使用Cloudera Manager搭建MapReduce集群及MapReduce HA
使用Cloudera Manager搭建MapReduce集群及MapReduce HA
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.通过CM部署MapReduce On YARN
1>.进入安装服务向导

2>.选择咱们要安装的服务MR
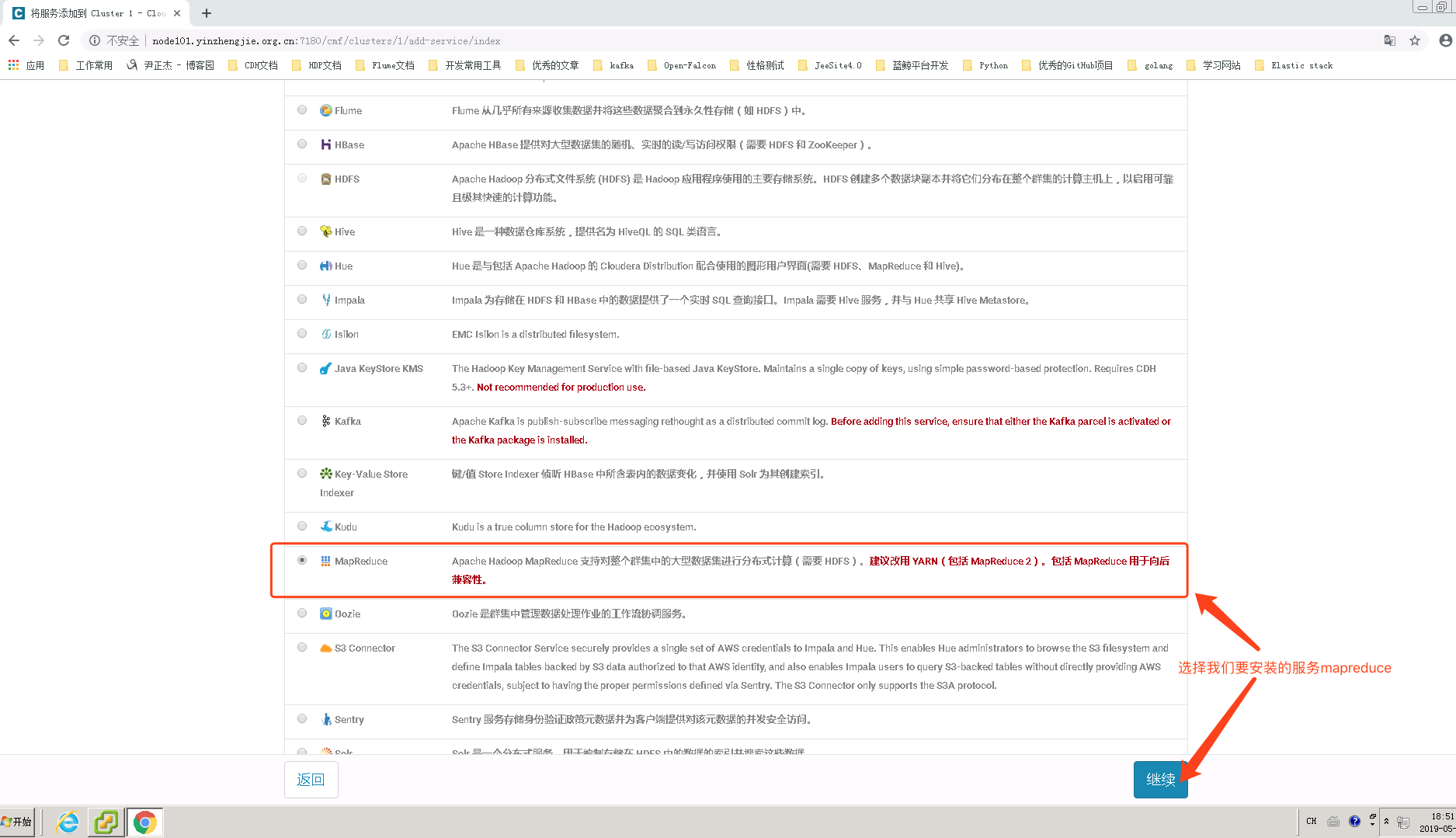
3>.为MR分配角色

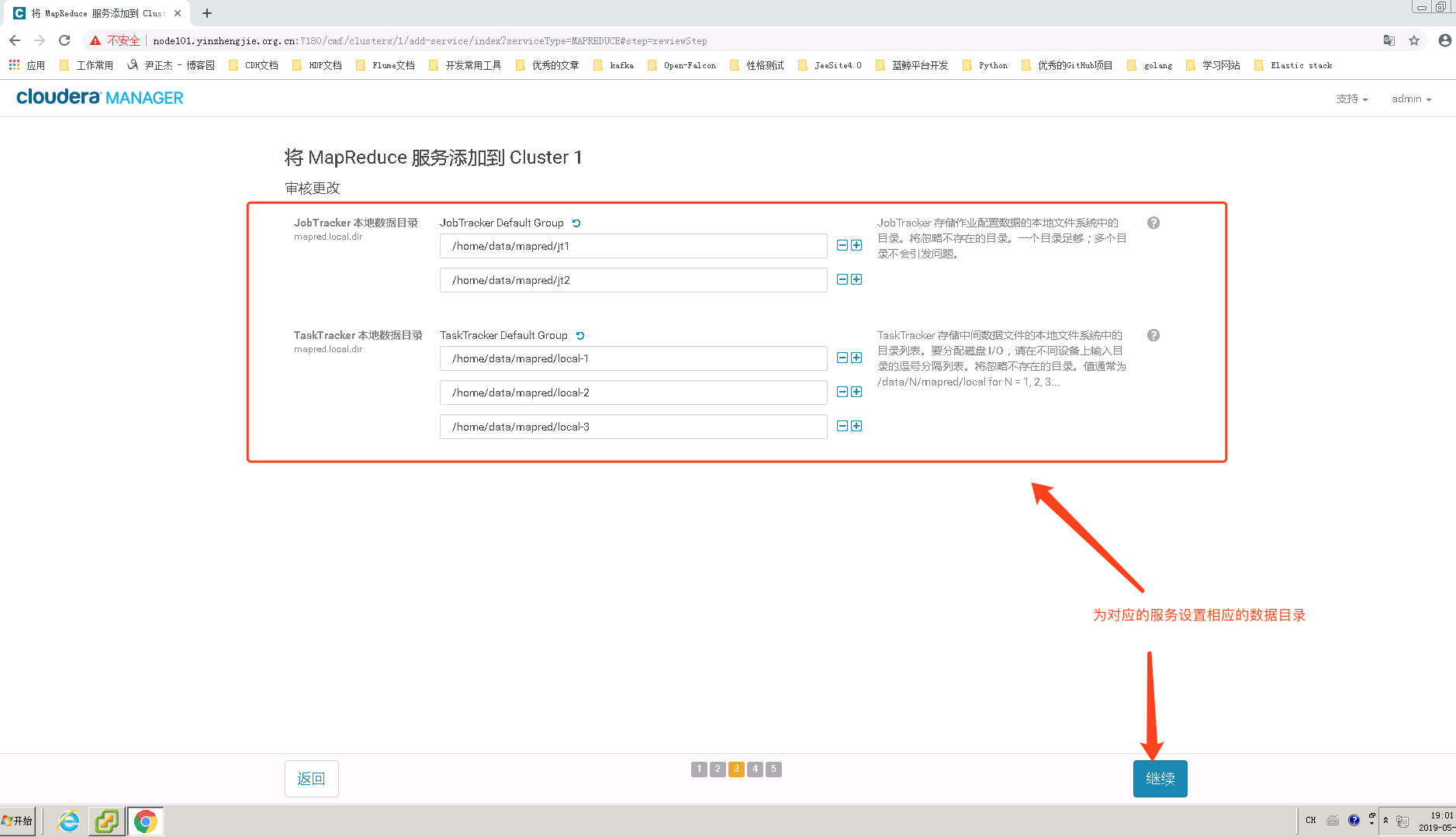
4>.配置MapReduce存储数据的目录
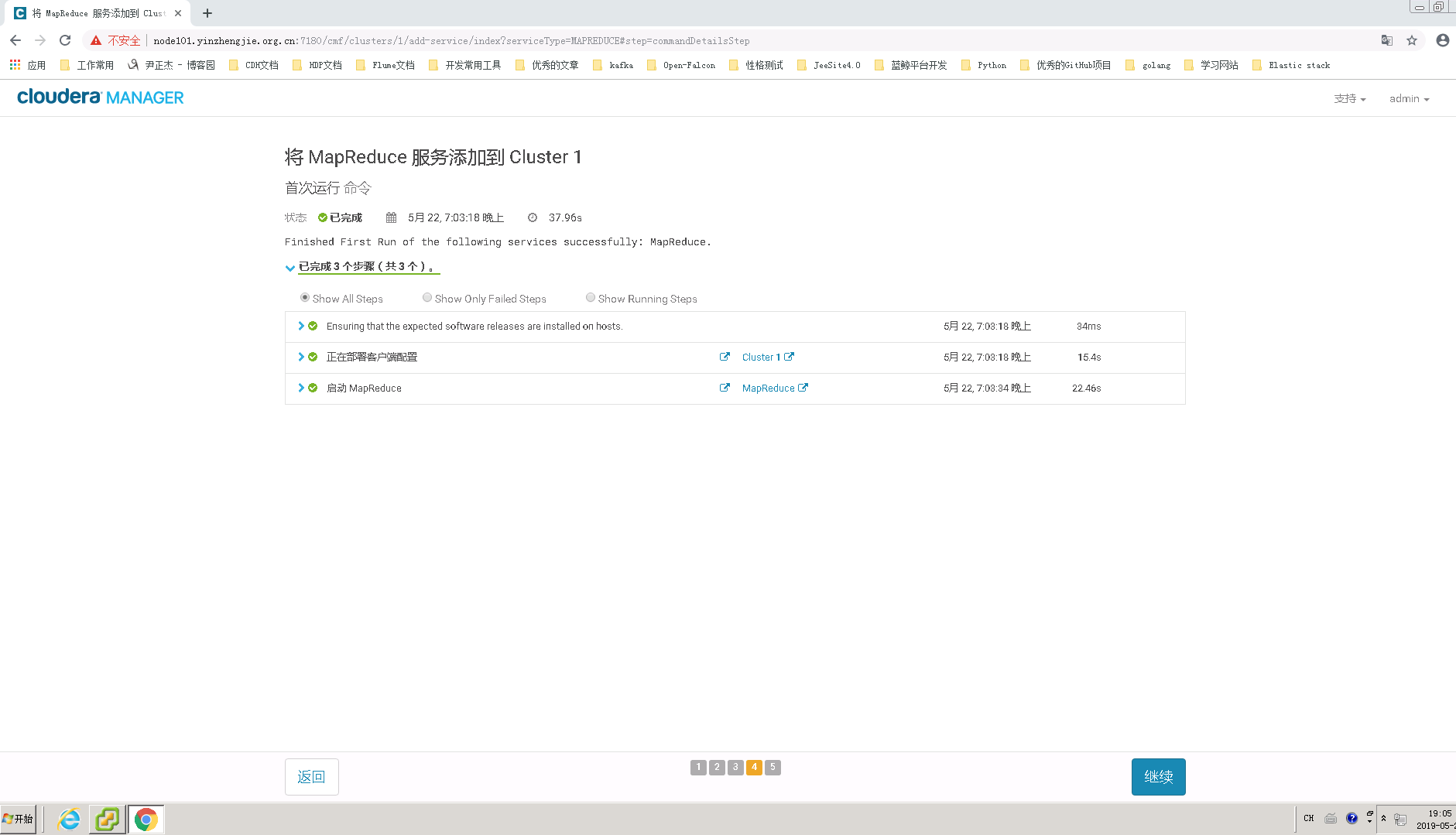
5>.等待MapReduce部署完成
6>.MapReduce服务成功加入到现有集群

7>.查看CM管理界面,多出来了一个MapReduce服务

二.使用Cloudera Manager配置MapReduce HA
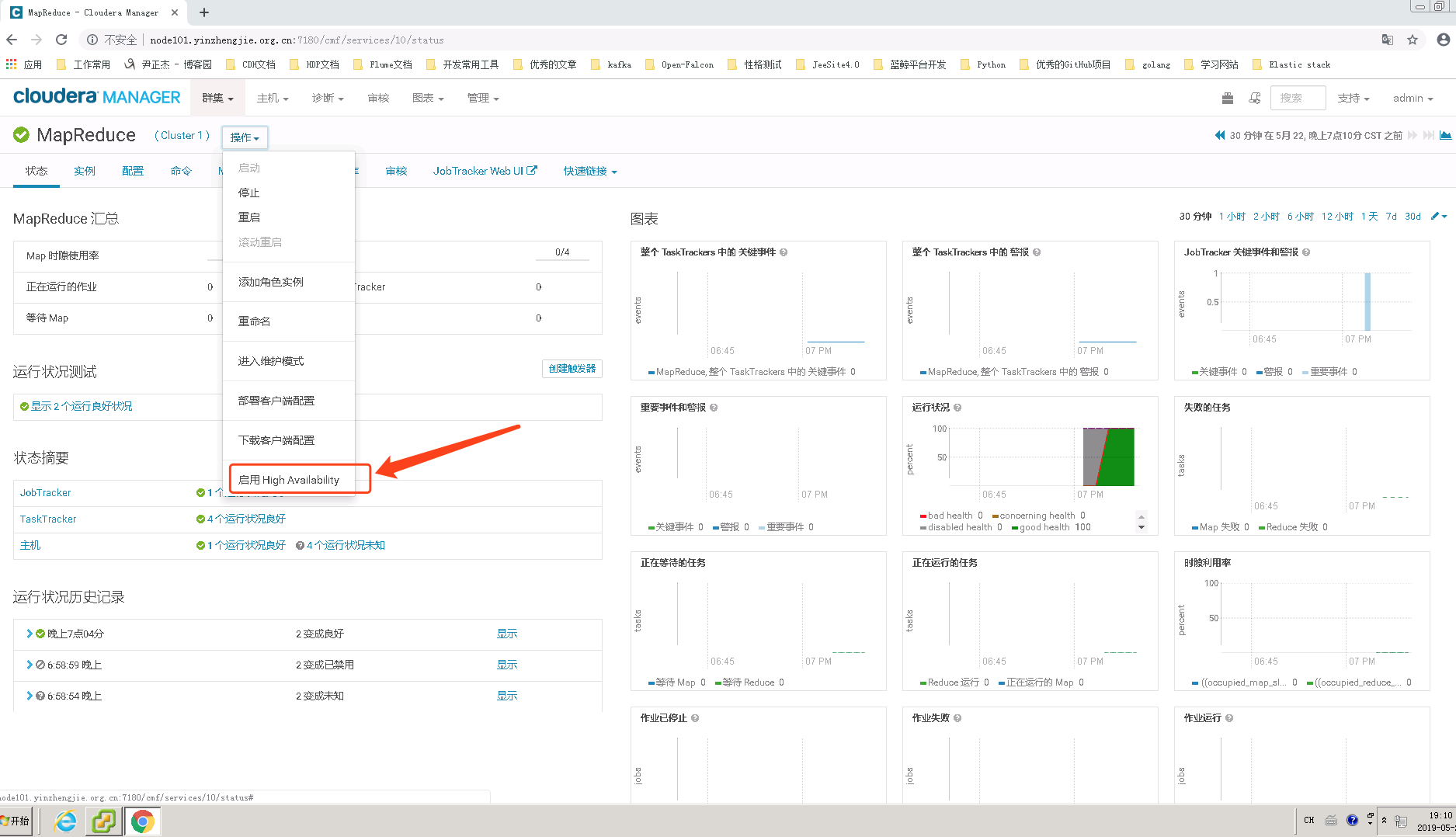
1>.点击“启用 High Avarilablity”
2>.选择备用的JobTracker 主机
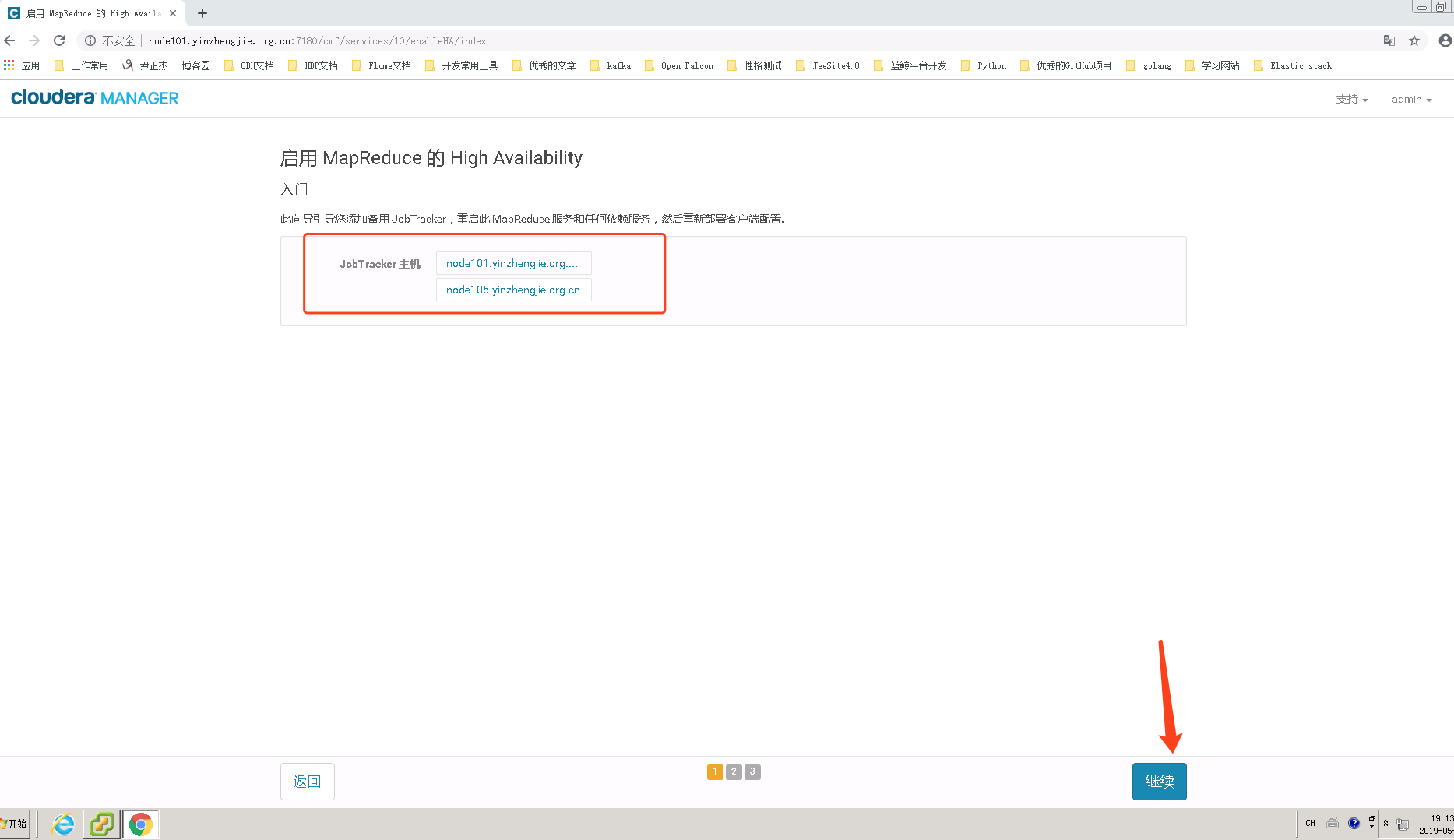
