Caffe深入分析(源码)
Caffe的整体流程图:
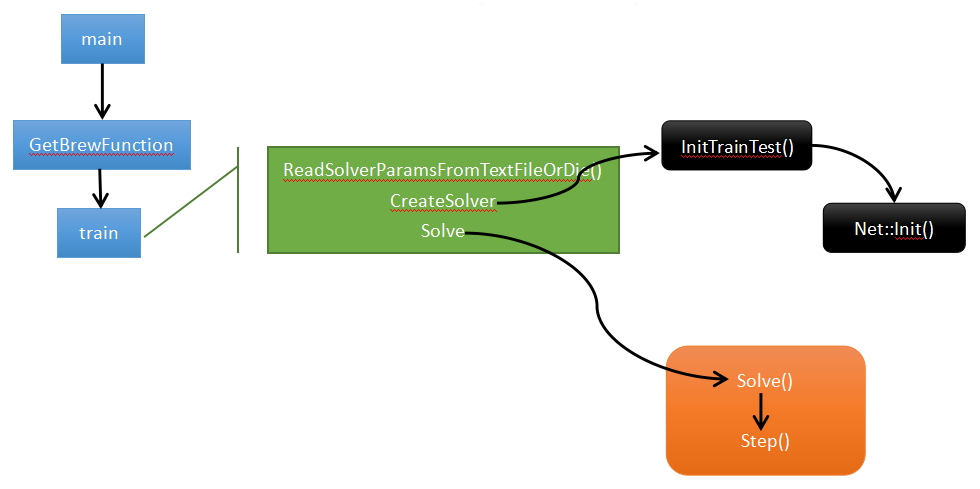
程序入口:main()
int main(int argc, char** argv) {
.....
return GetBrewFunction(caffe::string(argv[]))();
....
}
g_brew_map实现过程,首先通过 typedef定义函数指针 typedef int (*BrewFunction)(); 这个是用typedef定义函数指针方法。这个程序定义一个BrewFunction函数指针类型,在caffe.cpp 中 BrewFunction 作为GetBrewFunction()函数的返回类型,可以是 train(),test(),device_query(),time() 这四个函数指针的其中一个。在train(),test(),中可以调用solver类的函数,从而进入到net,进入到每一层,运行整个caffe程序。然后对每个函数注册。
RegisterBrewFunction(train)
RegisterBrewFunction(test)
RegisterBrewFunction(device_query)
RegisterBrewFunction(time)
- train: 训练或者调整一个模型
- test : 在测试集上测试一个模型
- device_query : 打印GPU的调试信息
- time: 压测一个模型的执行时间
如果需要,可以增加其他的方式,然后通过RegisterBrewFunction()函数注册一下即可。
接着调用train()函数,train函数中主要有三个方法ReadSolverParamsFromTextFileOrDie、CreateSolver、Solve。
// Train / Finetune a model.
int train() {
......
caffe::SolverParameter solver_param;
caffe::ReadSolverParamsFromTextFileOrDie(FLAGS_solver, &solver_param);//从-solver参数读取solver_param
......
shared_ptr<caffe::Solver<float> >
solver(caffe::SolverRegistry<float>::CreateSolver(solver_param));//从参数创建solver,同样采用string到函数指针的映射实现,用到了工厂模式 if (FLAGS_snapshot.size()) {//迭代snapshot次后保存模型一次
LOG(INFO) << "Resuming from " << FLAGS_snapshot;
solver->Restore(FLAGS_snapshot.c_str());
} else if (FLAGS_weights.size()) {//若采用finetuning,则拷贝weight到指定模型
CopyLayers(solver.get(), FLAGS_weights);
} if (gpus.size() > ) {
caffe::P2PSync<float> sync(solver, NULL, solver->param());
sync.Run(gpus);
} else {
LOG(INFO) << "Starting Optimization";
solver->Solve();//开始训练网络
}
LOG(INFO) << "Optimization Done.";
return ;
}
ReadSolverParamsFromTextFileOrDie
caffe::ReadSolverParamsFromTextFileOrDie(FLAGS_solver, &solver_param)解析-solver指定的solver.prototxt的文件内容到solver_param中
CreateSolver
CreateSolver函数构建solver和net,该函数是初始化的入口,会通过执行Solver的构造函数,调用 void Solver<Dtype>::Init(const SolverParameter& param),该函数内有InitTrainNet()、InitTestNets()。对于InitTrainNet函数:
......
