从Random Walk谈到Bacterial foraging optimization algorithm(BFOA),再谈到Ramdom Walk Graph Segmentation图分割算法
1. 从细菌的趋化性谈起
0x1:物质化学浓度梯度
类似于概率分布中概率密度的概念。在溶液中存在不同的浓度区域。
如放一颗糖在水盆里,糖慢慢溶于水,糖附近的水含糖量比远离糖的水含糖量要高,也就是糖附近的水糖的浓度高,离糖越远的水糖的浓度越低。
这种浓度的渐减(反方向就是渐增)叫做浓度梯度。可以用单位距离内浓度的变化值来表示。同样,温度、电场强度、磁场强度、重力场、都有梯度的。
化学溶液的浓度梯度的概念和概率分布的梯度类似,都代表了值下降的方向。

0x2:趋化性细菌的运动方式
细菌趋化性是指有运动能力的细菌对物质化学浓度梯度作出的反应,使细菌趋向有益刺激,逃避有害刺激。
Engelmann 和 Pfeffer 发现细菌的运动不是任意的,而是定向移动。直到1960年,Alder深入研究了细菌趋化性的分子机制,提出大肠杆菌(Escherichia coli)对氨基酸以及糖的趋化性是由位于细胞表面的受体蛋白调节的,并由细胞内分子传递信号最终影响细菌的运动。
以大肠杆菌为例,一个细胞有4~10根鞭毛,鞭毛快速旋转使得细胞具有运动的能力。
鞭毛的运动方式分为 2 种:
1. 顺时针旋转(clockwise,CW) - 按照本轮计算的优化方向进行迭代调整
当鞭毛顺时针旋转时,细胞鞭毛分开,原地做翻滚运动,来调整运动方向
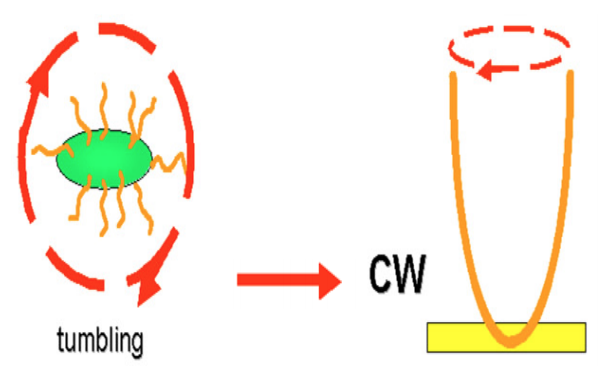
笔者思考:CW过程我们可以理解为LMS过程中计算最速下降梯度方向,但是生物机制没法一步得到最速梯度方向,而且我们知道液体中转动物体也存在粘滞惯性,因此,细菌在CW过程中实际上是在计算一个大致正确的梯度下降方向。它并不是一次得到最优结果,而是依靠多次地不断迭代逐渐靠近最优。
2. 逆时针旋转(counter-clockwise, CCW)
1)在存在局部浓度梯度变化的环境中调整方式 - GD过程
当鞭毛逆时针旋转时,鞭毛拧成一束,产生向前的推动力。
CCW过程中前进的这段,我们可以理解为梯度下降中,每次调整的总距离,即 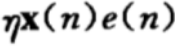 。
。
但是细菌并不是说一次CW调整方向后,就一直保持前进。
细菌先直线运动一段距离 然后通过比较现有浓度和过去浓度(计算浓度梯度)来控制鞭毛接下来的运动方式(根据浓度梯度调整下一步大致方向)。
. 当诱导剂浓度降低或趋避剂浓度增加时,翻滚频率增加(缩短学习率),远离不利环境;
. 反之,翻滚频率降低,细菌泳动,趋向有利环境(类似梯度下降中加入momentum动量因素,如果方向对了就继续保持);
2)在局部环境中浓度梯度都相等时的调整方式 - Ramdom过程
我们知道,溶液中浓度的传播是一种渐变衰减的形态,即一个浓度源的浓度梯度只能传播一定的范围,超过一定的范围就会衰减到几乎无法感知。这就造成了溶液中的浓度梯度看起来就像一个个的小山包此起彼伏。有山包就有山谷、平原。
在无化学刺激物质或浓度相同的化学环境中(可能刚好存在于一个浓度梯度的平原中),细菌先平稳地直线泳动一段距离,然后突然翻滚改变运动方向,再向前泳动, 再翻滚。
泳动和翻滚循序变化,其特点为随机选择运动方向。
这就为细菌提供了一种能力,即脱离困境的能力。即使不小心处于一个没有营养的溶液区域,或者说当前离营养源距离比较远。但是依靠自己的ramdom walk机制,在概率上,通过一定的步数后,是有机会到达存在浓度梯度的区域的,到达了浓度梯度区域后就简单了,细菌自身的趋向性会开始发挥作用,帮助喜欢达到营养源中心。
笔者思考:细菌的浓度梯度趋向性虽然很惊艳,但是也还算平常,毕竟冷热气流也存在密度交换形成暴风,浓度的趋向是自然现象。但是细菌的这个ramdom walk随机试探机制就太神奇了,SGD(随机梯度下降)的发明就是参考了细菌的这种ramdom walk思想。ramdom walk使优化过程具备脱离局部鞍点的能力。
0x3:细菌趋化性分子机制
趋化性的发现刺激了许多科学家的兴趣,Julius Adler用基因、生物化学和行为学方法分析大肠杆菌的趋化行为,为详细了解细菌趋化性分子机制做了铺垫。
趋化细菌膜表面存在专一性的化学受体,以此来感知外界环境中化学物质的浓度变化,并将接收到的化学信号转化为细胞内信号,进而来控制鞭毛的运动方式,表现出相应的趋化性。
通常信号转导途径分 3个部分
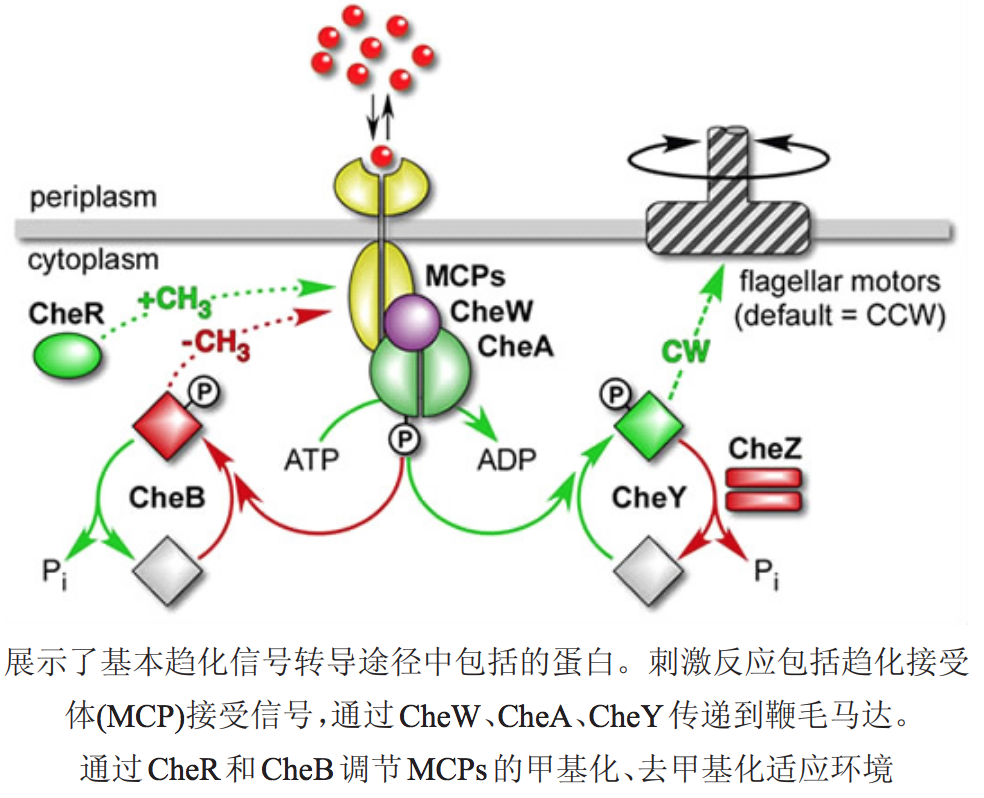
. 膜上趋化受体接收信号;
. 从膜 受体到鞭毛马达的信号转导;
. 对最初信号输入的适应。
Relevant Link:
http://www.casb.org.cn/PublishRoot/casb/2015/6/casb14110008.pdf
2. 随机游走数学模型
