浅谈HtmlParser
使用Heritrix抓取到自己所需的网页后,还需要对网页中的内容进行分类等操作,这个时候就需要用到htmlparser,但是使用htmlparser并不是那么容易!因为相关的文档比较少,很多更能需要开发者自己去摸索,去发掘!
不过这里给大家提供一个比较好的网站(htmlparser的API):http://tool.oschina.net/apidocs/apidoc?api=HTMLParser,这个API是英文版的,英语不好的这时就要逼迫自己看下去了。
HTMLParser的核心模块是org.htmlparser.Parser类,这个类实际完成了对于HTML页面的分析工作。这个类有下面几个构造函数:
public Parser ();
public Parser (Lexer lexer, ParserFeedback fb);
public Parser (URLConnection connection, ParserFeedback fb) throws ParserException;
public Parser (String resource, ParserFeedback feedback) throws ParserException;
public Parser (String resource) throws ParserException;
public Parser (Lexer lexer);
public Parser (URLConnection connection) throws ParserException;
和一个静态类
public static Parser createParser (String html, String charset);
对于大多数使用者来说,使用最多的是通过一个URLConnection或者一个保存有网页内容的字符串来初始化Parser,或者使用静态函数来生成一个Parser对象。ParserFeedback的代码很简单,是针对调试和跟踪分析过程的,一般不需要改变。而使用Lexer则是一个相对比较高级的话题,放到以后再讨论吧。
这里比较有趣的一点是,如果需要设置页面的编码方式的话,不使用Lexer就只有静态函数一个方法了。对于大多数中文页面来说,好像这是应该用得比较多的一个方法。
下面是初始化Parser的例子(通过打开一个网页的URL,中间的OpenFile方法是在打开一个本地的html文件时使用的)。
【加载的网页文件:index.html】
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<head>
<meta http-equiv = "Content-Type" content = "text/html; charset = utf-8"/>
<title>百度</title>
<link href = "a_1.css" rel = "stylesheet" type = "text/css"/>
</head>
<body>
<div align = "center" class = "photo" >
<img src = "../image/baidu.PNG" >
</div>
<div align = "center" class = "body">
<table cellpadding="8">
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">新闻</a>
</td>
<td>
<font color = "black">网页</font>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">贴吧</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">知道</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">音乐</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">图片</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">视频</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">地图</a>
</td>
</table>
<input class = "input" >
</div>
</body> </html>
【源码:htmlparser_1.java】
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.htmlparser.Parser;
import org.htmlparser.visitors.TextExtractingVisitor; public class Main {
private static String ENCODE = "GBK";
private static void message(String msg) {
// TODO Auto-generated method stub
try {
System.out.println(new String(msg.getBytes(ENCODE), System
.getProperty("file.encoding")));
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
} /*
* 打开一个文件
*/
public static String OpenFile(String FileName) {
try {
File mFile = new File(FileName);
FileInputStream mFileInputStream = new FileInputStream(mFile);
InputStreamReader mInputStreamReader = new InputStreamReader(
mFileInputStream, ENCODE);
BufferedReader mBufferedReader = new BufferedReader(
mInputStreamReader);
String mContent = "";
String mTemp = "";
while ((mTemp = mBufferedReader.readLine()) != null) {
mContent += mTemp + "\n";
}
mBufferedReader.close();
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return "";
}
return FileName;
} /*
* main方法
*/
public static void main(String[] args) {
// String mContent=OpenFile("");
try {
Parser mParser = new Parser((HttpURLConnection) (new URL(
"http://127.0.0.1/HtmlParser/index.html")).openConnection());
TextExtractingVisitor mExtractingVisitor = new TextExtractingVisitor();
mParser.visitAllNodesWith(mExtractingVisitor);
String textInPage = mExtractingVisitor.getExtractedText();
message(textInPage);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
} }
测试输出结果:
百度
新闻
网页
贴吧
知道
音乐
图片
视频
地图
HTMLParser将解析过的信息保存为一个树的结构。Node是信息保存的数据类型基础。
请看Node的定义:
public interface Node extends Cloneable;
Node中包含的方法有几类:
对于树型结构进行遍历的函数,这些函数最容易理解:
Node getParent ():取得父节点
NodeList getChildren ():取得子节点的列表
Node getFirstChild ():取得第一个子节点
Node getLastChild ():取得最后一个子节点
Node getPreviousSibling ():取得前一个兄弟(不好意思,英文是兄弟姐妹,直译太麻烦而且不符合习惯,对不起女同胞了)
Node getNextSibling ():取得下一个兄弟节点
取得Node内容的函数:
String getText ():取得文本
String toPlainTextString():取得纯文本信息。
String toHtml () :取得HTML信息(原始HTML)
String toHtml (boolean verbatim):取得HTML信息(原始HTML)
String toString ():取得字符串信息(原始HTML)
Page getPage ():取得这个Node对应的Page对象
int getStartPosition ():取得这个Node在HTML页面中的起始位置
int getEndPosition ():取得这个Node在HTML页面中的结束位置
用于Filter过滤的函数:
void collectInto (NodeList list, NodeFilter filter):基于filter的条件对于这个节点进行过滤,符合条件的节点放到list中。
用于Visitor遍历的函数:
void accept (NodeVisitor visitor):对这个Node应用visitor
用于修改内容的函数,这类用得比较少:
void setPage (Page page):设置这个Node对应的Page对象
void setText (String text):设置文本
void setChildren (NodeList children):设置子节点列表
其他函数:
void doSemanticAction (): 执行这个Node对应的操作(只有少数Tag有对应的操作)
Object clone (): 接口Clone的抽象函数。
实际我们用HTMLParser最多的是处理HTML页面,Filter或Visitor相关的函数是必须的,然后第一类和第二类函数是用得最多的。第一类函数比较容易理解,下面用例子说明一下第二类函数。
【源码:htmlparser_2.java】
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.htmlparser.Node;
import org.htmlparser.Parser;
import org.htmlparser.util.NodeIterator;
import org.htmlparser.visitors.TextExtractingVisitor;
import org.omg.CosNaming.NamingContextPackage.NotEmpty; public class Main {
private static String ENCODE = "utf-8";
private static void message(String msg) {
// TODO Auto-generated method stub
try {
System.out.println(new String(msg.getBytes(ENCODE), System