net_.reset(new Net<Dtype>(net_param));
调用Net类的构造函数,然后执行Init()操作,该函数具体的内容如下图和源码所示:
template <typename Dtype>
void Net<Dtype>::Init(const NetParameter& in_param) {
........//过滤校验参数FilterNet
FilterNet(in_param, &filtered_param);
.........//插入Splits层
InsertSplits(filtered_param, ¶m);
.......// 构建网络中输入输出存储结构
bottom_vecs_.resize(param.layer_size());
top_vecs_.resize(param.layer_size());
bottom_id_vecs_.resize(param.layer_size());
param_id_vecs_.resize(param.layer_size());
top_id_vecs_.resize(param.layer_size());
bottom_need_backward_.resize(param.layer_size()); for (int layer_id = ; layer_id < param.layer_size(); ++layer_id) {
...//创建层
layers_.push_back(LayerRegistry<Dtype>::CreateLayer(layer_param));
layer_names_.push_back(layer_param.name());
LOG_IF(INFO, Caffe::root_solver())
<< "Creating Layer " << layer_param.name();
bool need_backward = false; // Figure out this layer's input and output
for (int bottom_id = ; bottom_id < layer_param.bottom_size();
++bottom_id) {
const int blob_id = AppendBottom(param, layer_id, bottom_id,
&available_blobs, &blob_name_to_idx); ........//创建相关blob
// If the layer specifies that AutoTopBlobs() -> true and the LayerParameter
// specified fewer than the required number (as specified by
// ExactNumTopBlobs() or MinTopBlobs()), allocate them here.
Layer<Dtype>* layer = layers_[layer_id].get();
if (layer->AutoTopBlobs()) {
const int needed_num_top =
std::max(layer->MinTopBlobs(), layer->ExactNumTopBlobs());
for (; num_top < needed_num_top; ++num_top) {
// Add "anonymous" top blobs -- do not modify available_blobs or
// blob_name_to_idx as we don't want these blobs to be usable as input
// to other layers.
AppendTop(param, layer_id, num_top, NULL, NULL);
}
} .....//执行SetUp()
// After this layer is connected, set it up.
layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);
LOG_IF(INFO, Caffe::root_solver())
<< "Setting up " << layer_names_[layer_id];
for (int top_id = ; top_id < top_vecs_[layer_id].size(); ++top_id) {
if (blob_loss_weights_.size() <= top_id_vecs_[layer_id][top_id]) {
blob_loss_weights_.resize(top_id_vecs_[layer_id][top_id] + , Dtype());
}
blob_loss_weights_[top_id_vecs_[layer_id][top_id]] = layer->loss(top_id);
LOG_IF(INFO, Caffe::root_solver())
<< "Top shape: " << top_vecs_[layer_id][top_id]->shape_string();
if (layer->loss(top_id)) {
LOG_IF(INFO, Caffe::root_solver())
<< " with loss weight " << layer->loss(top_id);
}
memory_used_ += top_vecs_[layer_id][top_id]->count();
}
LOG_IF(INFO, Caffe::root_solver())
<< "Memory required for data: " << memory_used_ * sizeof(Dtype);
const int param_size = layer_param.param_size();
const int num_param_blobs = layers_[layer_id]->blobs().size();
CHECK_LE(param_size, num_param_blobs)
<< "Too many params specified for layer " <<
Net::Init()
SetUp是怎么构建的呢?