下图中黑点表示了不同的随机运动实验,每个球的运动轨迹用不同的颜色表示,可以看到,每个球都呈现出不同的轨迹颜色。这些球的运动可以被统称为随机运动,

0x1:一维空间下的等概论随机运动(伯努利随机游走)
最简单的随机运动形式就是一维运动。

图中的黑点从原点开始,它有各50%的概率向左和向右移动,黑点每次只能随机选择一个方向移动一格。
下图展示了这个黑点运行5次后的可能的运动轨迹:
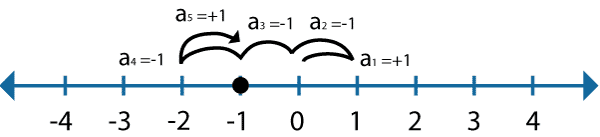
黑点最后停在了“-1”这个点上。这个时候我们肯定有疑问了,这是巧合吗?还是有内在的规律在支配着这一切?
1. 黑点随机运动的本质是什么?
为了讨论这个问题,我们对“黑点随机运动(ramdom walk)”这个实验进行数学抽象。
. 设函数 F(x) 为每次移动远离原点的距离(只针对这次移动而言,不考虑前一次的位置),这是一个随机变量函数;
. 同时,F(x) 由代表每次移动的随机变量 an 决定,F(x) = F(an) = an。显然,an 是一个离散型随机变量,取值可能为 -/+,所以 F(x) 的可能取值也为 -/+;
. F(x) 的损失函数 loss(E(x)) = loss(F(x) - )= loss(an - ),代表了对黑点随机运动的一种抽象化数值考量;
有了抽象表示,接下来我们从损失函数的角度来讨论:在不同损失函数的背景下,黑点的随机运动。
同时,笔者这里要重点强调,不同的损失函数代表的实际物理意义是不同的。
1. 在均值损失函数背景下,对黑点随机运动的计算本质上是在计算最后黑点停留的位置(相对原点)
在均值损失函数条件下,我们要求黑点N次随机运动后停留的位置,就是在求函数 F(x) 的均值。
现在假设我们让黑点运行N次(N可以为任意数字)作为一次实验,记录最后黑点停止的位置。
显然,每次运行N次的结果都会不一样,那我们该怎么去形式化地认知这个现象呢?
这就要引入极限和均值的思想。
我们用<d>表示当N趋向于无限时,黑点最后距离原点的距离的均值;<an>表示黑点每次运动前进的均值。所以有下式:
<d> = <(a1 + a2 + a3 + ... + aN)> = <a1> + <a2> + <a3> + ... + <aN>
同时,可以计算得到,<a1>=0。 因为如果我们重复这个实验趋向于无限次,a1有相同的概率得到 -1 或者 +1,所以均值为0。以此类推:
<d> = <a1> + <a2> + <a3> + ... + <aN> = 0 + 0 + 0 + ... + 0 = 0
这个分析过程可以使用数学中的数学期望进行抽象。
1)数学期望的定义
如果随机变量只取得有限个值或无穷能按一定次序一一列出,其值域为一个或若干个有限或无限区间,这样的随机变量称为离散型随机变量。
离散型随机变量的一切可能的取值 xi 与对应的概率 p(xi) 乘积之和称为该离散型随机变量的数学期望,记为 E(x)。它是简单算法平均的一种推广,类似加权平均。
数学期望为描述随机过程和随机变量提供了一种可量化的工具。
2)黑点最后停止的位置等于黑点随机运动的数学期望
E(x) = -1 * 0.5 + 1 * 0.5 = 0
当然,这种等价性只有在 N 趋近于无限次的前提下才能成立。
3)平均距离说明了什么?
从平均的角度来看,这个结果表明在大量实验下,黑点最终会停留在原点位置,这也是上帝是公平的一种数学抽象表示。
2. 在均方根(root-mean-squared)损失函数的背景下,对黑点随机运动的计算本质上是在计算黑点总共运行的距离(恒正值)
1)计算均方根损失
在一次实验中,d 可能为正值或者负值。但是 d2 永远是正值。
<d2> = <(a1 + a2 + a3 + ... + aN)2> = <(a1 + a2 + a3 + ... + aN) (a1 + a2 + a3 + ... + aN)>
= (<a12> + <a22> + <a32> + ... + <aN2>) + 2 (<a1a2> + <a1a3> + ... <a1aN> + <a2a3> + ... <a2aN> + ...)
我们逐项分解来看:
<a12> = 1,因为a1取-1和+1的概率是相等的。同样的道理<a22>, <a32>, ...<aN2>
接下来看<a1a2>,有4种可能的取值,每种取值的概率都相等:

可以计算得到,<a1a2> = 0,同样的情况对<a1a3>, <a1aN>, <a2a3>, <a2aN>成立。所以:
<d2> = (<a12> + <a22> + <a32> + ... + <aN2>) + 2 (<a1a2> + <a1a3> + ... <a1aN> + <a2a3> + ... <a2aN> + ...)
= (1 + 1 + 1 + ... +1) + 2 (0 + 0 + ... + 0 + 0 + ...) = N
接着对<d>开根号,得到:
sqrt(<d2>) = sqrt(N)
2)为什么均方根损失函数比平均值损失要大?