.getProperty("file.encoding")));
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
} /*
* 打开一个文件
*/
public static String OpenFile(String FileName) {
try {
File mFile = new File(FileName);
FileInputStream mFileInputStream = new FileInputStream(mFile);
InputStreamReader mInputStreamReader = new InputStreamReader(
mFileInputStream, ENCODE);
BufferedReader mBufferedReader = new BufferedReader(
mInputStreamReader);
String mContent = "";
String mTemp = "";
while ((mTemp = mBufferedReader.readLine()) != null) {
mContent += mTemp + "\n";
}
mBufferedReader.close();
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return "";
}
return FileName;
} /*
* main方法
*/
public static void main(String[] args) {
// String mContent=OpenFile("");
try {
Parser mParser = new Parser((HttpURLConnection) (new URL(
"http://127.0.0.1/HtmlParser/index.html")).openConnection());
// TextExtractingVisitor mExtractingVisitor = new TextExtractingVisitor();
// mParser.visitAllNodesWith(mExtractingVisitor);
// String textInPage = mExtractingVisitor.getExtractedText();
// message(textInPage); for (NodeIterator i = mParser.elements(); i.hasMoreNodes();) {
Node node = i.nextNode();
message("getText:"+node.getText());
message("getPlainText:"+node.toPlainTextString());
message("toHtml:"+node.toHtml());
message("toHtml(true):"+node.toHtml(true));
message("tohtml(false):"+node.toHtml(false));
message("toString:"+node.toString());
message("==============================");
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
}
测试输出结果:
getText:!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
getPlainText:
toHtml:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
toHtml(true):<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
tohtml(false):<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
toString:Doctype Tag : !DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd; begins at : 0; ends at : 121
==============================
getText: getPlainText: toHtml: toHtml(true): tohtml(false): toString:Txt (121[0,121],123[1,0]): \n
==============================
getText:html
getPlainText: 百度 新闻 网页 贴吧 知道 音乐 图片 视频 地图 toHtml:<html>
<head>
<meta http-equiv = "Content-Type" content = "text/html; charset = utf-8"/>
<title>百度</title>
<link href = "a_1.css" rel = "stylesheet" type = "text/css"/>
</head>
<body>
<div align = "center" class = "photo" >
<img src = "../image/baidu.PNG" >
</div>
<div align = "center" class = "body">
<table cellpadding="8">
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">新闻</a>
</td>
<td>
<font color = "black">网页</font>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">贴吧</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">知道</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">音乐</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">图片</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">视频</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">地图</a>
</td>
</table>
<input class = "input" >
</div>
</body> </html>
toHtml(true):<html>
<head>
<meta http-equiv = "Content-Type" content = "text/html; charset = utf-8"/>
<title>百度</title>
<link href = "a_1.css" rel = "stylesheet" type = "text/css"/>
</head>
<body>
<div align = "center" class = "photo" >
<img src = "../image/baidu.PNG" >
</div>
<div align = "center" class = "body">
<table cellpadding="8">
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">新闻</a>
</td>
<td>
<font color = "black">网页</font>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">贴吧</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">知道</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">音乐</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">图片</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">视频</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">地图</a>
</td>
</table>
<input class = "input" >
</div>
</body> </html>
tohtml(false):<html>
<head>
<meta http-equiv = "Content-Type" content = "text/html; charset = utf-8"/>
<title>百度</title>
<link href = "a_1.css" rel = "stylesheet" type = "text/css"/>
</head>
<body>
<div align = "center" class = "photo" >
<img src = "../image/baidu.PNG" >
</div>
<div align = "center" class = "body">
<table cellpadding="8">
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">新闻</a>
</td>
<td>
<font color = "black">网页</font>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">贴吧</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">知道</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">音乐</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">图片</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">视频</a>
</td>
<td>
<a href = "#" target = _blank title = "欢迎来到
百度网站">地图</a>
</td>
</table>
<input class = "input" >
</div>
</body> </html>
toString:Tag (123[1,0],129[1,6]): html
Txt (129[1,6],132[2,1]): \n\t
Tag (132[2,1],138[2,7]): head
Txt (138[2,7],142[3,2]): \n\t\t
Tag (142[3,2],216[3,76]): meta http-equiv = "Content-Type" content = "text/ht...
Txt (216[3,76],220[4,2]): \n\t\t
Tag (220[4,2],227[4,9]): title
Txt (227[4,9],229[4,11]): 百度
End (229[4,11],237[4,19]): /title
Txt (237[4,19],241[5,2]): \n\t\t
Tag (241[5,2],302[5,63]): link href = "a_1.css" rel = "stylesheet" type = "te...