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {} void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
InitMutex();
CheckBlobCounts(bottom, top);
LayerSetUp(bottom, top);
Reshape(bottom, top);
SetLossWeights(top);
}
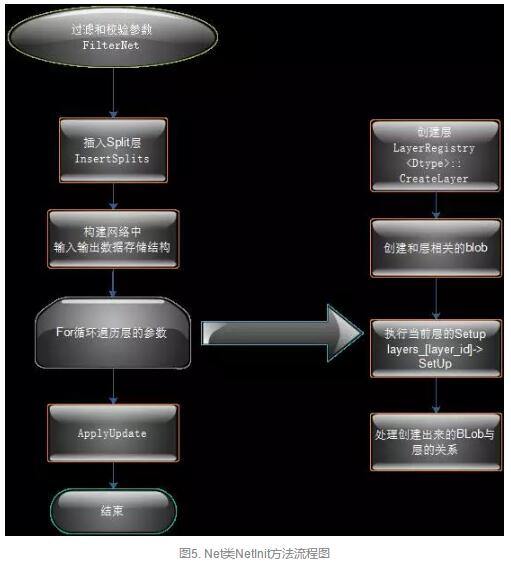
初始化的总体流程大概就是新建一个Solver对象,然后调用Solver类的构造函数,然后在Solver的构造函数中又会新建Net类实例,在Net类的构造函数中又会新建各个layer的实例,一直具体到设置每个Blob,大概就完成了网络初始化的工作了。
Solve
train函数中CreateSolver()执行完成后,接下来是具体训练过程,执行Solve()函数---->Step()--->结束
Solve的具体内容和代码:
template <typename Dtype>
void Solver<Dtype>::Solve(const char* resume_file) {
CHECK(Caffe::root_solver());
LOG(INFO) << "Solving " << net_->name();
LOG(INFO) << "Learning Rate Policy: " << param_.lr_policy(); // For a network that is trained by the solver, no bottom or top vecs
// should be given, and we will just provide dummy vecs.
int start_iter = iter_;
Step(param_.max_iter() - iter_); // overridden by setting snapshot_after_train := false
if (param_.snapshot_after_train()
&& (!param_.snapshot() || iter_ % param_.snapshot() != )) {
Snapshot();
} // display loss
if (param_.display() && iter_ % param_.display() == ) {
int average_loss = this->param_.average_loss();
Dtype loss;
net_->Forward(&loss); UpdateSmoothedLoss(loss, start_iter, average_loss); if (param_.test_interval() && iter_ % param_.test_interval() == ) {
TestAll();
}
}

然后开始执行Step函数,具体内容和代码:
template <typename Dtype>
void Solver<Dtype>::Step(int iters)
{
// 起始迭代步数
const int start_iter = iter_;
// 终止迭代步数
const int stop_iter = iter_ + iters; // 判断是否已经完成设定步数
while (iter_ < stop_iter)
{
// 将net_中的Bolb梯度参数置为零
net_->ClearParamDiffs(); ... // accumulate the loss and gradient
Dtype loss = ;
for (int i = ; i < param_.iter_size(); ++i)
{
// 正向传导和反向传导,并计算loss
loss += net_->ForwardBackward();
}
loss /= param_.iter_size(); // 为了输出结果平滑,将临近的average_loss个loss数值进行平均,存储在成员变量smoothed_loss_中
UpdateSmoothedLoss(loss, start_iter, average_loss); // BP算法更新权重
ApplyUpdate(); // Increment the internal iter_ counter -- its value should always indicate
// the number of times the weights have been updated.