在机器学习最优化过程中很常用的均方根损失,有一个很好的数学特性,就是“放大误差”,即如果某次实验出现了和预期不一致的结果,均方根可以将这个误差放大,而不至于被掩盖在均值为0的假象中。
也可以这么理解,黑点每次实验,不管是向前还是向后,都是在“运行一步的距离”,均方根并不关心前进的方向,只计算相对的前进值,因此永远是正值。
0x2:在多维空间中的Ramdom Walk
多维空间中的ramdom walk分析方法和上一节的一维是一样,区别只是随机变量变成了多维随机向量。
0x3:Ramdom Walk在现实生活中的例子
当空气例子散布在一个房间中时,ramdom walk原理决定了一个例子从一个位置移动到另一个位置的距离。
0x4:包含偏置的随机游走(biased random walk)
偏置可能由下列两种情况组合而成:
. 向不同方向行走的概率不相等,例如可能是 %向左- %向右;
. 向不同方向移动的步数(step size)不同,例如可能向左移动是1步,而向右是2步;
可以很容易想象,上述两种偏置都是导致ramdom walk的轨迹向右偏移(net drift to the right)。换句话说,我们可以说随机游走向右偏置了。
下图展示了第二种偏置情况下,黑点的可能运行轨迹。

0x5:细菌的趋化性本质上是一种偏置随机游走
1. 在没有浓度梯度的环境下细菌呈现等概论随机游走
严格来说,这个小节的标题应该叫,在不存在“局部”浓度梯度环境下,因为细菌没有上帝视角,它只能感知到自己周围一定范围内的浓度梯度。
当不存在浓度梯度的时候,细菌先平稳地直线泳动一段距离,然后突然翻滚改变运动方向,再向前泳动, 再翻滚。这对应的就是等概论等步长的随机游走过程。
2. 在有浓度梯度的环境下细菌呈现偏置随机游走
当细菌感知到周围存在浓度梯度的时候,细菌通过鞭毛逆时针旋转进行方向调整,超浓度梯度增加的方向移动。这对应的就是不同方向概率不同的偏置随机游走过程。
Relevant Link:
https://wenku.baidu.com/view/81d7a657a36925c52cc58bd63186bceb19e8edc2.html
http://www.mit.edu/~kardar/teaching/projects/chemotaxis%28AndreaSchmidt%29/random.htm
http://www.mit.edu/~kardar/teaching/projects/chemotaxis%28AndreaSchmidt%29/gradients.htm
https://blog.csdn.net/u012655441/article/details/62216304
3. 细菌觅食优化算法 - Bacterial foraging optimization algorithm(BFOA)
0x1:BFOA的发展历史
细菌觅食优化算法(BFOA)被Passino所提出,对于仿生学优化算法大家庭来说是一个新兴技术。
对于过去的50年来,优化算法(像遗传算法(GA)、进化规划(EA)、进化策略(ES)),从进化和自然遗传上给了研究人员许多的灵感,已经占领了优化算法领域。
最近几年,自然群体激发了算法(像粒子群优化(PSO)算法、蚁群算法(ACO)),已经找到了它们应用领域。
跟随着相同的群体算法趋势,Passino提出了BFOA算法。
大肠杆菌群体觅食策略的应用在多元函数最优化算法中是一个很关键的想法原型。
. 细菌以一种可以最大限度的提高单位时间内获得能量的方式去寻找食物;
. 个体细菌通过发送信号来与其他的细菌进行交流;
细菌在考虑前面两个因素之后做出进行觅食的决定。这个过程中,当寻找到食物后细菌做出最小的步长的移动,这个过程叫做趋化。
BFOA的关键思想是在问题搜索空间模仿细菌趋化运动。
从该算法出现以来,BFOA吸引了许多来自不同知识领域的研究人员的关注,主要是由于它的生物学驱动方式和神奇优美的结构。研究人员正在尝试着去混合BFOA算法与其他不同的算法,尽量去探索该算法的局部和全局两个方面的特性。
它已经被应用到许多现实世界的真实问题上。可以预见,数学模型,适应性,算法针对特定场景问题的定制化修改可能是BFOA将来的主要研究方向。
0x2:BFOA算法的生物动力模型
1. 细菌系统中主要4种机制
1)趋化运动
在实际的细菌觅食过程中,运动是靠一系列拉伸的鞭毛来实现的。鞭毛帮助的大肠杆菌细菌翻滚或游泳,这是由细菌在觅食时执行两个基本操作。
. 翻转:当它们顺时针方向翻转时,每一根鞭毛都会拉动细胞。这导致了鞭毛的独立运动,并且最终以最少的代价去翻转。在糟糕的地方则频繁地翻转,去寻找一种营养梯度;
. 游泳:逆时针方向移动鞭毛有助于细菌以非常快的速度游泳;
