hadoop进阶---hadoop性能优化(一)---hdfs空间不足的管理优化
Hadoop 空间不足,hive首先就会没法跑了,进度始终是0%。
将HDFS备份数降低
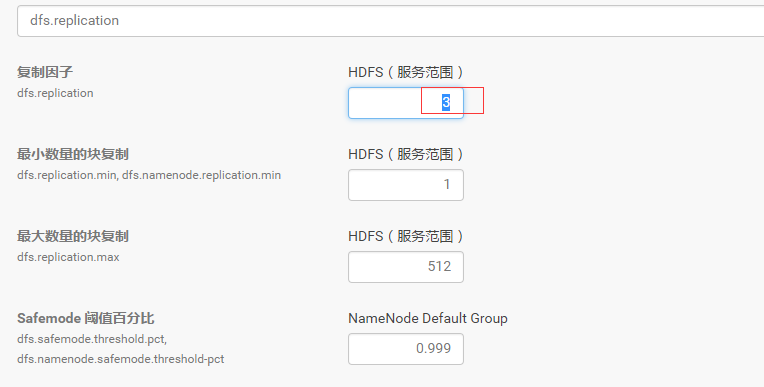
将默认的备份数3设置为2。
步骤:CDH–>HDFS–>配置–>搜索dfs.replication–>设置为2
删除无用HDFS数据和Hbase表格
主要使用命令hadoop fs -du,hadoop fs -ls,hadoop fs -rm
空间不足根本的解决办法自然是清理空间。但是清理空间也要有步骤。
检查总体情况
hadoop dfsadmin -report
检查每个目录
hdfs dfs -du-h/
删除表
先清理数据表,去hive,impala里删除表
进入hive shell;
使用命令
droptable tablename;
清理完表之后,删除文件
使用命令
hadoop fs -rm -skipTrash filename;
hadoop fs -rmr -skipTrash directoryname;
删除的时候要注意使用-skipTrash选项,否则不会马上删除,而是转到垃圾桶了
删除本机linux无用文件
使用命令找出大于1G的文件看看哪些是可以删除的
M -execls -lh {} \;
清理Trash回收站
使用命令
hadoop fs -rmr-skipTrash /user/root/.Trash;
或者
hdfs dfs -expunge ;
执行完-expunge命令后,回收站的数据不会立即被清理,而是先打了一个checkpoint。显示的是一分钟后清除。
实际验证,11T的数据需要好几分钟…..
和Linux系统的回收站设计一样,HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户通过Shell删除的文件/目录,在系统回收站中都一个周期,也就是当系统回收站中的文件/目录在一段时间之后没有被用户回复的话,HDFS就会自动的把这个文件/目录彻底删除,之后,用户就永远也找不回这个文件/目录了。在HDFS内部的具体实现就是在NameNode中开启了一个后台线程Emptier,这个线程专门管理和监控系统回收站下面的所有文件/目录,对于已经超过生命周期的文件/目录,这个线程就会自动的删除它们,不过这个管理的粒度很大。另外,用户也可以手动清空回收站,清空回收站的操作和删除普通的文件目录是一样的,只不过HDFS会自动检测这个文件目录是不是回收站,如果是,HDFS当然不会再把它放入用户的回收站中了
根据上面的介绍,用户通过命令行即HDFS的shell命令删除某个文件,这个文件并没有立刻从HDFS中删除。相反,HDFS将这个文件重命名,并转移到操作用户的回收站目录中(如/user/hdfs/.Trash/Current, 其中hdfs是操作的用户名)。如果用户的回收站中已经存在了用户当前删除的文件/目录,则HDFS会将这个当前被删除的文件/目录重命名,命名规则很简单就是在这个被删除的文件/目录名后面紧跟一个编号(从1开始知道没有重名为止)。
Balancer重新平衡
集群运行一段时间后各个节点的磁盘使用率可能会产生较大的差异,这时可以用balancer来重新平衡各个节点。
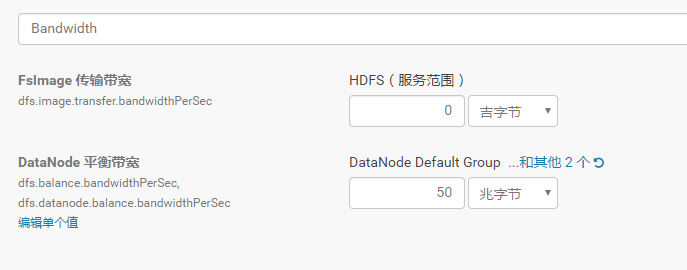
首先调大balancer的带宽这里设置为50MB。默认的带宽较小,防止占用太多资源。若需要快速平衡可以将带宽调为一个较大的值。
管理后台–HDFS—配置–搜索bandwidth
接着启动balancer。在管理后台中操作,步骤 hdfs-状态-操作-重新平衡
调整回收站的清理时间
Hadoop回收磁盘空间通过在core-site.xml进行设置实现。
在xml文档内添加:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description>Number of minutes between trash checkpoints. If zero, the trash feature is disabled. </description>
</property>
</code>
通过修改value的值来设定回收磁盘空间的时间间隔。如果value是0,默认是关闭此项功能的
调整自动清除回收站
HADOOP-HDFS需要有一个Auto-Emptier 线程来自动清除trash, 以释放HDFS的总使用空间, 该功能可以配置为可选项, 可以在Configuration下增加这两个参数以供配置.
fs.trash.autoemptier.interval 执行空间检查的时间时间隔, 设置为0时, 禁用该功能, 默认为20 Seconds.
fs.trash.max.percentused 当已使用空间率大于该值, 执行回收以释放空间. 默认为0.8f
调整kafka的日志时间
步骤:管理后台–>kafka–>配置–>搜索log.retention.hours–>设置为30天
调整hbase的TTL时间
设置TTL为2592000,30天
./hbase shellhbase> desc 'ns1:t1'hbase> disable 'ns1:t1'hbase> alter 'ns1:t1', {NAME => 'n1', TTL => '2592000'}, {NAME => 'n2', TTL => '2592000'}hbase> enable 'ns1:t1'
设置成功后,hbase自动将过期数据删除,进行合并region操作。磁盘空间得以释放。
最新文章
- xml对象的序列化和反序列化
- Mysql 插入部分字段问题
- NV OIT algorithm : Depth peeling is a fragment-level depth sorting technique
- 模块已加载,但对dllregisterServer的调用失败
- 关于OC队列
- POJ 2892 Tunnel Warfare || HDU 1540(树状数组+二分 || 线段树的单点更新+区间查询)
- 搭建maven项目简介
- 生成Token字符串
- web工程自动部署(tomcat服务器)
- 广州.NET微软技术俱乐部 - 动手实验室
- compose函数
- TF版本的Word2Vec和余弦相似度的计算
- xml文件以及解析
- 倍数|计蒜客2019蓝桥杯省赛 B 组模拟赛(一)
- java 正则例子
- 180713-Spring之借助Redis设计访问计数器之扩展篇
- 剑指offer-第五章优化时间和空间效率(把数组排列成最小的数)
- windows下修改Mysql5.7.11初始密码的图文教程
- 容器与容器编排实战系列 1 -- Docker 安装
- 想要学好C/C++,我到底要看多少书才能成为一个合格的C/C++工程师?