++iter_;
}
}
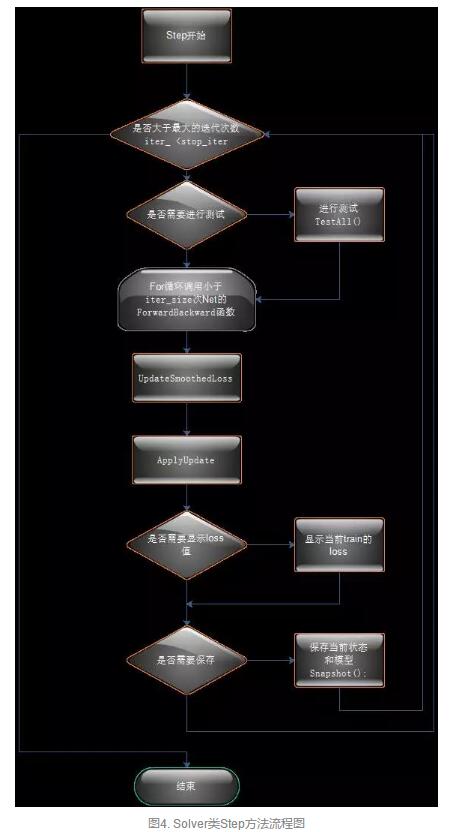
while循环中先调用了网络类Net::ForwardBackward()成员函数进行正向传导和反向传导,并计算loss
Dtype ForwardBackward() {
Dtype loss;
//正向传导
Forward(&loss);
//反向传导
Backward();
return loss;
}
而Fordward函数中调用了ForwardFromTo,而FordwardFromTo又调用了每个layer的Fordward。反向传导函数Backward()调用了BackwardFromTo(int start, int end)函数。正向传导和反向传导结束后,再调用SGDSolver::ApplyUpdate()成员函数进行权重更新。
- ForwardBackward:按顺序调用了Forward和Backward。
- ForwardFromTo(int start, int end):执行从start层到end层的前向传递,采用简单的for循环调用。,forward只要计算损失loss
- BackwardFromTo(int start, int end):和前面的ForwardFromTo函数类似,调用从start层到end层的反向传递。backward主要根据loss来计算梯度,caffe通过自动求导并反向组合每一层的梯度来计算整个网络的梯度。
- ToProto函数完成网络的序列化到文件,循环调用了每个层的ToProto函数
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate()
{
// 获取当前学习速率
Dtype rate = GetLearningRate();
if (this->param_.display() && this->iter_ % this->param_.display() == )
{
LOG(INFO) << "Iteration " << this->iter_ << ", lr = " << rate;
} // 在计算当前梯度的时候,如果该值超过了阈值clip_gradients,则将梯度直接设置为该阈值
// 此处阈值设为-1,即不起作用
ClipGradients(); // 逐层更新网络中的可学习层
for (int param_id = ; param_id < this->net_->learnable_params().size();
++param_id)
{
// 归一化
Normalize(param_id);
// L2范数正则化添加衰减权重
Regularize(param_id);
// 随机梯度下降法计算更新值
ComputeUpdateValue(param_id, rate);
}
// 更新权重
this->net_->Update();
}
ApplyUpdate
最后将迭代次数++iter_,继续while循环,直到迭代次数完成。 这就是整个网络的训练过程。
最新文章
- ExtJS in Review - xtype vs. alias
- SAP 订单状态跟踪
- XV Open Cup named after E.V. Pankratiev. GP of Tatarstan
- 升级Xcode8控制台打印出来这些东西
- 根据不同的实体及其ID来获取数据库中的数据
- ASP.NET 4.0 取消表单危险字符验证
- 切身体验苹果Reminders的贴心设计
- SQL SERVER 移动系统数据库
- 【转载】div层调整zindex属性无效原因分析及解决方法
- sc7731 Android 5.1 LCD驱动简明笔记之二
- Windows 窗体的.Net 框架绘图技术
- Linux cat和EOF的使用
- List(双向链表)
- 插件式Web框架
- 先对数组排序,在进行折半查找(C++)
- libmad编译
- 如何让.Net线程支持超时后并自动销毁!
- HBase学习——4.HBase过滤器
- logstash 修改配置不重启的方法
- python nose 自写插件支持用例带进度