0-4评价一个语言模型Evaluating Language Models:Perplexity
有了一个语言模型,就要判断这个模型的好坏。
现在假设:
- 我们有一些测试数据,test data.测试数据中有m个句子;s1,s2,s3…,sm
我们可以查看在某个模型下面的概率: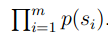
我们也知道,如果计算相乘是非常麻烦的,可以在此基础上,以另一种形式来计算模型的好坏程度。
在相乘的基础上,运用Log,来把乘法转换成加法来计算。
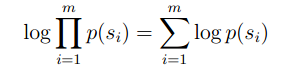
补充一下,在这里的p(Si)其实就等于我们前面所介绍的q(the|*,*)*q(dog|*,the)*q(…)…
有了上面的式子,评价一个模型是否好坏的原理在于:
a good model should assign as high probability as possible to these test data sentences.
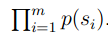 ,this value as being a measure of how well the alleviate to make sth less painful or difficult to deal with language model predict these test data sentences.
,this value as being a measure of how well the alleviate to make sth less painful or difficult to deal with language model predict these test data sentences.
The higher the better.
上面的意思也就是说,如果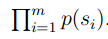 的值越大,那么这个模型就越好。
的值越大,那么这个模型就越好。
- 实际上,普遍的评价的指标是perplexity

其中,M的值是测试数据test data中的所有的数量。
那么从公式当中查看,可以知道。perplexity的值越小越好。
为了更好的理解perplexity,看下面这个例子:
- 我们现在有一个单词集V,N=|V|+1
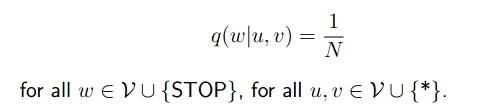
有了上面的条件,可以很容易的计算出:
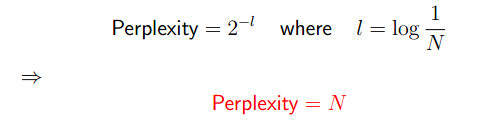
Perplexity是测试branching factor的数值。
branching factor又是什么呢?有的翻译为分叉率。如果branching factor高,计算起来代价会越大。也可以理解成,分叉率越高,可能性就越多,需要计算的量就越大。
上面的例子q=1/N只是一个举例,再看看下面这些真实的数据:
- Goodman的结果,其中|V|=50000,在trigram model的
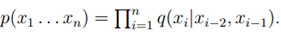 中,Perplexity=74
中,Perplexity=74 - 在bigram model中,
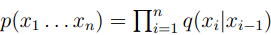 ,Perplexity=137
,Perplexity=137 - 在unigram model中,
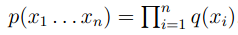 ,perplexity=955
,perplexity=955
在这里也看到了,几个模型的perplexity的值是不同的,这也就表明了三元模型一般是性能良好的。
最新文章
- SalesForce 记录级别安全性
- C#字符串默认值
- PHP 查询时区与设置时区
- Linux_服务
- 安装CDH4 (Cloudera Distribution Hadoop)步骤
- 【spring 7】spring和Hibernate的整合:声明式事务
- LINQ——语言级集成查询入门指南(1)
- shell脚本定时备份数据库
- mongodb副本集自动切换修复节点解决方案
- 从MSSQL server 2005中移植数据到Oracle 10g
- 使用fliter实现ie下css中rgba的效果
- seo优化做起来不是哪么简单,其实需要的是思维
- printf打印输出
- Word Ladder II leetcode java
- oracle 字符集 AL32UTF8、UTF8
- lombok 的使用
- PAT——1069. 微博转发抽奖
- 小白初识 - 基数排序(RadixSort)
- string的内存本质
- DG日志不应用,GAP,主备切换解决思路与办法