Txt (302[5,63],305[6,1]): \n\t
End (305[6,1],312[6,8]): /head
Txt (312[6,8],315[7,1]): \n\t
Tag (315[7,1],321[7,7]): body
Txt (321[7,7],325[8,2]): \n\t\t
Tag (325[8,2],365[8,42]): div align = "center" class = "photo"
Txt (365[8,42],370[9,3]): \n\t\t\t
Tag (370[9,3],403[9,36]): img src = "../image/baidu.PNG"
Txt (403[9,36],407[10,2]): \n\t\t
End (407[10,2],413[10,8]): /div
Txt (413[10,8],417[11,2]): \n\t\t
Tag (417[11,2],454[11,39]): div align = "center" class = "body"
Txt (454[11,39],459[12,3]): \n\t\t\t
Tag (459[12,3],482[12,26]): table cellpadding="8"
Txt (482[12,26],488[13,4]): \n\t\t\t\t
Tag (488[13,4],492[13,8]): td
Txt (492[13,8],499[14,5]): \n\t\t\t\t\t
Tag (499[14,5],552[14,58]): a href = "#" target = _blank title = "欢迎来到
百度网站"
Txt (552[14,58],554[14,60]): 新闻
End (554[14,60],558[14,64]): /a
Txt (558[14,64],564[15,4]): \n\t\t\t\t
End (564[15,4],569[15,9]): /td
Txt (569[15,9],575[16,4]): \n\t\t\t\t
Tag (575[16,4],579[16,8]): td
Txt (579[16,8],586[17,5]): \n\t\t\t\t\t
Tag (586[17,5],608[17,27]): font color = "black"
Txt (608[17,27],610[17,29]): 网页
End (610[17,29],617[17,36]): /font
Txt (617[17,36],623[18,4]): \n\t\t\t\t
End (623[18,4],628[18,9]): /td
Txt (628[18,9],634[19,4]): \n\t\t\t\t
Tag (634[19,4],638[19,8]): td
Txt (638[19,8],645[20,5]): \n\t\t\t\t\t
Tag (645[20,5],698[20,58]): a href = "#" target = _blank title = "欢迎来到
百度网站"
Txt (698[20,58],700[20,60]): 贴吧
End (700[20,60],704[20,64]): /a
Txt (704[20,64],710[21,4]): \n\t\t\t\t
End (710[21,4],715[21,9]): /td
Txt (715[21,9],721[22,4]): \n\t\t\t\t
Tag (721[22,4],725[22,8]): td
Txt (725[22,8],732[23,5]): \n\t\t\t\t\t
Tag (732[23,5],785[23,58]): a href = "#" target = _blank title = "欢迎来到
百度网站"
Txt (785[23,58],787[23,60]): 知道
End (787[23,60],791[23,64]): /a
Txt (791[23,64],797[24,4]): \n\t\t\t\t
End (797[24,4],802[24,9]): /td
Txt (802[24,9],808[25,4]): \n\t\t\t\t
Tag (808[25,4],812[25,8]): td
Txt (812[25,8],819[26,5]): \n\t\t\t\t\t
Tag (819[26,5],872[26,58]): a href = "#" target = _blank title = "欢迎来到
百度网站"
Txt (872[26,58],874[26,60]): 音乐
End (874[26,60],878[26,64]): /a
Txt (878[26,64],884[27,4]): \n\t\t\t\t
End (884[27,4],889[27,9]): /td
Txt (889[27,9],895[28,4]): \n\t\t\t\t
Tag (895[28,4],899[28,8]): td
Txt (899[28,8],906[29,5]): \n\t\t\t\t\t
Tag (906[29,5],959[29,58]): a href = "#" target = _blank title = "欢迎来到
百度网站"
Txt (959[29,58],961[29,60]): 图片
End (961[29,60],965[29,64]): /a
Txt (965[29,64],971[30,4]): \n\t\t\t\t
End (971[30,4],976[30,9]): /td
Txt (976[30,9],982[31,4]): \n\t\t\t\t
Tag (982[31,4],986[31,8]): td
Txt (986[31,8],993[32,5]): \n\t\t\t\t\t
Tag (993[32,5],1046[32,58]): a href = "#" target = _blank title = "欢迎来到
百度网站"
Txt (1046[32,58],1048[32,60]): 视频
End (1048[32,60],1052[32,64]): /a
Txt (1052[32,64],1058[33,4]): \n\t\t\t\t
End (1058[33,4],1063[33,9]): /td
Txt (1063[33,9],1069[34,4]): \n\t\t\t\t
Tag (1069[34,4],1073[34,8]): td
Txt (1073[34,8],1080[35,5]): \n\t\t\t\t\t
Tag (1080[35,5],1133[35,58]): a href = "#" target = _blank title = "欢迎来到
百...