3>.配置MapReduce的数据存放路径
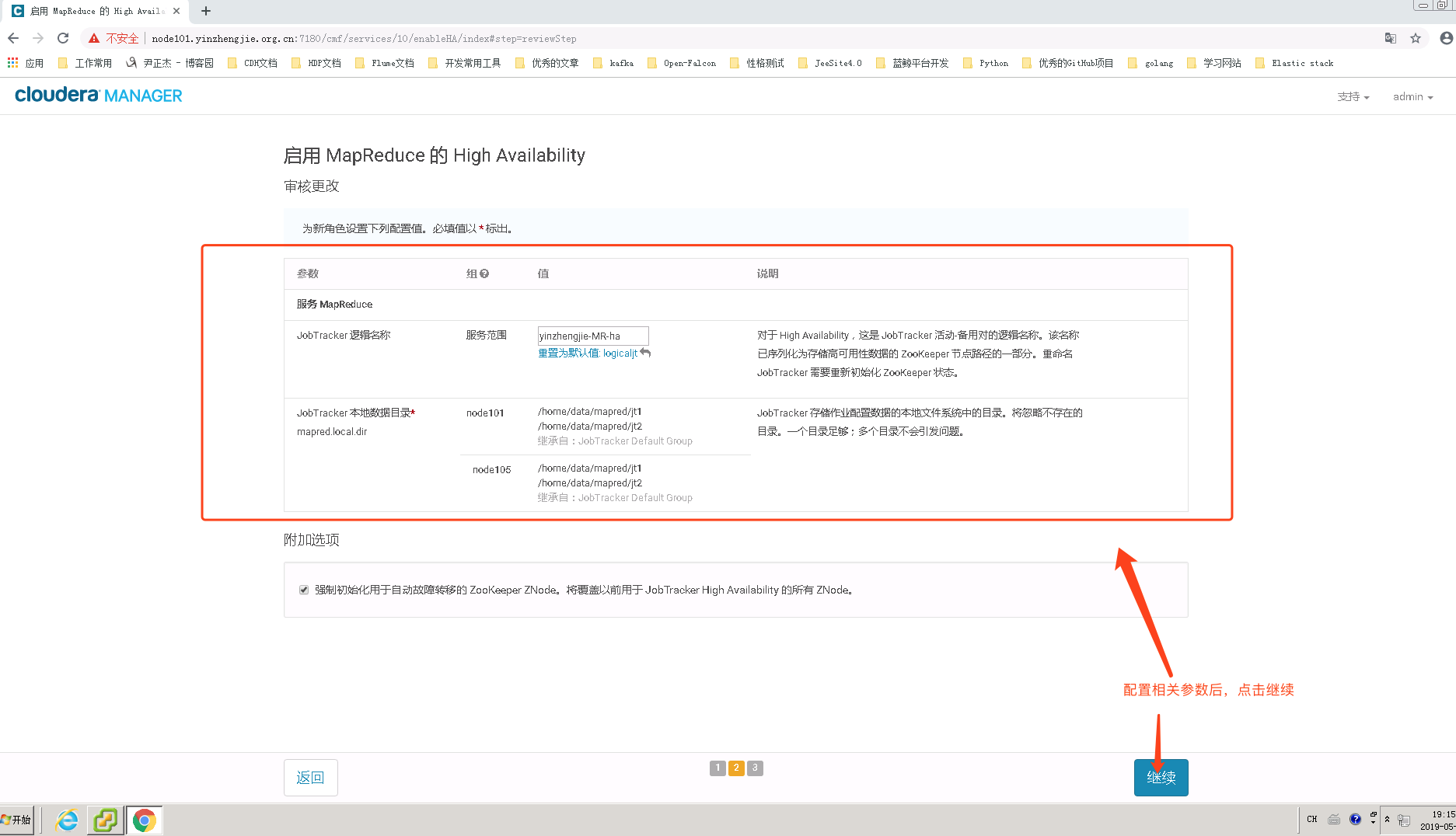
4>.等待MapReduce HA配置完成

5>.查明MapReduce的管理界面
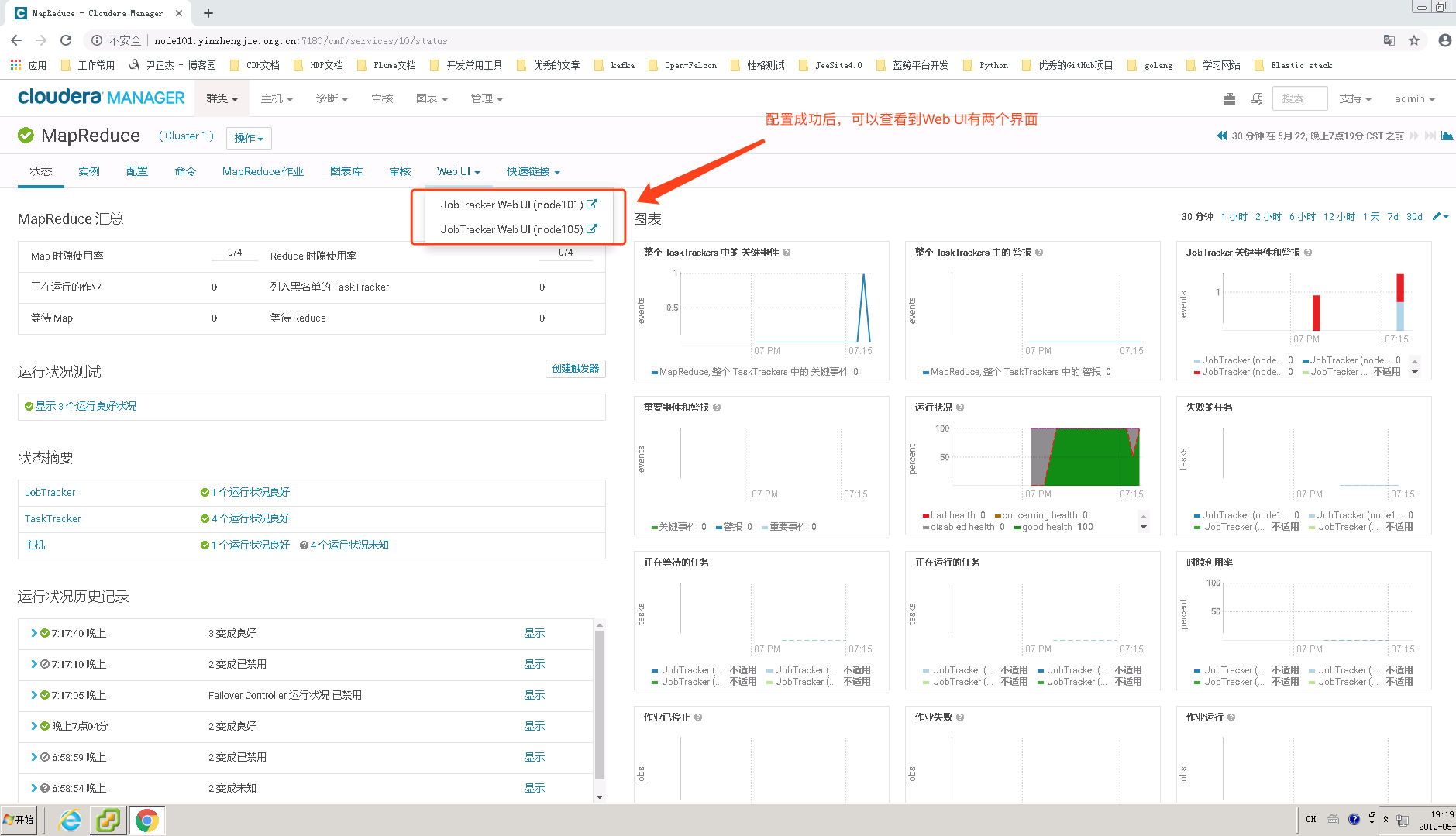
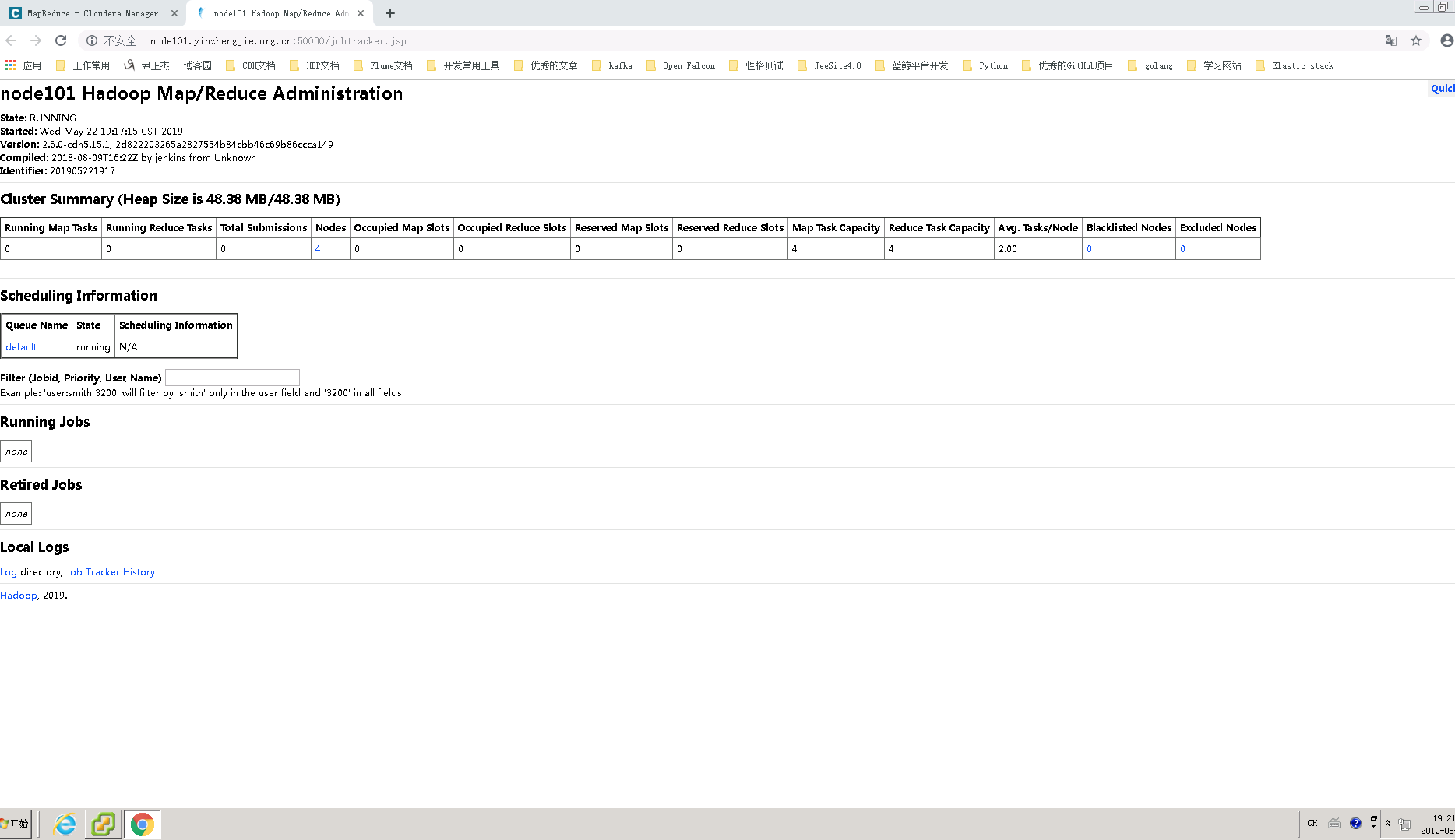
6>.查看node101.yinzhengjie.org.cn的JobTracker Web UI(我发现访问node105.yinzhengjie.org.cn会自动给我跳转到node101.yinzhengjie.org.cn的Web UI)
三.运行一个MapReduce程序
描述:
公司一个运维人员尝试优化集群,但反而使得一些以前可以运行的MapReduce作业不能运行了。请你识别问题并予以纠正,并成功运行性能测试,要求为在Linux文件系统上找到hadoop-mapreduce-examples.jar包,并使用它完成三步测试:
>.使用teragen /user/yinzhengjie/data/day001/test_input 生成10000000行测试记录并输出到指定目录
>.使用terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output 进行排序并输出到指定目录
