爬虫实战【9】Selenium解析淘宝宝贝-获取宝贝信息并保存
通过昨天的分析,我们已经能到依次打开多个页面了,接下来就是获取每个页面上宝贝的信息了。
分析页面宝贝信息
【插入图片,宝贝信息各项内容】
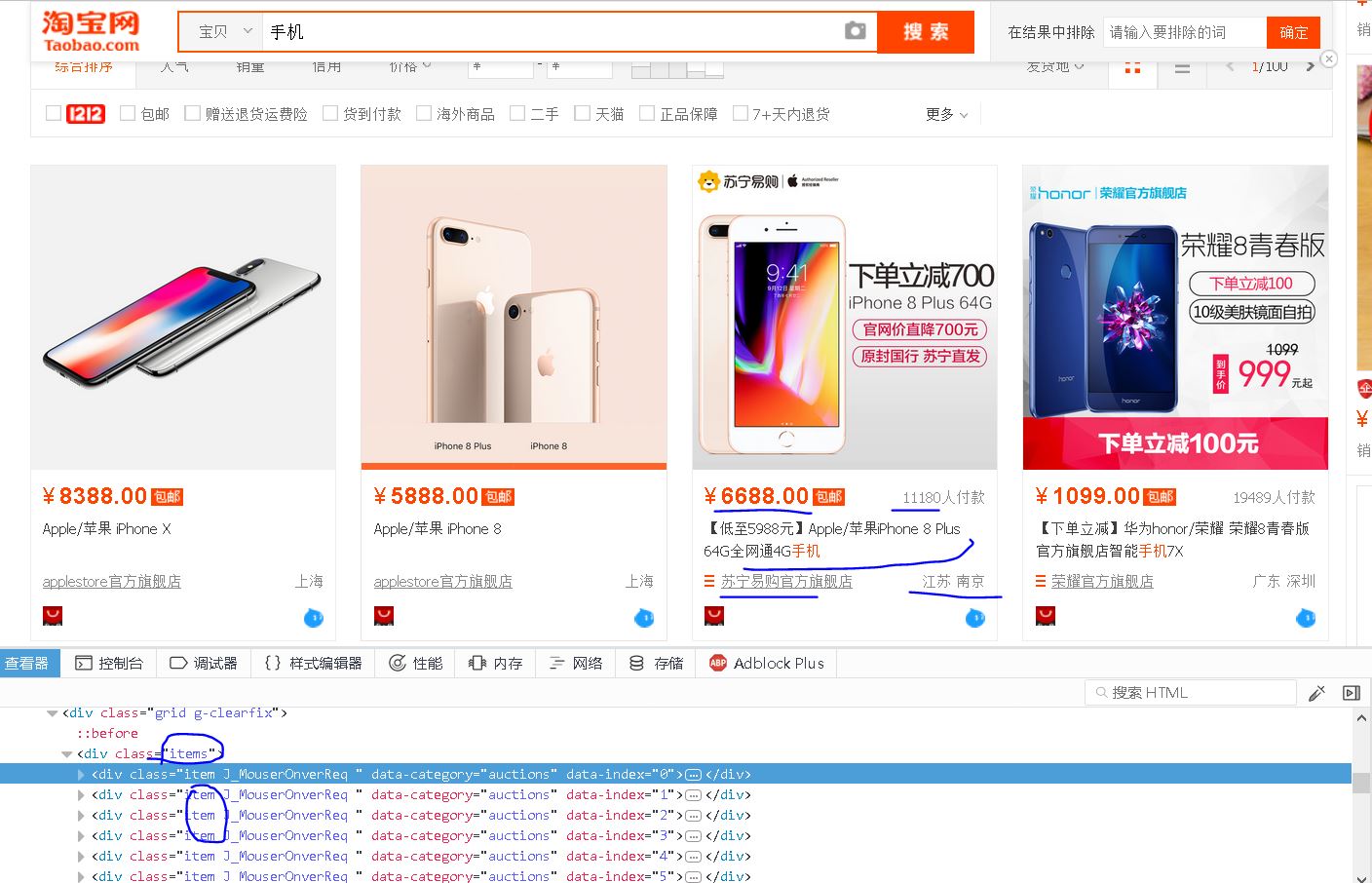
从图片上看,每个宝贝有如下信息;price,title,url,deal amount,shop,location等6个信息,其中url表示宝贝的地址。
我们通过查看器分析,每个宝贝都在一个div里面,这个div的class属性包含item。
而所有的item都在一个div内,这个总的div具有class属性为items,也就是单个页面上包含所有宝贝的一个框架。
因而,只有当这个div已经加载了,才能够断定页面的宝贝信息是可以提取的,所以再提取信息之前,我们要判断这个div的存在。
对于网页源码的解析,这次我们使用Pyquery,轮换着用一下嘛,感觉还是PyQuery比较好用,尤其是pyquery搜索到的对象还能在此进行搜索,很方便。
Pyquery的使用方法请查看我之前的文章,或者看一下API。
下面我们依次来分析一下每项信息应该如何提取。
1、Price
【插入图片,price】
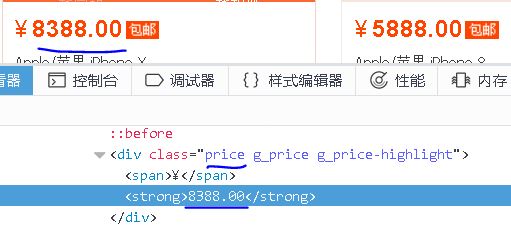
可以看出,price的信息在一个div里面,具有clas属性price,我们如果通过text来获取的话,还会将前面的人民币符号得到,回头切片切掉就好了。
2、Deal Amount
【插入图片,amount】
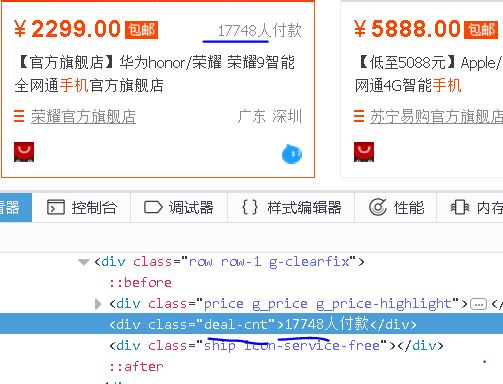
成交量信息再一个class属性为deal-cnt的div标签里面,仍然需要将最后三个字符切掉。
3、Title
【插入图片,title】
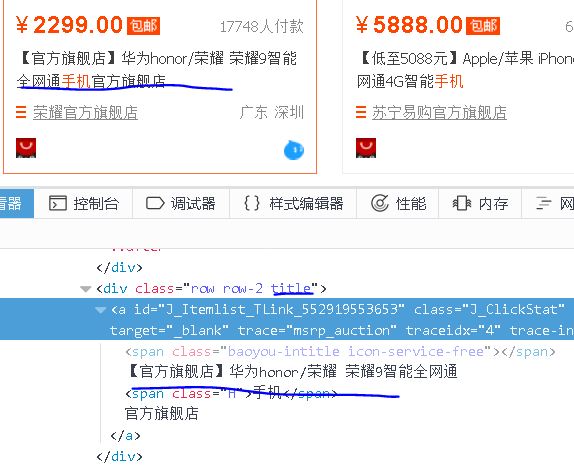
宝贝的标题在一个class属性为title的div标签里面,通过text可以获取。
4、Shop
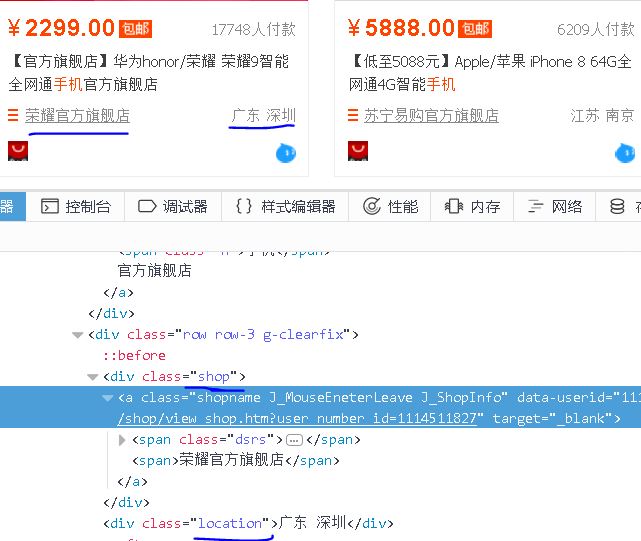
【插入图片,shop和location】
店铺名在一个class属性为shop的div标签呢。
5、Location
同上图,class属性为location。
6、URL
【插入图片,宝贝的地址】

url地址在一个a标签,class属性为pic-link,这个a标签的href属性就是url地址。
from pyquery import PyQuery as pq