Txt (1133[35,58],1135[35,60]): 地图
End (1135[35,60],1139[35,64]): /a
Txt (1139[35,64],1145[36,4]): \n\t\t\t\t
End (1145[36,4],1150[36,9]): /td
Txt (1150[36,9],1155[37,3]): \n\t\t\t
End (1155[37,3],1163[37,11]): /table
Txt (1163[37,11],1168[38,3]): \n\t\t\t
Tag (1168[38,3],1192[38,27]): input class = "input"
Txt (1192[38,27],1196[39,2]): \n\t\t
End (1196[39,2],1202[39,8]): /div
Txt (1202[39,8],1205[40,1]): \n\t
End (1205[40,1],1212[40,8]): /body
Txt (1212[40,8],1216[42,0]): \n\n
End (1216[42,0],1223[42,7]): /html ==============================
对于第一个Node的内容,对应的就是第一行<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">,从这个输出结果中,也可以看出内容的树状结构。或者说是树林结构。在Page内容的第一层Tag,如DOCTYPE,head和html,分别形成了一个最高层的Node节点(很多人可能对第二个和第四个Node的内容有点奇怪。实际上这两个Node就是两个换行符号。HTMLParser把HTML页面内容中的所有换行,空格,Tab等都转换成了相应的Tag,所以就出现了这样的Node。虽然内容少但是级别高,呵呵)
getPlainTextString是把用户可以看到的内容都包含了。有趣的有两点,一是<head>标签中的Title内容是在plainText中的,可能在标题中可见的也算可见吧。另外就是象前面说的,HTML内容中的换行符什么的,也都成了plainText,这个逻辑上好像有点问题。
另外可能大家发现toHtml,toHtml(true)和toHtml(false)的结果没什么区别。实际也是这样的,如果跟踪HTMLParser的代码就可以发现,Node的子类是AbstractNode,其中实现了toHtml()的代码,直接调用toHtml(false),而AbstractNode的三个子类RemarkNode,TagNode和TextNode中,toHtml(boolean verbatim)的实现中,都没有处理verbatim参数,所以三个函数的结果是一模一样的。如果你不需要实现你自己的什么特殊处理,简单使用toHtml就可以了。
HTML的Node类继承关系如下图(这个是从别的文章Copy的)
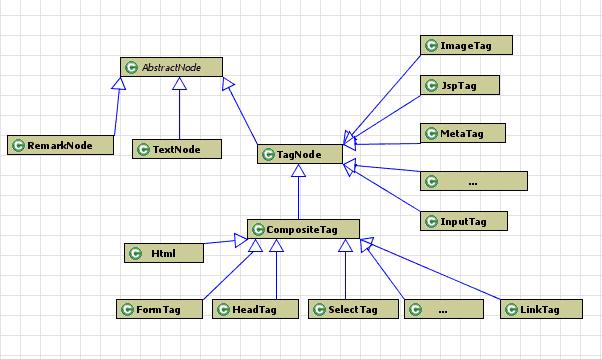
他被组织成三棵树的森林,其中以<html>标签为根节点的树高度最大,网页的树状结构图如下:

html树中要特别注意的是每一个回车换行,HTMLParser会将他们看做一个节点处理。
AbstractNodes是Node的直接子类,也是一个抽象类。它的三个直接子类实现是RemarkNode,用于保存注释。在输出结果的toString部分中可以看到有一个"Rem (345[6,2],356[6,13]): 这是注释",就是一个RemarkNode。TextNode也很简单,就是用户可见的文字信息。TagNode是最复杂的,包含了HTML语言中的所有标签,而且可以扩展(扩展 HTMLParser 对自定义标签的处理能力)。TagNode包含两类,一类是简单的Tag,实际就是不能包含其他Tag的标签,只能做叶子节点。另一类是CompositeTag,就是可以包含其他Tag,是分支节点
HTMLParser遍历了网页的内容以后,以树(森林)结构保存了结果。HTMLParser访问结果内容的方法有两种。使用Filter和使用Visitor。
(一)Filter类
顾名思义,Filter就是对于结果进行过滤,取得需要的内容。HTMLParser在org.htmlparser.filters包之内一共定义了16个不同的Filter,也可以分为几类。
判断类Filter:
TagNameFilter
HasAttributeFilter
HasChildFilter
HasParentFilter
HasSiblingFilter
IsEqualFilter
逻辑运算Filter:
AndFilter
NotFilter
OrFilter
XorFilter
其他Filter:
NodeClassFilter
StringFilter
LinkStringFilter
LinkRegexFilter
RegexFilter
CssSelectorNodeFilter
所有的Filter类都实现了org.htmlparser.NodeFilter接口。这个接口只有一个主要函数:boolean accept (Node node);
各个子类分别实现这个函数,用于判断输入的Node是否符合这个Filter的过滤条件,如果符合,返回true,否则返回false。
(二)判断类Filter
2.1 TagNameFilter
TabNameFilter是最容易理解的一个Filter,根据Tag的名字进行过滤。
【源码:htmlparser_3.java】(此处只给出main方法的代码,其余代码同上)
/*
* main方法
*/
public static void main(String[] args) {
// String mContent=OpenFile("");
try {
Parser mParser = new Parser((HttpURLConnection) (new URL(
"http://127.0.0.1/HtmlParser/index.html")).openConnection()); // TextExtractingVisitor mExtractingVisitor = new TextExtractingVisitor();
// mParser.visitAllNodesWith(mExtractingVisitor);
// String textInPage = mExtractingVisitor.getExtractedText();
// message(textInPage); // for (NodeIterator i = mParser.elements(); i.hasMoreNodes();) {
// Node node = i.nextNode();
// message("getText:"+node.getText());
// message("getPlainText:"+node.toPlainTextString());
// message("toHtml:"+node.toHtml());
// message("toHtml(true):"+node.toHtml(true));
// message("tohtml(false):"+node.toHtml(false));
// message("toString:"+node.toString());
// message("==============================");
// } NodeFilter mNodeFilter = new TagNameFilter("DIV");
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
if (mNodeFilter!=null) {
for (int i = 0; i < mNodeList.size(); i++) {
Node textNode = (Node)mNodeList.elementAt(i);
message("getText:"+textNode.getText());
message("===================================");
}
} } catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
测试输出结果:
getText:div align = "center" class = "photo"
===================================
getText:div align = "center" class = "body"
===================================
可以看出文件中两个Div节点都被取出了。下面可以针对这两个DIV节点进行操作。
2.2 HasChildFilter
下面让我们看看HasChildFilter。刚刚看到这个Filter的时候,我想当然地认为这个Filter返回的是有Child的Tag。直接初始化了一个
NodeFilter filter = new HasChildFilter();
结果调用NodeList nodes = parser.extractAllNodesThatMatch(filter);的时候HasChildFilter内部直接发生NullPointerException。读了一下HasChildFilter的代码,才发现,实际HasChildFilter是返回有符合条件的子节点的节点,需要另外一个Filter作为过滤子节点的参数。缺省的构造函数虽然可以初始化,但是由于子节点的Filter是null,所以使用的时候发生了Exception。从这点来看,HTMLParser的代码还有很多可以优化的的地方。呵呵。
修改代码:
/*
* main方法
*/
public static void main(String[] args) {
// String mContent=OpenFile("");
try {
Parser mParser = new Parser((HttpURLConnection) (new URL(
"http://127.0.0.1/HtmlParser/index.html")).openConnection());
NodeFilter mInnerFilter = new TagNameFilter("DIV");
NodeFilter mNodeFilter = new HasChildFilter(mInnerFilter);
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
if (mNodeFilter!=null) {
for (int i = 0; i < mNodeList.size(); i++) {
Node textNode = (Node)mNodeList.elementAt(i);
message("getText:"+textNode.getText());
message("===================================");