>.使用teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate检查输出结果 考点:
属于Test类操作,见Benchmark the cluster (I/O, CPU,network)条目。并且包含Troubleshoot类的知识,需要对MapReduce作业的常见错误会排查。
1>.生成输入数据
[root@node101.yinzhengjie.org.cn ~]# find / -name hadoop-mapreduce-examples.jar
/opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# cd /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen 10000000 /user/yinzhengjie/data/day001/test_input
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen 10000000 /user/yinzhengjie/data/day001/test_input
19/05/22 19:38:39 INFO terasort.TeraGen: Generating 10000000 using 2
19/05/22 19:38:39 INFO mapreduce.JobSubmitter: number of splits:2
19/05/22 19:38:39 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0001
19/05/22 19:38:39 INFO impl.YarnClientImpl: Submitted application application_1558520562958_0001
19/05/22 19:38:40 INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0001/
19/05/22 19:38:40 INFO mapreduce.Job: Running job: job_1558520562958_0001
19/05/22 19:38:47 INFO mapreduce.Job: Job job_1558520562958_0001 running in uber mode : false
19/05/22 19:38:47 INFO mapreduce.Job: map 0% reduce 0%
19/05/22 19:39:05 INFO mapreduce.Job: map 72% reduce 0%
19/05/22 19:39:10 INFO mapreduce.Job: map 100% reduce 0%
19/05/22 19:39:10 INFO mapreduce.Job: Job job_1558520562958_0001 completed successfully
19/05/22 19:39:10 INFO mapreduce.Job: Counters: 31
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=309374
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=167
HDFS: Number of bytes written=1000000000
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Job Counters
Launched map tasks=2
Other local map tasks=2
Total time spent by all maps in occupied slots (ms)=40283
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=40283
Total vcore-milliseconds taken by all map tasks=40283
Total megabyte-milliseconds taken by all map tasks=41249792
Map-Reduce Framework
Map input records=10000000
Map output records=10000000
Input split bytes=167
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=163
CPU time spent (ms)=29850
Physical memory (bytes) snapshot=722341888
Virtual memory (bytes) snapshot=5678460928
Total committed heap usage (bytes)=552599552
org.apache.hadoop.examples.terasort.TeraGen$Counters
CHECKSUM=21472776955442690
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=1000000000
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen 10000000 /user/yinzhengjie/data/day001/test_input
2>.排序和输出
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# pwd
/opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output
19/05/22 19:41:16 INFO terasort.TeraSort: starting
19/05/22 19:41:17 INFO input.FileInputFormat: Total input paths to process : 2
Spent 151ms computing base-splits.
Spent 3ms computing TeraScheduler splits.
Computing input splits took 155ms
Sampling 8 splits of 8
Making 16 from 100000 sampled records
Computing parititions took 1019ms
Spent 1178ms computing partitions.