细菌经历了趋化,朝着它们喜欢的营养梯度地方移动并且避免进入有害的环境。
通常情况下,细菌在友好的环境中会移动较长的一段距离。下图展示了细菌的两种运动模式:
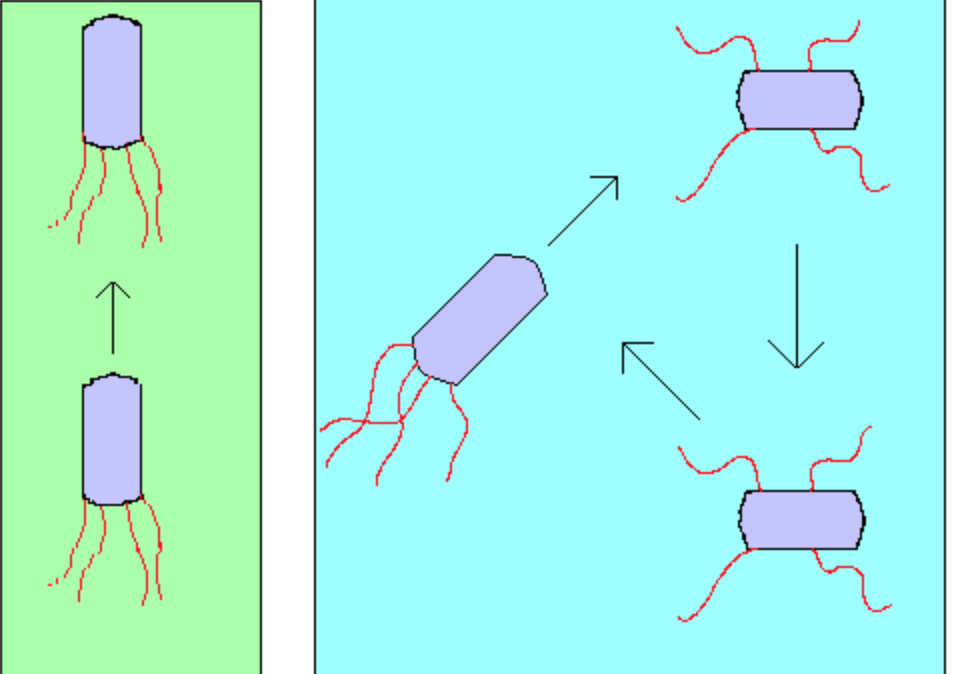
Fig.1. Swim and tumble of a bacterium
2)复制
当它们获得了足够的食物,它们的长度增加以及面对着合适的温度,它们将从自己本身的中间断裂开来,形成两个新的细菌。这个现象启发Passino在BFOA中引进繁殖事件。
3)消除-分散
由于突然的环境变化或攻击发生后,趋化过程可能被破坏,一群细菌可能会转移到其他地方或者一些细菌可能被引进到细菌群中。这些构成了真实细菌环境中的消除-分散事件。
4)群体
一个区域内的所有细菌被杀死或者一组细菌分散到环境的新部分
2. 形式化定义细菌系统机制
现在我们假设每个细菌的“人生终极目标”为 J(θ),每个细菌的各种趋化、繁衍等机制,目的都是想要找到最小的 J(θ),其中θ ∈ R (θ is a p-dimensional vector of real numbers)。这样,就可以在最优化理论的框架内对细菌的各种生存机制进行分析。
注意,我们没有关于梯度∇J ( θ ) 的测量或者分析描述,实际上,细菌并能准确计算出本次移动的浓度梯度∇J ( θ )
BFOA模拟了细菌系统中的四个观察到的主要机制:趋化,群体,复制以及消除-分散。
BFOA解决的是一个无梯度优化问题。
一个虚拟细菌事实上是一个实验方案(可能称为搜索代理)在其优化面移动(见Figure2),来寻找全局最优解。
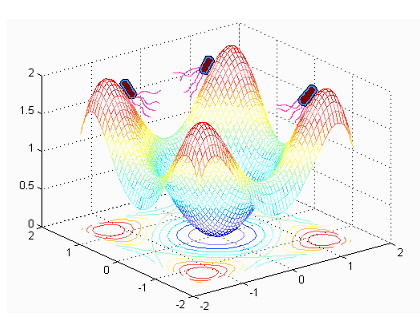
Fig.2. 每个细菌都在寻找全局最优解,同时又一起构成一个整体群体
为了方便后续的套路,我们进行符号化定义:
. 定义 j 作为趋化步骤索引、k 作为复制步骤索引、l 作为消除-分散步骤索引;
. p:搜索空间维度;
. S:群体中细菌的总数;
. Nc:趋化步骤的步数;
. Ns:游泳长度;
. Nre:复制步骤的次数;
. Ned:消除-分散事件的次数;
. Ped:消除-分散概率;
. P( j , k , l ) = {θ ( j , k , l ) | i = ,,..., S} :代表 j 趋化步骤中,S细菌群体中的每一个成员的位置、k 复制步骤、l 消除-分散事件;
. J( i,j,k,l ):表示在 i 细菌搜索定位中的消耗(代价)。我们可以将J当作“cost”代价来做参考(用优化理论的术语);
对于现实世界中的细菌种群,S可能(可以)可能是非常大的(例如:S=上万),但是p=3。这很容易理解,一个培养皿中,有上万的细菌在三维的溶液中进行移动。
在我们的BFOA计算模拟中,种群数代表了我们需要进行全局最优化的目标函数数量,通常这个数字不会非常大(几十、几百最多了),例如后面会讨论的ramdom walk图分割算法。
同时,BFOA允许p>3,以至于我们能够运用这种方法在高维度优化问题中。
下面我们将简要的描述这四种BFOA中的主要步骤。
1)趋化
这个过程模拟一个大肠杆菌细胞的运动,通过利用鞭毛的游泳和翻转。它可以在一定时间内朝着一个相同的方向游去或者也可以翻转,或者在整个生命周期中在两中操作模式之间来回的轮流替换。
假设 θ<i>( j,k,l ) 代表 i 细菌在 j 趋化、k 复制,l 消除-分散步骤中。C(i) 是翻转过程中采取指定的随机方向的步长的大小(运行长度单元)。
在细菌的一次趋向过程中,细菌的运动方向可能根据下式表示:
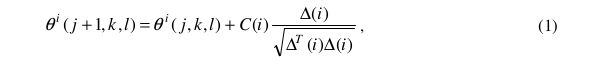
其中 △i 指定为一个随机方向向量,元素范围为[-1,1]
2)群聚
群聚这个有趣的群体行为,已经在好几种细菌物种里被发现有类似的行为,包括大肠杆菌,鼠伤寒沙门氏菌。
其中复杂性和稳定性的时空格局(群聚)形成在半固体培养基。在群聚中,细胞不是但个体的行为,而是个体与个体间互相影响的复杂行为模式。
在一次实验中,当使用一个营养化疗效果器放置半固体基质到其中时,大肠杆菌细胞依靠拉动营养梯度来安排自己在一个群聚圈中。
在另一次独立实验中,当使用一个高等级的琥珀酸去刺激时,大肠杆菌细胞释放一个有吸引力的谷草,这可以帮助他们去聚集成一个群组,从而移动成像高密度细菌群体的同心圆形状图案。
这种细胞-细胞信号传导在大肠杆菌群体中可以通过下面的函数来表示出来:
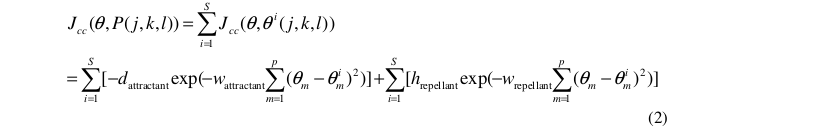
其中 表示是目标函数值;
表示是目标函数值;
S是细菌的总数;
p是将要被优化的变量的数量(即搜索空间的维度);
每一个细菌 都是p维搜索域中的一个点;
都是p维搜索域中的一个点;
