Python_selenium之获取页面上的全部邮箱
2024-08-23 07:21:31
Python_selenium之获取页面上的全部邮箱
一、思路拆分
- 获取网页(这里以百度的“联系我们”为例),网址http://home.baidu.com/contact.html
- 获取页面的全部内容(driver.page_source)
- 运用正则表达式,导入re模块找到邮箱的字段
- 循环打印出邮箱(去重)
二、测试脚本
1. 源代码如下:
#coding:utf-8
from selenium import webdriver
import re#导入re模块
driver=webdriver.Firefox()
driver.maximize_window()
driver.implicitly_wait(8)
driver.get("http://home.baidu.com/contact.html")
doc=driver.page_source#获取网页所有的内容
emails=re.findall(r'[\w]+@[\w\.-]+',doc)#邮箱的正则表达式
for email in list(set(emails)):#去掉重复的邮箱
print email
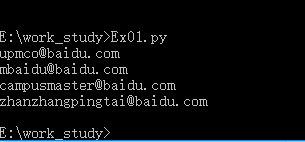
2. 测试结果如下图1所示
最新文章
- 64位主机64位oracle下装32位客户端ODAC(NFPACS版)
- SSH整合(struts2.3.24+hibernate3.6.10+spring4.3.2+mysql5.5+myeclipse8.5+tomcat6+jdk1.6)
- 烂泥:nginx负载均衡
- 【BZOJ 1036】【ZJOI 2008】树的统计 树链剖分模板题
- 【ubuntu】首选项和应用程序命令(preference & application)
- SqlServer参数化脚本与自动参数化(简单参数化)
- web.xml配置文件 taglib
- 动态的 css——less
- 081、Weave Scope 多主机监控(2019-04-29 周一)
- 《DOM Scripting》学习笔记-——第五章、第六章 案列改进
- leetcode python 001
- Java基础 之软引用、弱引用、虚引用 ·[转载]
- 洛咕 P4528 [CTSC2008]图腾
- 「转」图像算法---白平衡AWB
- msyqld 的 The user specified as a definer ('root'@'%') does not exist 问题
- 如何用istio实现应用的灰度发布
- 斯坦福大学Andrew Ng - 机器学习笔记(8) -- 推荐系统 & 大规模机器学习 & 图片文字识别
- mysql数据库备份脚本
- 洛谷P2762 太空飞行计划问题(最小割)
- CLR内存回收总结,代龄机制