}
} } catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
测试输出结果:
getText:body
===================================
在此处可以看到,输出的是含有DIV子Tag的Tag节点。(body有子节点DIV“<div align = "center" class = "photo" >”)
注意HasChildFilter还有一个构造函数:public HasChildFilter (NodeFilter filter, boolean recursive)
如果recursive是false,则只对第一级子节点进行过滤。比如前面的例子,body在第一级的子节点里就有DIV节点,所以匹配上了。如果我们用下面的方法调用:
NodeFilter filter = new HasChildFilter( innerFilter, true );
测试输出结果:
getText:html
===================================
getText:body
===================================
可以看到输出结果中多了一个html ,这个是整个HTML页面的节点(根节点),虽然这个节点下直接没有DIV节点,但是它的子节点body下面有DIV节点,所以它也被匹配上了。
2.3 HasAttributeFilter
HasAttributeFilter有3个构造函数:
public HasAttributeFilter ();
public HasAttributeFilter (String attribute);
public HasAttributeFilter (String attribute, String value);
这个Filter可以匹配出包含制定名字的属性,或者制定属性为指定值的节点。还是用例子说明比较容易。
调用方法1:
NodeFilter mNodeFilter = new HasAttributeFilter();
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
输出结果:
什么也没有输出
调用方法2:
NodeFilter mNodeFilter = new HasAttributeFilter("class");
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
输出结果:
getText:div align = "center" class = "photo"
===================================
getText:div align = "center" class = "body"
===================================
getText:input class = "input"
===================================
调用方法3:
NodeFilter mNodeFilter = new HasAttributeFilter("class","photo");
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
输出结果:
getText:div align = "center" class = "photo"
===================================
2.4 其他判断列Filter
HasParentFilter和HasSiblingFilter的功能与HasChildFilter类似,大家自己试一下就应该了解了。
IsEqualFilter的构造函数参数是一个Node:
public IsEqualFilter (Node node) {
mNode = node;
}
accept函数也很简单:
public boolean accept (Node node) {
return (mNode == node);
}
不需要过多说明了。
(三)逻辑运算Filter
前面介绍的都是简单的Filter,只能针对某种单一类型的条件进行过滤。HTMLParser支持对于简单类型的Filter进行组合,从而实现复杂的条件。原理和一般编程语言的逻辑运算是一样的。
3.1 AndFilter
AndFilter可以把两种Filter进行组合,只有同时满足条件的Node才会被过滤。
测试代码:
NodeFilter mNodeFilterLeft = new HasAttributeFilter("class");
NodeFilter mNodeFilterRight = new HasAttributeFilter("align");
NodeFilter mNodeFilter = new AndFilter(mNodeFilterLeft, mNodeFilterRight);
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
测试输出结果:
getText:div align = "center" class = "photo"
===================================
getText:div align = "center" class = "body"
===================================
3.2 OrFilter
把前面的AndFilter换成OrFilter
测试代码:
NodeFilter mNodeFilterLeft = new HasAttributeFilter("class");
NodeFilter mNodeFilterRight = new HasAttributeFilter("align");
NodeFilter mNodeFilter = new OrFilter(mNodeFilterLeft, mNodeFilterRight);
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
测试输出结果:
getText:div align = "center" class = "photo"
===================================
getText:div align = "center" class = "body"
===================================
getText:input class = "input"
===================================
3.3 NotFilter
把前面的AndFilter换成NotFilter
测试代码:
NodeFilter mNodeFilterLeft = new HasAttributeFilter("class");
NodeFilter mNodeFilterRight = new HasAttributeFilter("align");
NodeFilter mNodeFilter = new NotFilter(new OrFilter(mNodeFilterLeft,mNodeFilterRight));
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
测试输出结果:
getText:!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
===================================
getText: ===================================
getText:html
===================================
getText: ===================================
getText:head
===================================
getText: ===================================
getText:meta http-equiv = "Content-Type" content = "text/html; charset = utf-8"/
===================================
getText: ===================================
getText:title
===================================
getText:百度
===================================
getText:/title
===================================
getText: ===================================
getText:link href = "a_1.css" rel = "stylesheet" type = "text/css"/
===================================
getText: ===================================
getText:/head
===================================
getText: ===================================
getText:body
===================================
getText: ===================================
getText: ===================================
getText:img src = "../image/baidu.PNG"
===================================
getText: ===================================
getText:/div
===================================
getText: ===================================
getText: ===================================
getText:table cellpadding="8"
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:a href = "#" target = _blank title = "欢迎来到
百度网站"
===================================
getText:新闻
===================================
getText:/a