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()#讲解一下
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
这里我们在讲一下items的内容,看一下源码中的范例:
> d = PyQuery('<div><span>foo</span><span>bar</span></div>')
> [i.text() for i in d.items('span')]
['foo', 'bar']
>[i.text() for i in d('span').items()]
['foo', 'bar']
>list(d.items('a')) == list(d('a').items())
True
保存数据到MongoDb
如果我们获取到product,想保存到MongoDb数据库中,其实是很简单的,设置好数据库的url、数据库名、表名,通过pymongo链接到对应的数据库。
即使我们数据库还未建立,没关系的,会动态创建表格和数据。
import pymongo
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
【插入图片,MongoDB数据】
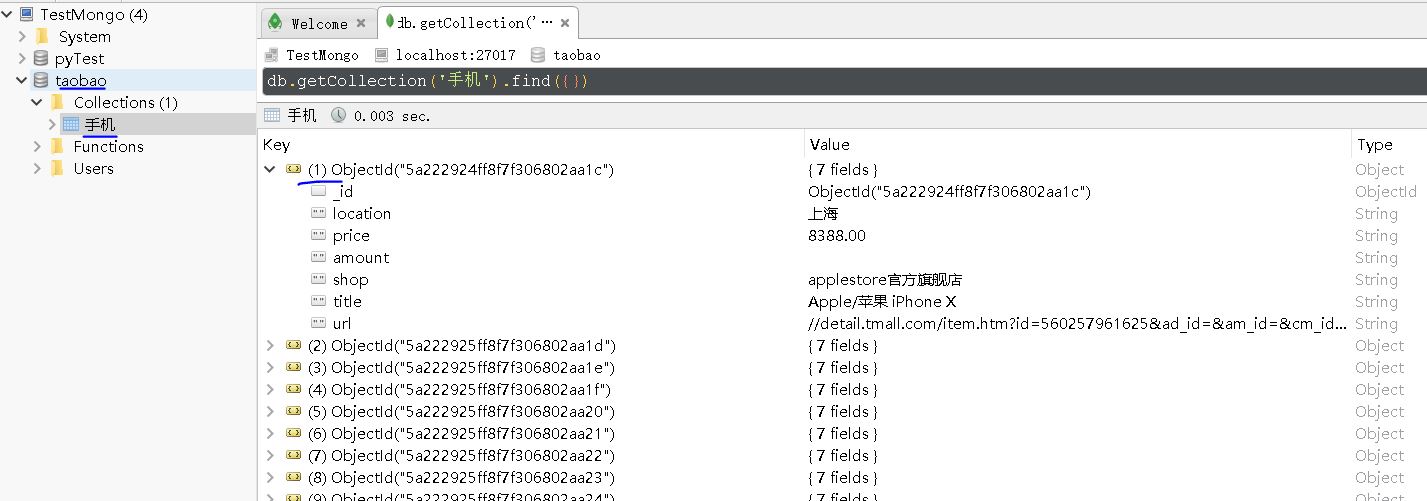
保存数据到CSV文件
其实也就是文本文件,只不过可以通过excel打开,方便我们做一些分析。
这里就不展开讲了,请看代码。
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
全部代码
只要改变KEYWORD关键字的内容,就能搜索到不同的宝贝信息,并保存下来,我们默认保存到csv文件中,数据毕竟只有几千条,还是Excel方便。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
import pymongo
from multiprocessing import Pool
'''要搜索的关键字'''
KEYWORD='Iphone8'
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
'''要保存的csv文件'''
FileName=KEYWORD+'.csv'
'''PhantomJS参数'''
SERVICE_ARGS=['--load-images=false']#不加载图片,节省时间
