filebeat 插件开发
2024-10-20 03:51:05
filebeat是一个轻量的日志收集工具,全套使用go语言开发。
我目前遇到的问题是,在收集的时候需要对数据进行采样,采样比和采样形式要灵活,因为可能在多个项目会使用到这个日志收集功能。刚开始我仔细研究filebeat的配置,我感觉他自身应该带有采集需求,然而并没有。于是我想着去修改他的源码,这样也很方便。然而这个方案不可行,因为这是一个开源项目,后期如果版本更新,那还得继续修改,这个不灵活。于是我想着用插件的方式,看了下filebeat是支持插件的,但是网上很难找到资料。
我最终在官网找到了资料,所以我自己按照他的模式写了我自己的采样插件和一个我们业务用的query解析插件。
filebeat采取的是多个线程同时去读多个文件,每个文件读到数据会被封装为一个event,event经过一系列的processors处理,最终会放在一个队列,这个队列在发送到输出(kafka,es等)
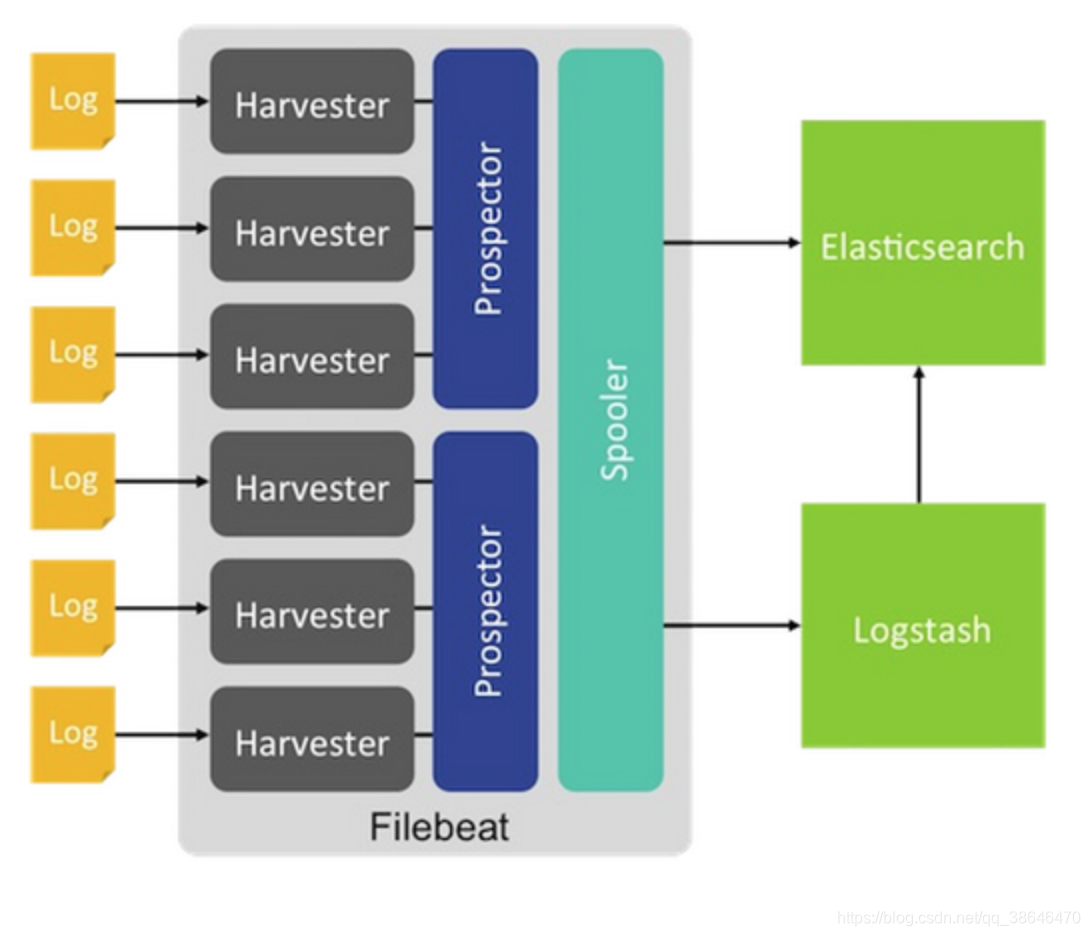
下面直接给大家上我写的插件源码:filebeat 插件源码 附加 filebeat源码
插件使用方法:
- 下载filebeat的源码
- 在beats/libbeat/processors目录下进行插件开发
- 在你需要使用的的平台打包
打包命令:go build -buildmode=plugin - 启动filebeat
filebeat ---plugin ./myplugin.so,多个插件用多个--plugin
插件必须在beats/libbeat/processors目录下编译打包,打包和平台有关,mac下打的包,在linux上不能使用
我用的整套日志收集方案是:
filebeat+kafka+elastis+kibana
- filebeat负责收集
- kafka负责做个缓存;在kafka出来还可以做一些过滤
- elastic负责存储和搜索
- kibana负责展示
最新文章
- Storm进阶
- js实现表单验证 常用JS表单验证
- Architecture Pattern: Publish-subscribe Pattern
- AngularJS 源码分析3
- 认识SuperSocket 1.6.4
- netty定时器HashedWheelTimer(zz)
- Codeforces Round #114 (Div. 2)
- MSP430F149学习之路——AD
- VC窗口最大化方法
- Hadoop中java.lang.ClassCastException: partition解决方法
- CMD下查询Mysql中文乱码的解决方法
- Asp.Net WebAPI Get提交、Post提交处理
- POJ 1631 Bridging signals & 2533 Longest Ordered Subsequence
- 100个linux站点
- Linux下如何高效删除一个几十G的文本文件的最后一行或几行
- Python学习(五):易忘知识点
- 剑指架构师系列-MySQL调优
- 【算法】Normalization
- TPS和QPS的区别和理解【转】
- P2375 [NOI2014]动物园