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:font color = "black"
===================================
getText:网页
===================================
getText:/font
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:a href = "#" target = _blank title = "欢迎来到
百度网站"
===================================
getText:贴吧
===================================
getText:/a
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:a href = "#" target = _blank title = "欢迎来到
百度网站"
===================================
getText:知道
===================================
getText:/a
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:a href = "#" target = _blank title = "欢迎来到
百度网站"
===================================
getText:音乐
===================================
getText:/a
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:a href = "#" target = _blank title = "欢迎来到
百度网站"
===================================
getText:图片
===================================
getText:/a
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:a href = "#" target = _blank title = "欢迎来到
百度网站"
===================================
getText:视频
===================================
getText:/a
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:td
===================================
getText: ===================================
getText:a href = "#" target = _blank title = "欢迎来到
百度网站"
===================================
getText:地图
===================================
getText:/a
===================================
getText: ===================================
getText:/td
===================================
getText: ===================================
getText:/table
===================================
getText: ===================================
getText: ===================================
getText:/div
===================================
getText: ===================================
getText:/body
===================================
getText: ===================================
getText:/html
===================================
3.4 XorFilter(暂未实现)
把前面的AndFilter换成NotFilter
测试代码:……
测试输出结果:……
(四)其他Filter:
4.1 NodeClassFilter
这个Filter用于判断节点类型是否是某个特定的Node类型。在上面中我们已经了解了Node的不同类型,这个Filter就可以针对类型进行过滤。
测试代码:
测试输出结果:
4.2 StringFilter
这个Filter用于过滤显示字符串中包含制定内容的Tag。注意是可显示的字符串,不可显示的字符串中的内容(例如注释,链接等等)不会被显示。
测试代码:
NodeFilter mNodeFilter = new StringFilter("贴吧");
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
测试输出结果:
getText:贴吧
===================================
4.3 LinkStringFilter
这个Filter用于判断链接中是否包含某个特定的字符串,可以用来过滤出指向某个特定网站的链接。
测试代码:
NodeFilter mNodeFilter = new LinkStringFilter("http://tieba.baidu.com/");
NodeList mNodeList = mParser.extractAllNodesThatMatch(mNodeFilter);
测试输出结果:(此处需要修改html例子的代码,修改后为:【<a href = "http://tieba.baidu.com/" target = _blank title = "欢迎来到
百度网站">贴吧</a>】)
getText:a href = "http://tieba.baidu.com/" target = _blank title = "欢迎来到
百度网站"
===================================
4.4 其他几个Filter
其他几个Filter也是根据字符串对不同的域进行判断,与前面这些的区别主要就是支持正则表达式。这个不在本文的讨论范围以内,大家可以自己实验一下。
HTMLParser遍历了网页的内容以后,以树(森林)结构保存了结果。HTMLParser访问结果内容的方法有两种。使用Filter和使用Visitor。
下面介绍使用Visitor访问内容的方法。
5.1 NodeVisitor
从简单方面的理解,Filter是根据某种条件过滤取出需要的Node再进行处理。Visitor则是遍历内容树的每一个节点,对于符合条件的节点进行处理。实际的结果异曲同工,两种不同的方法可以达到相同的结果。
下面是一个最常见的NodeVisitro的例子。
测试代码:
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
Parser mParser = new Parser(
(HttpURLConnection) (new URL(
"http://127.0.0.1/HtmlParser/index.html"))
.openConnection());
NodeVisitor mNodeVisitor = new NodeVisitor(false, false) {
@Override
public void visitTag(Tag tag) {
// TODO Auto-generated method stub
message("This is Tag:" + tag.getText());
}
@Override
public void visitStringNode(Text string) {
// TODO Auto-generated method stub
message("This is Text:" + string);
}
@Override
public void visitRemarkNode(Remark remark) {
// TODO Auto-generated method stub
message("This is Remark:" + remark.getText());
}
@Override
public void beginParsing() {
// TODO Auto-generated method stub
message("begin Parsing");
}
@Override
public void visitEndTag(Tag tag) {
// TODO Auto-generated method stub
message("visitEndTag:" + tag.getText());
}
@Override
public void finishedParsing() {
// TODO Auto-generated method stub
message("finishedParsing!");
}
};
mParser.visitAllNodesWith(mNodeVisitor);
} catch (Exception e) {
// TODO: handle exception
}
}
测试输出结果:
begin Parsing
This is Tag:!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
This is Text:Txt (121[0,121],123[1,0]): \n
finishedParsing!
可以看到,开始遍历所以的节点以前,beginParsing先被调用,然后处理的是中间的Node,最后在结束遍历以前,finishParsing被调用。因为我设置的 recurseChildren和recurseSelf都是false,所以Visitor没有访问子节点也没有访问根节点的内容。中间输出的两个\n就是我们在前面初始化Parser 中讨论过的最高层的那两个换行。
我们先把recurseSelf设置成true,看看会发生什么。
NodeVisitor visitor = new NodeVisitor( false, true)
输出结果 :
begin Parsing
This is Tag:!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
This is Text:Txt (121[0,121],123[1,0]): \n
This is Tag:html
finishedParsing!