19/05/22 19:41:19 INFO mapreduce.JobSubmitter: number of splits:8
19/05/22 19:41:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0002
19/05/22 19:41:19 INFO impl.YarnClientImpl: Submitted application application_1558520562958_0002
19/05/22 19:41:19 INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0002/
19/05/22 19:41:19 INFO mapreduce.Job: Running job: job_1558520562958_0002
19/05/22 19:41:26 INFO mapreduce.Job: Job job_1558520562958_0002 running in uber mode : false
19/05/22 19:41:26 INFO mapreduce.Job: map 0% reduce 0%
19/05/22 19:41:36 INFO mapreduce.Job: map 25% reduce 0%
19/05/22 19:41:38 INFO mapreduce.Job: map 38% reduce 0%
19/05/22 19:41:43 INFO mapreduce.Job: map 63% reduce 0%
19/05/22 19:41:47 INFO mapreduce.Job: map 75% reduce 0%
19/05/22 19:41:51 INFO mapreduce.Job: map 88% reduce 0%
19/05/22 19:41:52 INFO mapreduce.Job: map 100% reduce 0%
19/05/22 19:41:58 INFO mapreduce.Job: map 100% reduce 19%
19/05/22 19:42:04 INFO mapreduce.Job: map 100% reduce 38%
19/05/22 19:42:09 INFO mapreduce.Job: map 100% reduce 50%
19/05/22 19:42:10 INFO mapreduce.Job: map 100% reduce 56%
19/05/22 19:42:15 INFO mapreduce.Job: map 100% reduce 69%
19/05/22 19:42:17 INFO mapreduce.Job: map 100% reduce 75%
19/05/22 19:42:19 INFO mapreduce.Job: map 100% reduce 81%
19/05/22 19:42:21 INFO mapreduce.Job: map 100% reduce 88%
19/05/22 19:42:22 INFO mapreduce.Job: map 100% reduce 94%
19/05/22 19:42:25 INFO mapreduce.Job: map 100% reduce 100%
19/05/22 19:42:25 INFO mapreduce.Job: Job job_1558520562958_0002 completed successfully
19/05/22 19:42:25 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=439892507
FILE: Number of bytes written=880566708
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1000001152
HDFS: Number of bytes written=1000000000
HDFS: Number of read operations=72
HDFS: Number of large read operations=0
HDFS: Number of write operations=32
Job Counters
Launched map tasks=8
Launched reduce tasks=16
Data-local map tasks=6
Rack-local map tasks=2
Total time spent by all maps in occupied slots (ms)=60036
Total time spent by all reduces in occupied slots (ms)=69783
Total time spent by all map tasks (ms)=60036
Total time spent by all reduce tasks (ms)=69783
Total vcore-milliseconds taken by all map tasks=60036
Total vcore-milliseconds taken by all reduce tasks=69783
Total megabyte-milliseconds taken by all map tasks=61476864
Total megabyte-milliseconds taken by all reduce tasks=71457792
Map-Reduce Framework
Map input records=10000000
Map output records=10000000
Map output bytes=1020000000
Map output materialized bytes=436922411
Input split bytes=1152
Combine input records=0
Combine output records=0
Reduce input groups=10000000
Reduce shuffle bytes=436922411
Reduce input records=10000000
Reduce output records=10000000
Spilled Records=20000000
Shuffled Maps =128
Failed Shuffles=0
Merged Map outputs=128
GC time elapsed (ms)=2054
CPU time spent (ms)=126560
Physical memory (bytes) snapshot=7872991232
Virtual memory (bytes) snapshot=68271607808
Total committed heap usage (bytes)=6595018752
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1000000000
File Output Format Counters
Bytes Written=1000000000
19/05/22 19:42:25 INFO terasort.TeraSort: done
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
Found items
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_input
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_output
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_input
Found items
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/_SUCCESS
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/part-m-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/part-m-
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_input
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_output
Found items
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/_SUCCESS
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/_partition.lst
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_output
3>.验证输出
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# pwd
/opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate
// :: INFO input.FileInputFormat: Total input paths to process :
Spent 29ms computing base-splits.
Spent 3ms computing TeraScheduler splits.
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0003
// :: INFO impl.YarnClientImpl: Submitted application application_1558520562958_0003
// :: INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0003/
// :: INFO mapreduce.Job: Running job: job_1558520562958_0003
// :: INFO mapreduce.Job: Job job_1558520562958_0003 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1558520562958_0003 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Rack-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
Found items
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_input
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_output
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/ts_validate
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/ts_validate
Found items
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/ts_validate/_SUCCESS
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/ts_validate/part-r-
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/ts_validate
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -cat /user/yinzhengjie/data/day001/ts_validate/part-r-
checksum 4c49607ac53602
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -cat /user/yinzhengjie/data/day001/ts_validate/part-r-00000
最新文章
- Hibernate中的锁机制
- Oracle索引梳理系列(十)- 直方图使用技巧及analyze table操作对直方图统计的影响(谨慎使用)
- 【转】C# 中 10 个你真的应该学习(和使用!)的功能
- 转:Delphi 6 实用函数
- struts2所有组件
- CSS基础-插曲
- DW(一):大数据DW架构参考
- 图片懒加载 lazyload
- 一个简单的有向图Java实现
- cocoapods_第二篇
- new关键字在虚方法的动态调用中的阻断作用
- Shell使用
- POJ 3678 Katu Puzzle(2 - SAT) - from lanshui_Yang
- crawler_爬虫_反爬虫策略
- 用GDB调试程序
- Java简单实用方法一
- 【洛谷1541】【CJOJ1087】【NOIP2010】乌龟棋
- Httpclient代码
- iOS数据存储-钥匙串存储
- ProcessHacker可编译版本