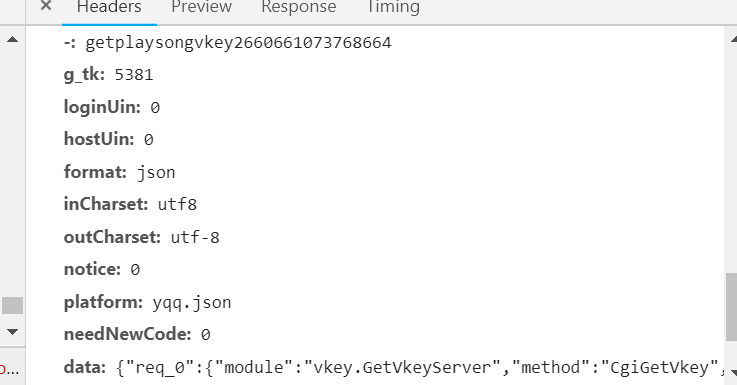
(3)对比参数,查看变量参数,可以看到只有songmid不一样因此在解析的时候只需要songmid需要改变。

3.获取songmid
(1)我们根据响应可以知道我们是通过歌单的信息获取歌曲的列表,在通过歌曲的列表获取歌曲的songmid。
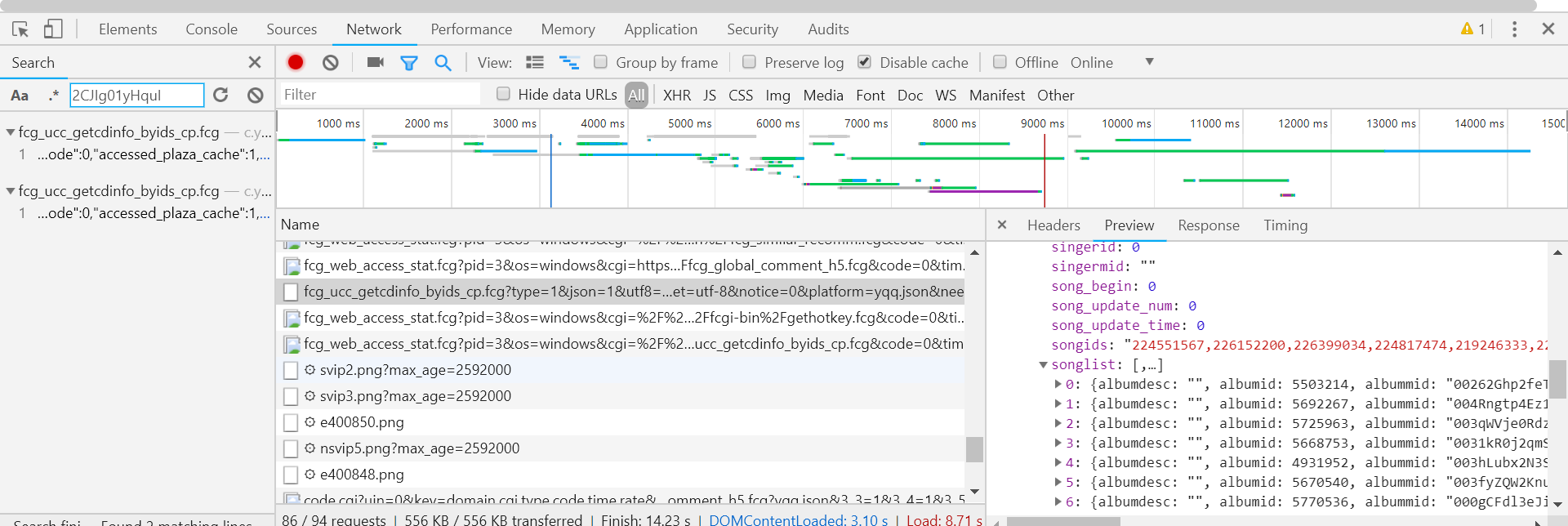
(2)通过获取的song_list获取到songmid

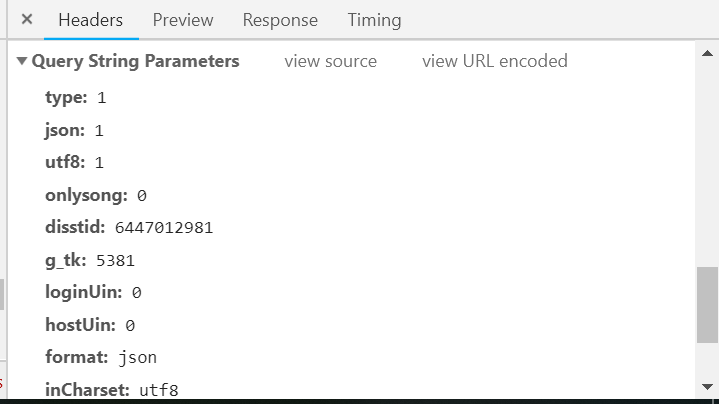
(3)查看请求头的信息,观察变化的参数
1.一个请求头的信息
2.另一个请求头的信息
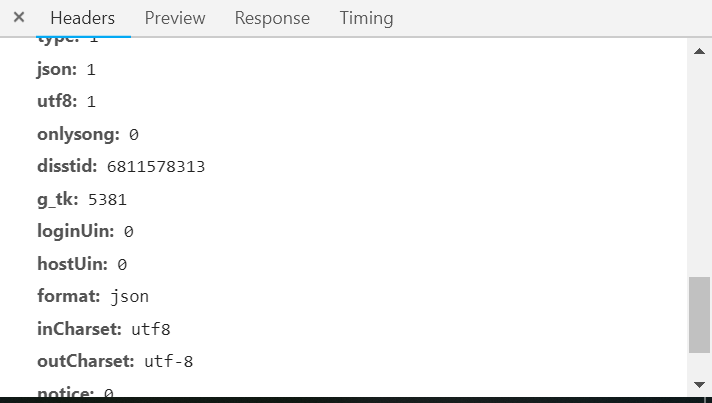
通过请求头都分析我们只需要改变disstid的参数就可以获取到所有的歌曲信息。
4.获取disstid的信息
(1)首先查看disstid在那个文件中
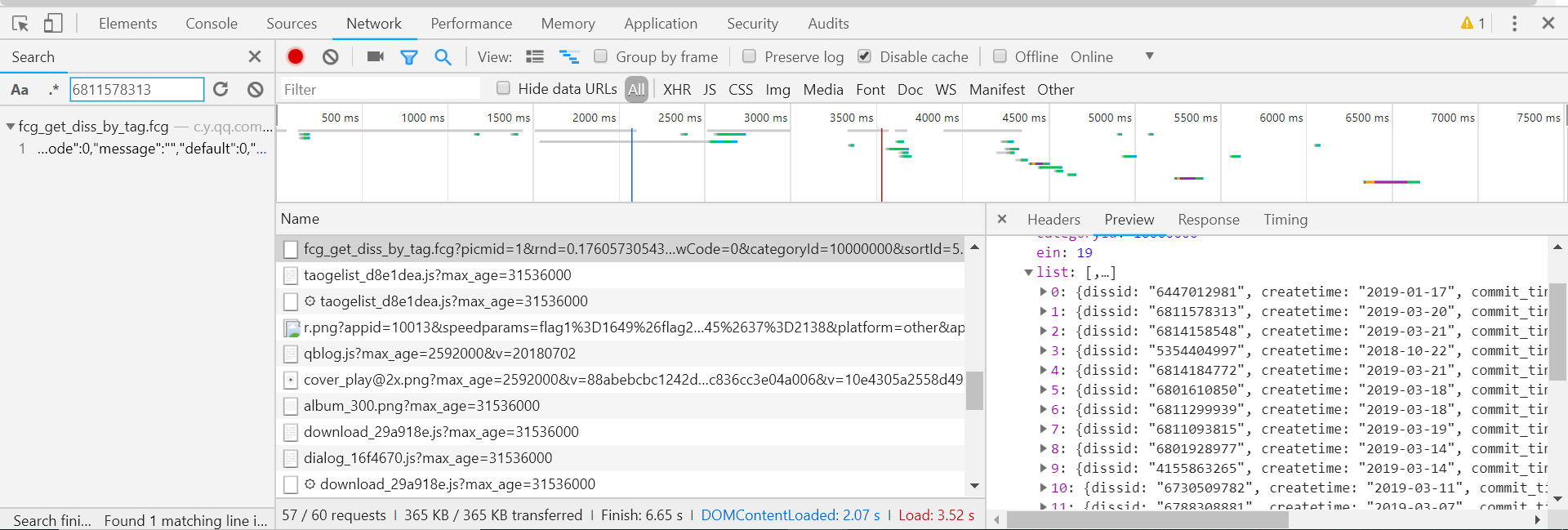
