2.数码相框-编码(ASCII/GB2312/Unicode)介绍
转载:https://www.cnblogs.com/lifexy/p/8485634.html
本章主要内容如下:
- 1)熟悉ASCII/GB2312/Unicode编码
- 2)写应用程序,使LCD显示汉字和字符
大家都知道,数据传输的是二进制,而字符和汉字却有各种各样的,所以便通过二进制将字符和汉字编成一个字符集(charset).
1.而字符集(charset)又经历3个阶段
ASCII码
最早的计算机采用ASCII码,一个字节便包括了英文数字这些符号
GB2312编码
由于不支持中文,那时候的常用汉字就有6763个,所以中国人发明了GB2312(GB国标),汉字为2个字节,与ascll码兼容,后来又继续扩展汉字,所以又有了GBK编码.
GB2312编码是将字符进行一个分区处理,共有94个区,每个区有94个位,所以区位码范围为0000~9393
汉字分为了一级汉字(常用)和二级汉字(不常用).
其中GB2312分区表如下图所示:
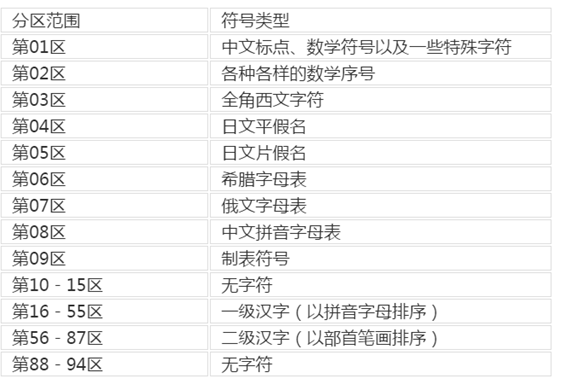
比如“啊”,位于第16区第1位,也就是1500.
然后分别在区和位上加0xA1,便转换为了GB2312编码(编码从0xA1A1开始是为了兼容英文字符,)
所以“啊”的GB2312编码为: 0xB0A1
15(区)+0xA1=0xB0
00(位)+0xA1=0xA1

这种编码方式仅仅在中国行的通,若去浏览繁体字或日文时,便会出现乱码,因为繁体字使用的是Big5编码,日文则需要安装日本的Shift_JIS 编码才行.
在不同的国家的编码标准都不同,所以在PC里,使用ANSI编码来代表它们,比如中文PC里,ANSI编码代表GBK编码.
Unicode编码(统一世界所有符号)
包括中、日、韩、英文等字符,格式有utf-32、utf-16、utf-8
在PC,Unicode一般代表utf-16,而utf-8是单独列出来的,
utf-32
指每个字符都采用4个字节(32位),缺点在于浪费空间,比如:a=0x0000 0061,啊=0x0000554A.
utf-16(错一个字节,则整个乱码)
每个字符的长度为2字节或4字节,常用的都是2字节(包括汉字等). 比如: a=0x0061,啊=0x554A.
utf-8(容错能力高)
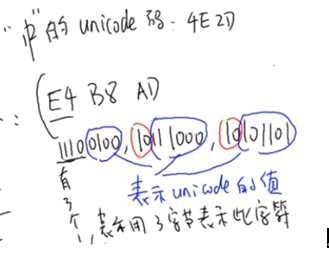
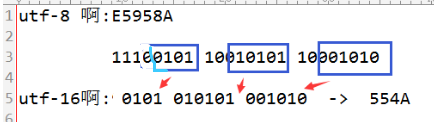
指每个字符的长度为1~4个字节,越常用的字符,字节越短,比如:a=0x61,啊=0xE5958A
可以通过utf-16转换过来,高4位表示有多少个字节,然后剩下的每个字节的高2位都为10(表示只有一个字节),剩下的值加起来就是utf-16编码,如下图所示:
如果是unicode转utf-8,则对应代码为:

int UnicodeToUtf8( unsigned short* src, unsigned short* putf8)
{
int len = 0;
while (*src)
{
if (*src < 0x80) //one byte
{
putf8[len++] = *src;
}
else if (*src < 0x800) //two byte
{
putf8[len++] = 0xC0 | (*src >> 6);
putf8[len++] = 0x80 | ((*src) & 0x3F);
}
else
{
putf8[len++] = 0xE0 | (*src >> 12); //获取src高4位
putf8[len++] = 0x80 | ((*src >> 6) & 0x3F); //获取src 第6位,长度为3f(6位)
putf8[len++] = 0x80 | (*src & 0x3F); //获取src低6位
}
src++;
}
putf8[len] = 0;
return len;
} int main()
{
unsigned short Unicode[2]={0x4e2d}; //中的unicode码 unsigned short utf[4]={0,0,0,0}; UnicodeToUtf8(Unicode,utf); for(int i=0;i<4;i++)
printf(" %x ",utf[i]);
return 0; }
一般一个文件的开头会有标志,通过十六进制编辑文件,便可以看到
EF BB BF 表示utf-8
FE FF 表示utf-16大端(大开头,比如a=00 61)
FF FE 表示utf-16小端(小开头,比如a=61 00)
没有前缀 表示ANSI格式
2.所以文件格式不同,执行的结果也不同
2.1我们下面代码为例:
#include <stdio.h>
int main(int argc,char **argv)
{
int i=0;
unsigned char s[]="abc中"; while(s[i])
{
printf("%02x ",s[i]);
i++;
}
printf("\n");
return 0;
}
然后在PC上,另存为ANSI.c和UTF-8.c,编码分别选择ANSI(GBK编码)和UTF-8
2.2然后拖到linux里编译运行:
gcc -o ANSI ANSI.c
gcc -o UTF-8 UTF-8.c

3.如何解决文件格式不同,编码也不同的问题?
我们可以指定字符集(charset), 强制使它以什么编码格式解析
man gcc //查看gcc使用手册
/charset //搜索charset相关字
找到:
-finput-charset=charset //表示源文件的编码方式, 默认以UTF-8来解析
-fexec-charset=charset //表示可执行程序里的字时候以什么编码方式来表示,默认是UTF-8
3.1指定字符集(charset)
gcc -finput-charset=GBK -fexec-charset=UTF-8 -o utf-8_2 ANSI.c

如上图所示,通过参数,告诉gcc该文件是GBK编码,需要转换为UTF-8编码后,再编译,便解决了文件格式问题.
最新文章
- [原]那些年整理的Linux常用命令,简单明了
- 2013ACM/ICPC亚洲区南京站现场赛---Poor Warehouse Keeper(贪心)
- time
- Javascript基础系列之(六)循环语句(for循环)
- css中的id和css的区别
- mac 下安装nginx
- 手机相机ISO是什么
- 无线通信技术协议-Zigbee 3.0
- 认识元数据和IL(下)<第五篇>
- PHP学习笔记十【数组】
- linux下多进程的调试
- 用JAVA中BufferedImage画出漂亮的验证码点击变化
- DRF 缓存解决方案 drf-extensions / redis
- studio-3t-x64 下载地址
- Maven学习(一)概念简述和安装教程
- Atitti opencv2.4 实现的人脸检测 attilax总结
- 读取Linux上图片
- logstash.conf 根据不同地址创建索引
- hduoj----(1033)Edge
- Java 前台后台数据传递、中文乱码解决方法