可以看到,HTML页面的第一层节点都被调用了。
我们再用下面的方法调用看看:
NodeVisitor mNodeVisitor = new NodeVisitor(true, false)
输出结果:
begin Parsing
This is Tag:!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
This is Text:Txt (121[0,121],123[1,0]): \n
This is Text:Txt (129[1,6],132[2,1]): \n\t
This is Text:Txt (138[2,7],142[3,2]): \n\t\t
This is Tag:meta http-equiv = "Content-Type" content = "text/html; charset = utf-8"/
This is Text:Txt (216[3,76],220[4,2]): \n\t\t
This is Remark:<title>百度</title>
This is Text:Txt (244[4,26],248[5,2]): \n\t\t
This is Tag:link href = "a_1.css" rel = "stylesheet" type = "text/css"/
This is Text:Txt (309[5,63],312[6,1]): \n\t
visitEndTag:/head
This is Text:Txt (319[6,8],322[7,1]): \n\t
This is Text:Txt (328[7,7],332[8,2]): \n\t\t
This is Text:Txt (372[8,42],377[9,3]): \n\t\t\t
This is Tag:img src = "../image/baidu.PNG"
This is Text:Txt (410[9,36],414[10,2]): \n\t\t
visitEndTag:/div
This is Text:Txt (420[10,8],424[11,2]): \n\t\t
This is Text:Txt (461[11,39],466[12,3]): \n\t\t\t
This is Text:Txt (489[12,26],495[13,4]): \n\t\t\t\t
This is Text:Txt (499[13,8],506[14,5]): \n\t\t\t\t\t
This is Text:Txt (559[14,58],561[14,60]): 新闻
visitEndTag:/a
This is Text:Txt (565[14,64],571[15,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (576[15,9],582[16,4]): \n\t\t\t\t
This is Text:Txt (586[16,8],593[17,5]): \n\t\t\t\t\t
This is Tag:font color = "black"
This is Text:Txt (615[17,27],617[17,29]): 网页
visitEndTag:/font
This is Text:Txt (624[17,36],630[18,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (635[18,9],641[19,4]): \n\t\t\t\t
This is Text:Txt (645[19,8],652[20,5]): \n\t\t\t\t\t
This is Text:Txt (727[20,80],729[20,82]): 贴吧
visitEndTag:/a
This is Text:Txt (733[20,86],739[21,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (744[21,9],750[22,4]): \n\t\t\t\t
This is Text:Txt (754[22,8],761[23,5]): \n\t\t\t\t\t
This is Text:Txt (814[23,58],816[23,60]): 知道
visitEndTag:/a
This is Text:Txt (820[23,64],826[24,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (831[24,9],837[25,4]): \n\t\t\t\t
This is Text:Txt (841[25,8],848[26,5]): \n\t\t\t\t\t
This is Text:Txt (901[26,58],903[26,60]): 音乐
visitEndTag:/a
This is Text:Txt (907[26,64],913[27,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (918[27,9],924[28,4]): \n\t\t\t\t
This is Text:Txt (928[28,8],935[29,5]): \n\t\t\t\t\t
This is Text:Txt (988[29,58],990[29,60]): 图片
visitEndTag:/a
This is Text:Txt (994[29,64],1000[30,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (1005[30,9],1011[31,4]): \n\t\t\t\t
This is Text:Txt (1015[31,8],1022[32,5]): \n\t\t\t\t\t
This is Text:Txt (1075[32,58],1077[32,60]): 视频
visitEndTag:/a
This is Text:Txt (1081[32,64],1087[33,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (1092[33,9],1098[34,4]): \n\t\t\t\t
This is Text:Txt (1102[34,8],1109[35,5]): \n\t\t\t\t\t
This is Text:Txt (1162[35,58],1164[35,60]): 地图
visitEndTag:/a
This is Text:Txt (1168[35,64],1174[36,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (1179[36,9],1184[37,3]): \n\t\t\t
visitEndTag:/table
This is Text:Txt (1192[37,11],1197[38,3]): \n\t\t\t
This is Tag:input class = "input"
This is Text:Txt (1221[38,27],1225[39,2]): \n\t\t
visitEndTag:/div
This is Text:Txt (1231[39,8],1234[40,1]): \n\t
visitEndTag:/body
This is Text:Txt (1241[40,8],1245[42,0]): \n\n
visitEndTag:/html
finishedParsing!
