【开发笔记】- MySQL中limit查询超级慢,怎么办?
2024-10-20 02:58:56
有如下解决方法:
(1)、通过判断id的范围来分页
select id,LOG_CREATE_TIME,LOG_OPERATED_TYPE from LOG where id>5000000 limit 10;
也得到了分页的数据,但是我们发现如果id不是顺序的,也就是如果有数据删除过的话,那么这样分页数据就会不正确,这个是有缺陷的。
(2)、通过between and 代替limit(前提:知道具体的位置)
(3)、通过连接查询来分页
我们可以先查询500w条数据开始分页的那10个id,然后通过连接查询显示数据
select id,LOG_CREATE_TIME,LOG_OPERATED_TYPE from LOG inner join(select id from LOG limit 5000000,10)as lim using(id);
优化分页查询的一个最简单的方法就是尽可能地使用索引覆盖扫描,而不是查询所有的列。然后根据需要做一次关联操作再返回所需的列。对于偏移量很大的时候,这样做的效率会提升非常大。
例如,有如下查询:
select id,LOG_WHO,LOG_CREATE_TIME,LOG_OPERATED_TYPE from LOG order by LOG_CREATE_TIME limit 5000000,10;
注:LOG_CREATE_TIME有一个btree索引
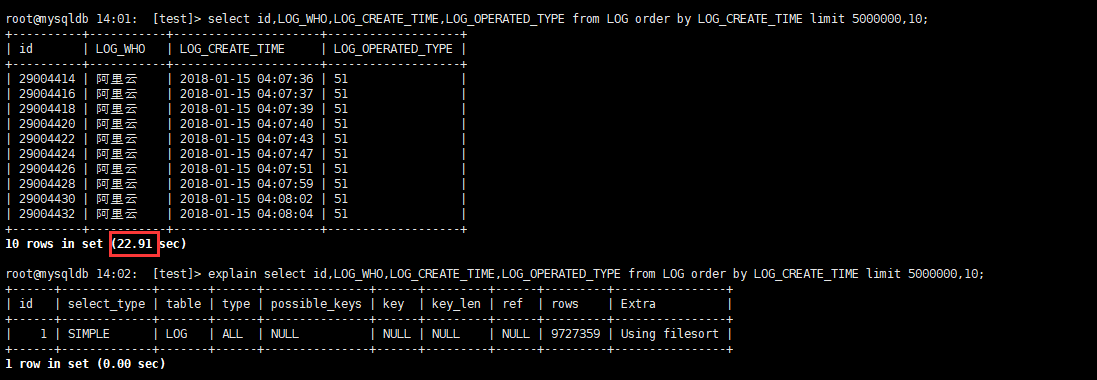
改写后的性能:
select id,LOG_WHO,LOG_CREATE_TIME,LOG_OPERATED_TYPE from LOG inner join(select id from LOG order by LOG_CREATE_TIME limit 5000000,10)as lim using(id);

这里的“延迟关联”将大大提升查询效率,它让mysql扫描尽可能少的页面,获取需要访问的记录后在根据关联列回原表查询需要的所有列,这个技术也可以用于优化关联查询中的limit子句。
最新文章
- Git从码云Clone代码到本地
- JAVA基础研究
- SVN :This XML file does not appear to have any style information associated with it.
- 斯坦福大学 iOS 7应用开发 ppt
- 通过外部接口 根据ip获取城市名
- linux下 yum源、rpm、源代码安装mysql
- deque,list,queue,priority_queue
- jquery 基础变量定义
- Go_Hello word
- hanjiaqi
- .NET Core Community 第三个千星项目诞生:爬虫 DotnetSpider
- 第十四篇-ImageButton控制聚焦,单击,常态三种状态的显示背景
- 第一节,windows和ubuntu下深度学习theano环境搭建
- SDL 库 无法解析的外部符号 __imp__fprintf
- Shiro笔记(二)Shiro集成SpringMVC的环境配置
- (代码篇)从基础文件IO说起虚拟内存,内存文件映射,零拷贝
- C#可空类型(转载)
- easyui汉化啊!
- Python3安装pywin32模块
- HDU 6044 Limited Permutation(搜索+读入优化)