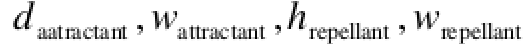 是需要被搜索优化的系数(超参数)。
是需要被搜索优化的系数(超参数)。
3)复制
至少当每一个健康的细菌无性分裂成两个细菌,然后放置在原先的位置,健康的细菌才最终死亡。这样将保持细菌群体大小的不变。
4)消除和扩散
细菌生活的环境逐渐的改变或者突然的改变都可能由于各种各样的原因而发生。
例如:当地显著的气温上升可能杀死一组目前生活在一个区域内且有高浓度营养盐梯度的细菌。以至于一个区域内的细菌都被杀死或者一组细菌扩散到一个新的区域。这是一种种群群体移动的现象。
BFOA对这一现象的模式方式如下:
一些细菌被以很小概率的随机地清算掉,随后新的替代品细胞们在搜索空间被随机初始化后。
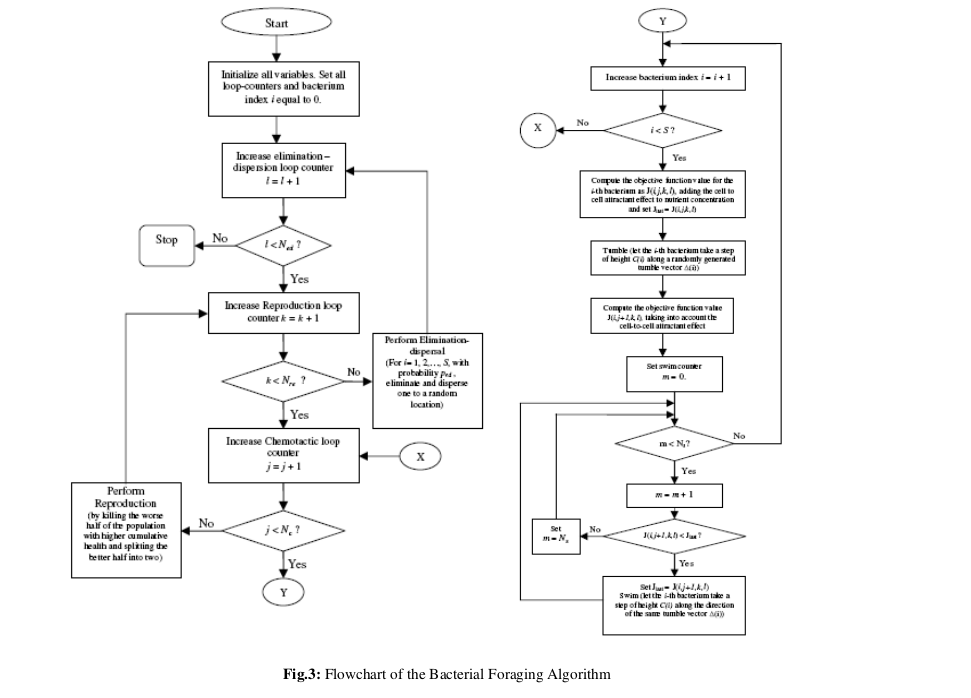
0x3:BFOA算法流程
参数:
【步骤 1】初始化参数 p,S,Nc,Ns,Nre,Ned,Ped,C(i)(i=1,2,…S),θi
算法:
【步骤 2】消除-扩散 循环 loop:l=l+1
【步骤 3】复制循环 Loop:k=k+1
【步骤 4】趋化循环 Loop:j=j+1
[a] i=1,2,……S 细菌 i 进化趋化移动
[b] 计算适应值函数 J(i,j,k,l)
[c] 让  保存值,因为通过移动我们可能找到更好的。
保存值,因为通过移动我们可能找到更好的。

【步骤 5】如果 j < Nc,跳转到步骤4。这种情况下继续进行趋化,因为细菌的生命并未结束。
【步骤 6】复制 - 消除:
[a] 根据给定的 k 跟 l,对i=1,2,……S,循环,让

作为 i 细菌的一种它生命周期中度过多少营养以及怎样成功的避免有害物质的数值化衡量。高代价意味着低健康。
[b] 拥有最高的 Jhealth值的 Sr 细菌死亡,拥有最低的Jhealth值的细菌分裂开来(结果放置在它们原先的父母的位置)。
【步骤 7】如果 K < Nre,跳到步骤3。这种情况下,我们没有达到制定复制的数量,所以,我们开始下一次趋化循环,产生后代。
【步骤 8】驱散:以概率Ped 进行循环 i=1,2,……S,驱散每一个细菌(保持持续不变的细菌种群数量)。如果 l < Ned,然后跳转到步骤2;否则结束。
流程图如下所示:
Relevant Link:
http://www2.ece.ohio-state.edu/~passino/PapersToPost/BFO-IJSIR.pdf
https://ieeexplore.ieee.org/document/1004010
https://www.cnblogs.com/L-Arikes/p/3734353.html
4. 一种全局最优化算法 - 随机游走算法(Random Walk)
0x1:随机游走算法步骤
设目标函数 f(x) 是一个含有 n 个变量的多元函数,x=(x1,x2,...,xn) 为 n 维向量。f(x) 的超曲面空间就是我们要进行搜索的向量空间。
1)给定初始迭代点 x,初始行走步长λ,控制精度ϵ(ϵ是一个非常小的正数,用于控制结束算法);
2)给定迭代控制次数 N,k 为当前迭代次数,置 k=1;
3)当 k < N 时,随机生成一个(−1,1) 之间的 n 维向量 u=(u1,u2,⋯,un),(−1 < ui < 1,i=1,2,⋯,n),并将其标准化得到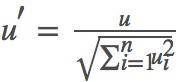 。令 x1 = x + λu′,完成第一步游走尝试(注意这一步仅仅只是尝试)。
。令 x1 = x + λu′,完成第一步游走尝试(注意这一步仅仅只是尝试)。
4)计算函数值
4.1)如果 f(x1) < f(x),即找到了一个比初始值好的点,那么 k 重新置为1,同时将 x1 变为 x(完成实际的前进),回到第2步;
4.2)否则 k = k+1,回到第3步,继续其他方向的随机游走的尝试。
5)如果连续 N 次都找不到更优的值,则认为,最优解就在以当前最优解为中心,当前步长为半径的 n 维球内(如果是三维,则刚好是空间中的球体)。此时:
5.1)如果 λ < ϵ,则结束算法,即算法已经收敛;
5.2)否则,令 λ= λ / 2,减小学习率,回到第1步,开始新一轮游走。
0x2:随机游走的代码实现
我们假设目标函为 ,实际的目标函数可能是任意形式的,根据你自己在项目里的实际场景而定。
,实际的目标函数可能是任意形式的,根据你自己在项目里的实际场景而定。
我们的目标是求 f(r) 的最大值。
该函数是一个多峰函数,在 (50,50) 处取得全局最大值 1.1512,第二最大值在其全局最大值附近,采用一般的优化方法很容易陷入局部极大值点。
这里是求解函数的最大值问题,可以将其转化为求目标函数的相反数的最小值问题,即对偶求解思想。具体代码如下:
#!/usr/bin/env python
# -*- coding: utf- -*- from __future__ import print_function
import math
import random N = # 迭代次数
step = 0.5 # 初始步长
epsilon = 0.00001 # 收敛阈值
variables = # 变量数目,搜索空间的维度
x = [, ] # 初始点坐标
walk_num = # 初始化随机游走次数 print("迭代次数:", N)
print("初始步长:", step)
print("epsilon:", epsilon)
print("变量数目:", variables)
print("初始点坐标:", x) # 定义目标函数
def obj_function(p):
r = math.sqrt((p[]-)** + (p[]-)**) + math.e
f = math.sin(r) / r +
return -f # 开始随机游走
while(step > epsilon): # 判断是否收敛停止算法
k = # 初始化计数器
while(k < N):
u = [random.uniform(-, ) for i in range(variables)] # 随机向量
# u1 为标准化之后的随机向量
u1 = [u[i] / math.sqrt(sum([u[i]** for i in range(variables)])) for i in range(variables)]
x1 = [x[i] + step*u1[i] for i in range(variables)] # 随机游走尝试
if(obj_function(x1) < obj_function(x)): # 如果找到了更优点
k = # 重置 k
x = x1 # 更新坐标
else:
k += # 继续下一次随机游走尝试
step = step/
print("第 %d 次随机游走完成。" % walk_num)
walk_num +=
print("随机游走次数:", walk_num-)
print("最终最优点:", x)
print("最终最优值:", obj_function(x))
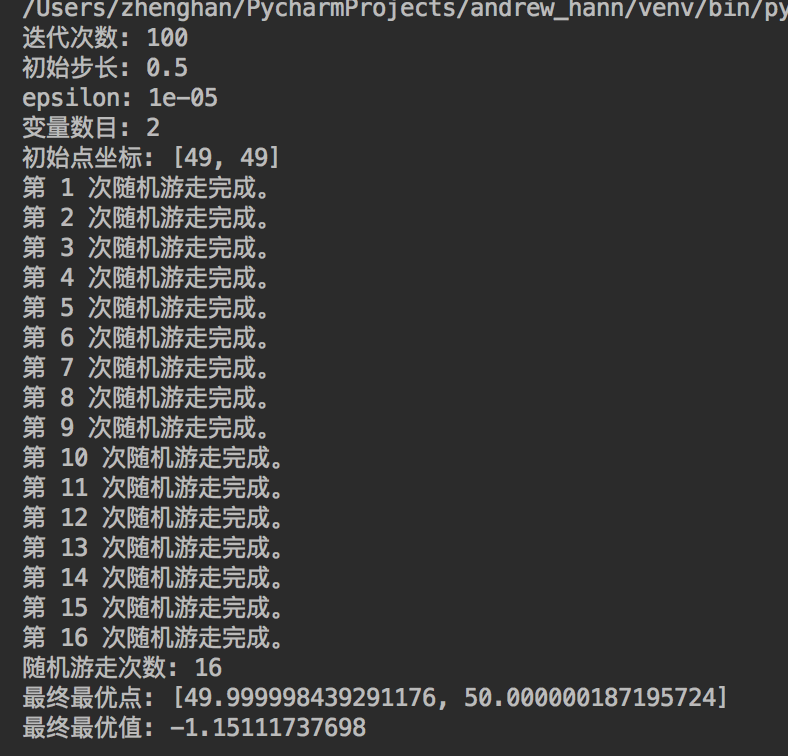
1. 随机游走依然容易陷入局部鞍点
基本的随机游走算法对于初始点比较敏感,可以看出,当初始点位于最优点附件时,可以很好地达到全局最优点;
如果将初始点设置得离最优点较远,比如设置初始点为(10,10)时,其他参数不变,得到结果为:
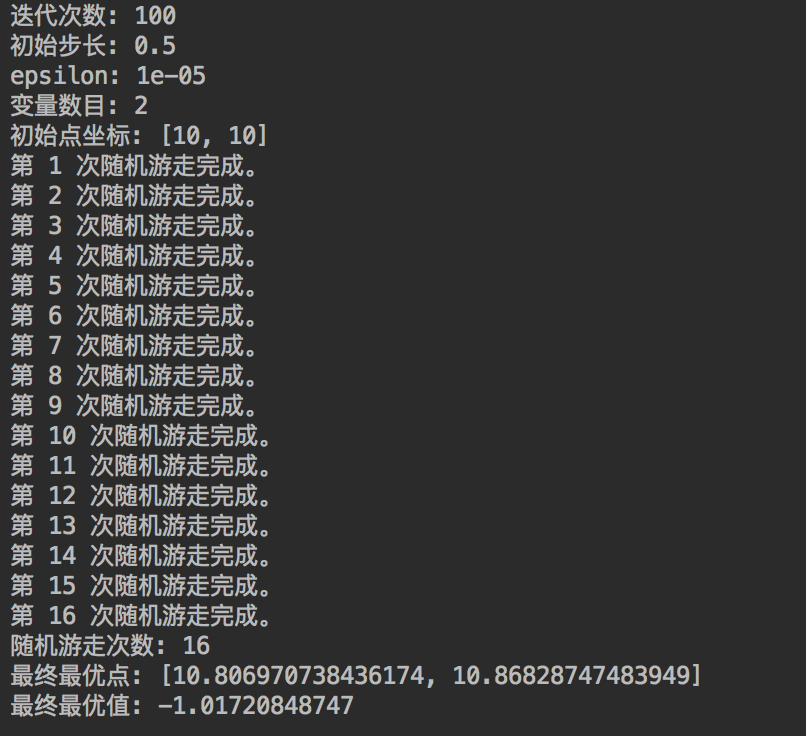
可以发现,随机游走陷入了局部最优点。
2. 扩大尝试次数 N、以及步长 λ 有助于脱离局部最优点
不管是SGD,还是随机游走,都一样面临陷入局部最小值的问题中。解决(或者说缓解)这一问题的方法是增大迭代次数 N 以及初始步长λ,可以在一定程度上增加寻优能力。
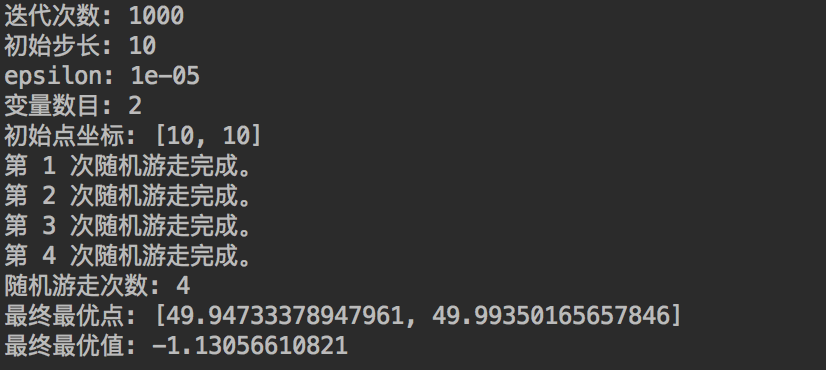
当然,增大迭代次数 N 以及初始步长 λ 也会引入新的问题,就是增大收敛过程的抖动,可以想象,如果目标函数已经优化到真正的全局最小值点附近了,因为步长 λ 过大,目标函数会不断在极值点附近来回摆动。
0x3:改进的随机游走算法
改进的随机游走算法的不同之处是在于第3步,原来是产生一个随机向量u,现在则是产生n个随机向量u1,u2,⋯,un,n是给定的一个正整数。
将 n 个 ui(i=1,2,⋯,n) 标准化得到u′1,u′2,⋯,u′n,利用公式 xi = x + λu′i,令min{x1,x2,⋯,xn}替换原来的x1,其他步骤保持不变。
改进的核心思想在于:增加了ramdom process的干预程度,原本只有一次ramdom process,即决定一个确定的方向后进行随机游走尝试。改进后变为在各个维度上全部ramdom,
同时在各个向量维度上进行随机游走尝试,最后再综合评价本次随机游走尝试的优劣。
通过这种方式改进之后,随机游走算法的寻优能力大大提高,而且对于初始值的依赖程度也降低了。
令n=10,初始点为(−100,−10),N=100,λ=10.0,ϵ=0.00001,改进的随机游走算法实现代码如下:
#!/usr/bin/env python
# -*- coding: utf- -*- from __future__ import print_function
import math
import random N = # 迭代次数
step = 10.0 # 初始步长
epsilon = 0.00001