(2)查看请求头,其中rnd的信息可以不要为空就可以了。
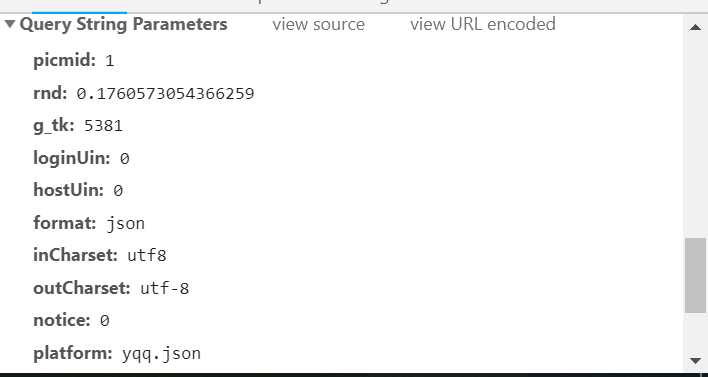
(3)获取disstid
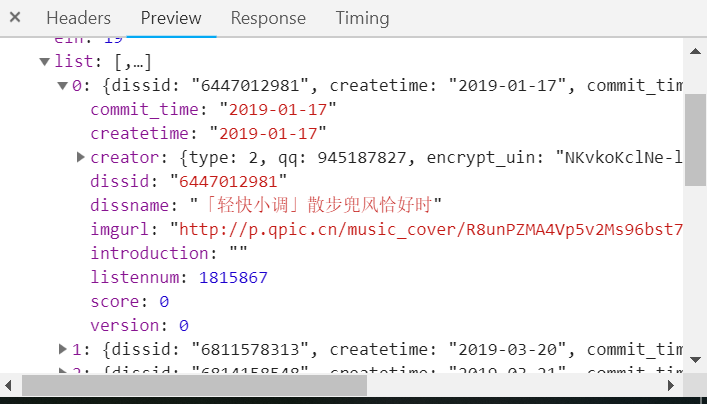
通过倒推的方法,可以成功解析歌曲的信息,剩下的就是代码实现。
四、成果展示与总结:
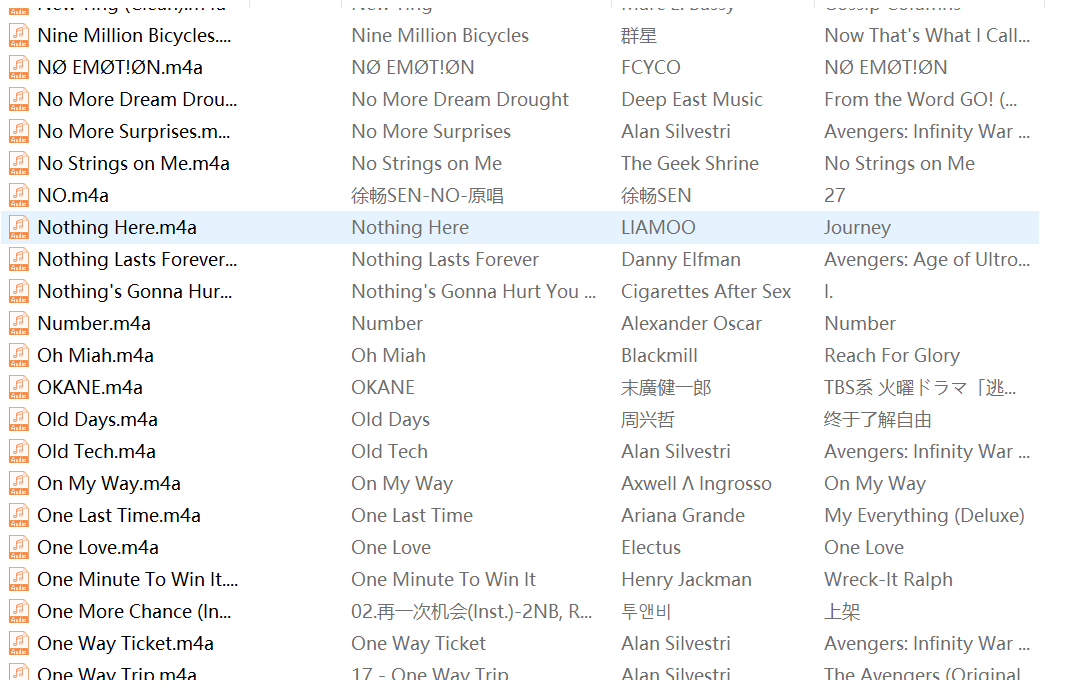
1.展示
2.总结
一步步分析,在解析vkey的时候第一个很奇怪的参数就可以省略,在进行爬虫爬取的时候也要注意这些问题,有时候的参数是可以省略的,因此在构造请求信息的时候就可以省略
参数的信息,由于QQmusic采取的都是json格式的文件,所以在解析的时候比较简单,也很快速,这也是结构化数据的信息的特点。
五、源码:
https://github.com/pzq7025/Spider
最新文章
- 解决pip安装超时
- home page
- 如何为Eclipse设置代理
- LA 3635 Pie 派 NWERC 2006
- MySQL基础学习之数据库
- ps -aux中的time 的意思
- JSONModel解析数据成Model
- Windbg查看调用堆栈(k*)
- 解决UIScrollView,UIImageView等控件不能响应touch事件的问题
- 关于ES6
- O(n*logn)级别的算法之二(快速排序)的三种实现方法详解及其与归并排序的对比
- Collections.unmodifiableMap(Map map)
- C# IE浏览器 判断是否已经打开了指定Url
- 【resultType】Mybatis种insert或update的resultType问题
- [UE4]利用取模运算达到循环遍历数组的目的
- Java设计模式学习记录-简单工厂模式、工厂方法模式
- Linux内核的启动过程分析
- Swift - 添加纯净的Alamofire
- 004-redis-命令-哈希操作,列表操作
- [LeetCode] Pacific Atlantic Water Flow 题解