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
#browser=webdriver.Firefox()
browser=webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
index_url='https://www.taobao.com/'
wait=WebDriverWait(browser, 10)
def search(keyword):
try:
browser.get(index_url)
#user_search_input=browser.find_element_by_css_selector('#q')
#user_search_button=browser.find_element_by_css_selector('.btn-search')
user_search_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
user_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
user_search_input.send_keys(keyword)
user_search_button.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.total')))
total_page=re.compile(r'(\d+)').search(total.text).group(1)
print(total_page)
get_products()
return int(total_page)
except TimeoutException:
search(keyword)
def get_next_page(pageNum):
try:
user_page_input = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/input")))
user_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/span[3]")))
user_page_input.clear()
user_page_input.send_keys(pageNum)
user_page_button.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'li.active > span:nth-child(1)'),str(pageNum)))
get_products()
except TimeoutException:
get_next_page(pageNum)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
def main():
total=search(KEYWORD)
# p=Pool()
# p.map(get_next_page,[i for i in range(2,total+1)])
for i in range(2,total+1):
get_next_page(i)
browser.close()
if __name__=='__main__':
main()
简单分析一下结果
【插入图片,结果分析示例】
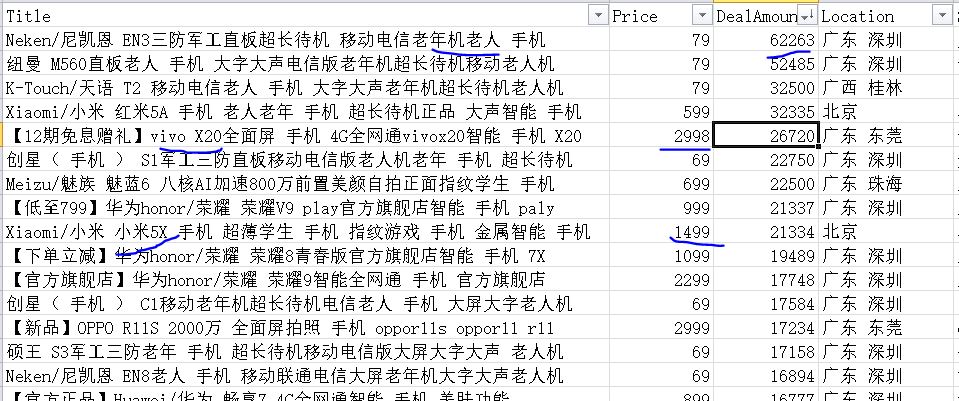
月成交量最好的是一款老人机,只有79元。。。。
智能手机里面,vivo X20是卖的最好的,2999元价位。
1500价位,小米5x出现了。。。
这种类似的分析都是建立在数据挖掘的基础上的,希望你能从本篇内容中学到一些知识。

最新文章
- 10W -python
- C# iis 错误配置信息( 500.19 - Internal Server Error )
- hdu 1851 尼姆+巴什博弈
- 电子面单纸打印时固定高度18cm,到底是多少px
- Spring +SpringMVC 实现文件上传功能。。。
- Solution to “VirtualBox can't operate in VMX root mode” error in Windows 7
- Socket通信(转)
- OpenStack Nova 制作 Windows 镜像
- Xshell常用命令备忘
- POJ C++程序设计 编程题#1 编程作业—STL1
- iOS-打包成ipa
- win7开启远程桌面
- 在VirtualBox中安装了Ubuntu后,Ubuntu的屏幕分辨率非常小,操作非常不便。通过安装VirtualBox提供的“增强功能组件”,-摘自网络
- ELK监控系统nginx / mysql慢日志
- at91sam9x5 linux 4.1.0下使能蜂鸣器驱动
- Razor学习(二)@Html标签
- 集成 Entity Framework
- 关于MySQL用户会话及连接线程
- Servlet中web.xml 以及 <url-pattern>总结
- promise-笔记