variables = # 变量数目
x = [-,-] # 初始点坐标
walk_num = # 初始化随机游走次数
n = # 每次随机生成向量u的数目 print("迭代次数:", N)
print("初始步长:", step)
print("每次产生随机向量数目:", n)
print("epsilon:", epsilon)
print("变量数目:", variables)
print("初始点坐标:", x) # 定义目标函数
def obj_function(p):
r = math.sqrt((p[]-)** + (p[]-)**) + math.e
f = math.sin(r)/r +
return -f # 开始随机游走
while(step > epsilon):
k = # 初始化计数器
while(k < N):
# 产生n个向量u
x1_list = [] # 存放x1的列表
for i in range(n):
u = [random.uniform(-,) for i1 in range(variables)] # 随机向量
# u1 为标准化之后的随机向量
u1 = [u[i3]/math.sqrt(sum([u[i2]** for i2 in range(variables)])) for i3 in range(variables)]
x1 = [x[i4] + step*u1[i4] for i4 in range(variables)]
x1_list.append(x1)
f1_list = [obj_function(x1) for x1 in x1_list]
f1_min = min(f1_list)
f1_index = f1_list.index(f1_min)
x11 = x1_list[f1_index] # 最小f1对应的x1
if(f1_min < obj_function(x)): # 如果找到了更优点
k =
x = x11
else:
k +=
step = step /
print("第%d次随机游走完成。" % walk_num)
walk_num += print("随机游走次数:",walk_num-)
print("最终最优点:",x)
print("最终最优值:", obj_function(x))
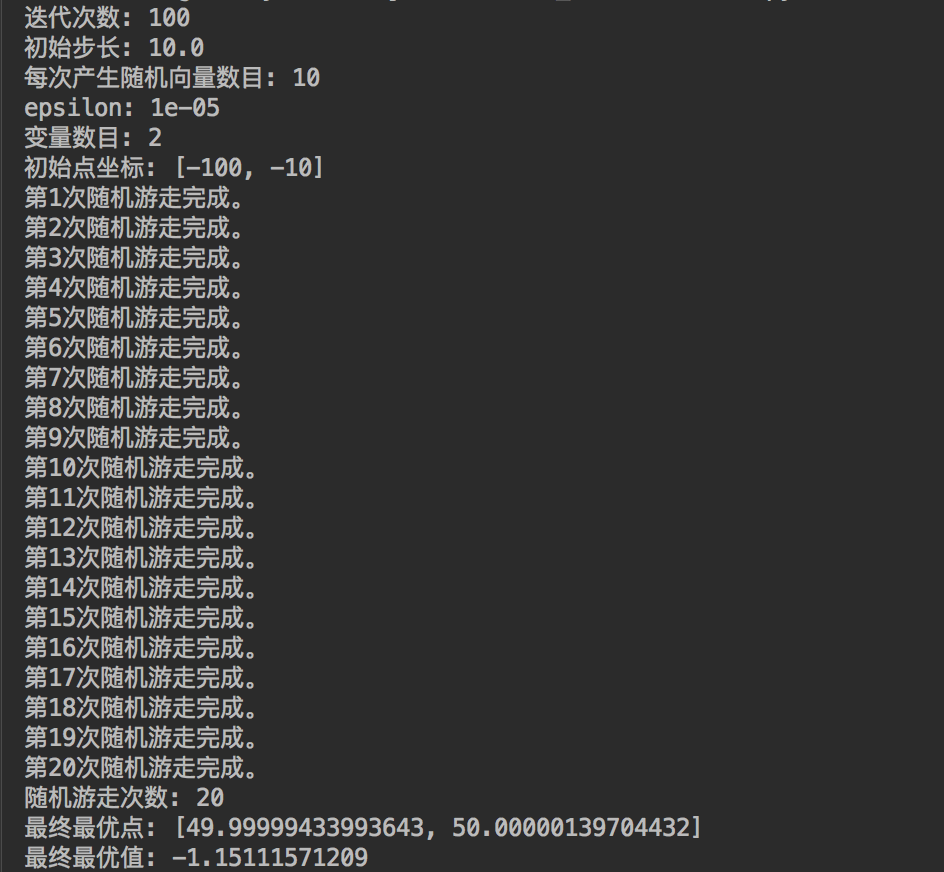
可以发现,即使迭代次数N=100不大,初始点(−100,−10)离最优点(50,50)非常远,改进的随机游走算法依然可以达到最优点。
这说明了改进的随机游走算法具有更强大的寻优能力以及对于初始点更低的依赖性。
笔者思考:不管是SGD/GD还是batch-SGD,每次FP和BP过程的权重调整都是针对所有神经元同时进行的,同一个层上的神经元收到的调整反馈都是相同的。
在这一点上,SGD跳出局部鞍点的能力就没有改进后的随机游走算法强。
0x4:步长 λ 的意义
无论是随机游走算法还是改进的随机游走算法,对于步长都是非常依赖的。
步长λ越大,意味着初始可以寻找最优解的空间越大,但同时也意味着更多的迭代次数(要搜索空间变大,寻找次数变多,相应时间自然要增加)。
如果步长取得过小,即使N很大,也很难达到最优解,过早陷入局部最优。
无论对于随机游走算法还是改进的随机游走算法皆是如此。所以理论上步长λ越大越好。但是步长越大,迭代总次数越高,算法运行时间越长。所以实践中可以多试验几次,将λ取得适当地大即可。
Relevant Link:
http://www.cnblogs.com/lyrichu/p/7209529.html
http://www.cnblogs.com/lyrichu/p/7209529.html
5. Ramdom Walk Graph Segmentation 随机游走图像分割算法
假设我们要对一个网络进行模块挖掘,那么一种可行的方法就是随机挑选网络中的一些节点作为种子节点,然后进行随机游走(计算马尔科夫矩阵),对于计算结果,我们可以只取概率较高的前几个作为可到达节点,之后采用一种类似于序列比对的方法来将所有种子节点游走的结果进行比对拼接,然后获得不同的模块。这样做的一个好处就是结果较为稳定,并且所挖掘的模块更加完整可靠。
下面是采用上述方法得到的结果
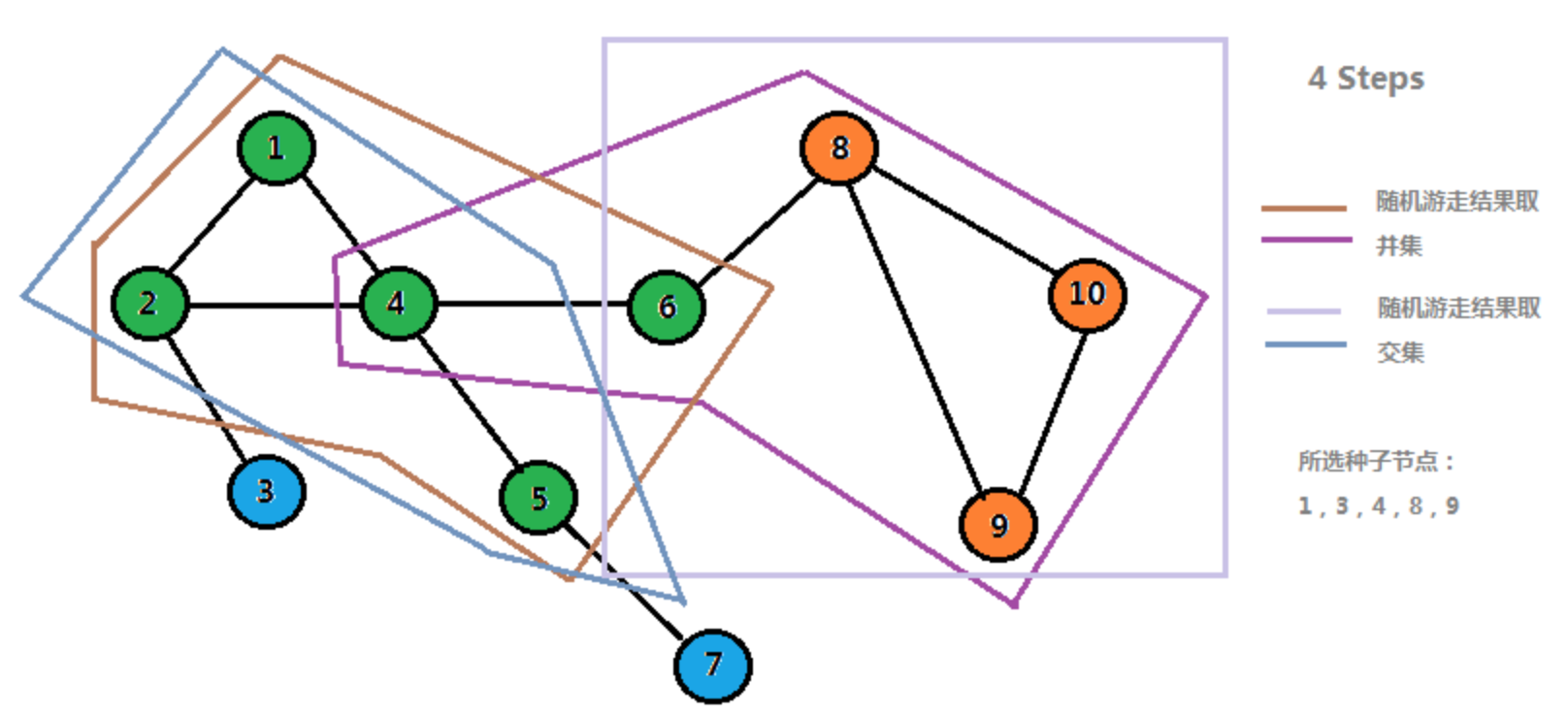
其中相同颜色的节点属于一个模块。
0x1:基于随机游走的图像分割算法思想
随机游走算法是一种基于图论的分割算法,它的分割思想是,以图像的像素为图的顶点,相邻像素之间的四邻域或八邻域关系为图的边(转移概率)。以此构建网络图。