可以看到,所有的子节点都出现了,除了刚刚例子里面的两个最上层节点This is Tag:head和This is Tag:html xmlns="http://www.w3.org/1999/xhtml"。
想让它们都出来,只需要
NodeVisitor mNodeVisitor = new NodeVisitor(true, true)
输出结果:
begin Parsing
This is Tag:!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
This is Text:Txt (121[0,121],123[1,0]): \n
This is Tag:html
This is Text:Txt (129[1,6],132[2,1]): \n\t
This is Tag:head
This is Text:Txt (138[2,7],142[3,2]): \n\t\t
This is Tag:meta http-equiv = "Content-Type" content = "text/html; charset = utf-8"/
This is Text:Txt (216[3,76],220[4,2]): \n\t\t
This is Remark:<title>百度</title>
This is Text:Txt (244[4,26],248[5,2]): \n\t\t
This is Tag:link href = "a_1.css" rel = "stylesheet" type = "text/css"/
This is Text:Txt (309[5,63],312[6,1]): \n\t
visitEndTag:/head
This is Text:Txt (319[6,8],322[7,1]): \n\t
This is Tag:body
This is Text:Txt (328[7,7],332[8,2]): \n\t\t
This is Tag:div align = "center" class = "photo"
This is Text:Txt (372[8,42],377[9,3]): \n\t\t\t
This is Tag:img src = "../image/baidu.PNG"
This is Text:Txt (410[9,36],414[10,2]): \n\t\t
visitEndTag:/div
This is Text:Txt (420[10,8],424[11,2]): \n\t\t
This is Tag:div align = "center" class = "body"
This is Text:Txt (461[11,39],466[12,3]): \n\t\t\t
This is Tag:table cellpadding="8"
This is Text:Txt (489[12,26],495[13,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (499[13,8],506[14,5]): \n\t\t\t\t\t
This is Tag:a href = "#" target = _blank title = "欢迎来到
百度网站"
This is Text:Txt (559[14,58],561[14,60]): 新闻
visitEndTag:/a
This is Text:Txt (565[14,64],571[15,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (576[15,9],582[16,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (586[16,8],593[17,5]): \n\t\t\t\t\t
This is Tag:font color = "black"
This is Text:Txt (615[17,27],617[17,29]): 网页
visitEndTag:/font
This is Text:Txt (624[17,36],630[18,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (635[18,9],641[19,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (645[19,8],652[20,5]): \n\t\t\t\t\t
This is Tag:a href = "http://tieba.baidu.com/" target = _blank title = "欢迎来到
百度网站"
This is Text:Txt (727[20,80],729[20,82]): 贴吧
visitEndTag:/a
This is Text:Txt (733[20,86],739[21,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (744[21,9],750[22,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (754[22,8],761[23,5]): \n\t\t\t\t\t
This is Tag:a href = "#" target = _blank title = "欢迎来到
百度网站"
This is Text:Txt (814[23,58],816[23,60]): 知道
visitEndTag:/a
This is Text:Txt (820[23,64],826[24,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (831[24,9],837[25,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (841[25,8],848[26,5]): \n\t\t\t\t\t
This is Tag:a href = "#" target = _blank title = "欢迎来到
百度网站"
This is Text:Txt (901[26,58],903[26,60]): 音乐
visitEndTag:/a
This is Text:Txt (907[26,64],913[27,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (918[27,9],924[28,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (928[28,8],935[29,5]): \n\t\t\t\t\t
This is Tag:a href = "#" target = _blank title = "欢迎来到
百度网站"
This is Text:Txt (988[29,58],990[29,60]): 图片
visitEndTag:/a
This is Text:Txt (994[29,64],1000[30,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (1005[30,9],1011[31,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (1015[31,8],1022[32,5]): \n\t\t\t\t\t
This is Tag:a href = "#" target = _blank title = "欢迎来到
百度网站"
This is Text:Txt (1075[32,58],1077[32,60]): 视频
visitEndTag:/a
This is Text:Txt (1081[32,64],1087[33,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (1092[33,9],1098[34,4]): \n\t\t\t\t
This is Tag:td
This is Text:Txt (1102[34,8],1109[35,5]): \n\t\t\t\t\t
This is Tag:a href = "#" target = _blank title = "欢迎来到
百度网站"
This is Text:Txt (1162[35,58],1164[35,60]): 地图
visitEndTag:/a
This is Text:Txt (1168[35,64],1174[36,4]): \n\t\t\t\t
visitEndTag:/td
This is Text:Txt (1179[36,9],1184[37,3]): \n\t\t\t
visitEndTag:/table
This is Text:Txt (1192[37,11],1197[38,3]): \n\t\t\t
This is Tag:input class = "input"
This is Text:Txt (1221[38,27],1225[39,2]): \n\t\t
visitEndTag:/div
This is Text:Txt (1231[39,8],1234[40,1]): \n\t
visitEndTag:/body
This is Text:Txt (1241[40,8],1245[42,0]): \n\n
visitEndTag:/html
finishedParsing!
哈哈,这下调用清楚了,大家在需要处理的地方增加自己的代码好了。
5.2 其他Visitor
……
到此,个人感觉与htmlparser的缘分已尽!下一步,进军JSoup!!!
===========================参考网址===========================
http://www.blogjava.net/amigoxie/archive/2008/01/18/176200.html
http://www.cnblogs.com/loveyakamoz/archive/2011/07/27/2118937.html
http://blog.csdn.net/witsmakemen/article/details/8778979
===========================参考网址===========================
最新文章
- tomcat(二)--tomcat结构
- jQuery改变兄弟元素样式,及:not([class="allclassname"])筛选小结
- Verilog学习笔记基本语法篇(九)········ 任务和函数
- Webapp的display-name问题
- HDU 5351 MZL's Border (规律,大数)
- Linux下C编程通过宏定义打开和关闭调试信息
- C#同步SQL Server数据库中的数据--数据库同步工具[同步新数据]
- Timus 1180. Stone Game 游戏题目
- Java8学习(4)-Stream流
- tomcat启动报错:Address already in use: JVM_Bind
- 『集群』001 Slithice 服务器集群 概述
- docker镜像保存及导出(save,export)
- Redis学习之二 数据类型和相关命令
- 一种历史详细记录表,完整实现:CommonOperateLog 详细记录某用户、某时间、对某表、某主键、某字段的修改(新旧值
- thinkCMF----列表页跳转
- redis批量删除key 命令
- Ubuntu上搭建比特币运行环境
- Spring配置--tx事务配置方式
- 跨境B2B电商
- Word中划线的方法(五种)