如图所示,图中小圆圈代表图像上的每个像素点,像素点间的折线可看为权重。L1,L2,L3三个种子代表“打标点”,它可以由用户交互式输入,也可以是有监督学习中的打标样本。
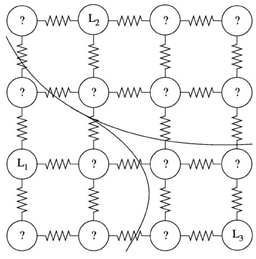
以未标记像素节点为初始点,RandomWalk从未标记顶点开始随机漫步,首次到达各类标记顶点的概率代表了未标记点归属于标记类的可能性,把最大的概率所在类的标签赋给未标记顶点,完成一次分割,或者说完成一次归属,原本未标记的顶点现在归属到了一个类别中。
在上图中可以看到,L1/L2/L3 作为标记的种子点。把图像分割成对应的三部分。
0x2:算法流程
1. 建立图模型
1)无向连通图
首先,定义一个连通无向图G=(V,E),用图G 给图像建模。其中V是顶点集合,E是图中任意两个顶点的无向边集合,对应图像像素的连接关系,连接两个顶点 vi 和的边 用 vj 表示。
2)边权重矩阵
带权图要为每条边赋权值,边 eij 的权值用 wij 表示,权重的计算公式如下:
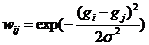 ,其中,gi 表示个像素点的灰度值、或纹理信息等参数;
,其中,gi 表示个像素点的灰度值、或纹理信息等参数;
3)节点转移概率矩阵
对于图中任意一点 vi 的转移概率,其满足随机游走概率公式:
Lij = di:如果 i = j:di为顶点vi的度,是连接顶点的所有边权值之和,di=sumj wij;
Lij = -wij:如果 i j 是相邻节点,wij 是节点i 和节点j 之间的权重;
Lij = :other;
可构建图的拉普拉斯矩阵,然而拉普拉斯是非满秩矩阵,需要添加边界约束条件,才可根据方程组解出个各未知点的概率。也就是将图像分割问题转换为Dirichlet问题进行求解。Dirichlet问题即就是寻找一个满足边界条件的调和函数。
2. 求解狄利克雷方程
随机游走模型的建立,可以理解为狄利克雷积分条件的离散化。其可以使用拉普拉斯矩阵来进行描述,即对随机游走模型的求解,可以描述为如下方程的最小化求解:
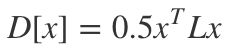
以已标记的K类顶点作为边界约束条件,求解未知点到各个类的概率。例如,求解各未知点游走到L1的概率,则以
因此,狄利克雷方程可以变形如下:
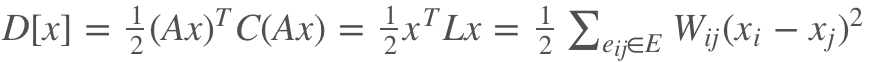
然后把矩阵分成标记的和未标记的。对x_U求偏微分, 一阶导等于0, 得到:
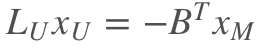
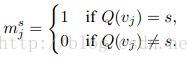
3. 模型的求解
对上述稀疏矩阵线性方程组的求解,最长用的是共轭梯度法。
Relevant Link:
https://yq.aliyun.com/ziliao/522808
https://blog.csdn.net/hjimce/article/details/45201263
https://blog.csdn.net/u011773995/article/details/50438018
https://blog.csdn.net/menjiawan/article/details/47086423
https://blog.csdn.net/Broccoli_Lian/article/details/79739299
最新文章
- CDN模式介绍
- 【跟着子迟品 underscore】Array Functions 相关源码拾遗 & 小结
- fsimage 和 edits log
- Rsync+inotify实现实时同步
- PHP学习笔记:数据库学习心得
- IOS开发一些资源收集
- web系统之session劫持解决
- Android 通过http访问服务器
- Meteor错误:TypeError: Meteor.userId is not a function
- Android WebView 开发详解(三)
- 【T】并行调度
- 转接口IC GM7122:BT656转CVBS芯片 视频编码电路
- React-Router 4 的新玩意儿
- angularjs+ionic+'h5+'实现二维码扫描功能
- C# 把字符串类型日期转换为日期类型(转载)
- cocoapod podpackage 自动根据podfile生成framework实现二进制化,原创脚本,转载请注明出处
- eclipse修改android项目的apk包名类名
- git ssh 22 端口不可用时通过https 443 端口配置git ssh
- 21 Zabbix系统性能优化建议
- Android中查看SQLite中字段数据的两种方式